本記事は生成AIと共同で執筆しています。事実関係は可能な範囲で公式ドキュメント等と照合していますが、誤りが含まれている可能性があります。重要な判断を行う前にご自身でも一次情報をご確認ください。
過去に画面収録のみでアップロードした、音声・字幕の無いツール操作デモ動画が手元のチャンネルに溜まっていました。9〜72秒の短尺で自動字幕も生成されない状態でした。視聴者が中身を把握しづらいので、画面のフレームから内容を推定して日本語字幕(SRT)を作り、YouTube Data API でまとめて追加する手順を整備したので備忘録としてまとめます。
YouTube Studio の UI で1本ずつ字幕を貼り付ける手順は別記事YouTube StudioでVTT字幕ファイルをアップロードする手順にまとめています。本記事は API + スクリプト + Claude Code(マルチモーダル)で複数動画を一括処理する寄りの内容です。
全体の流れ
[1. 対象動画の音声・字幕の現状を調査]
↓
[2. yt-dlp で動画をダウンロード]
↓
[3. ffmpeg でキーフレームを抽出 → コンタクトシートに集約]
↓
[4. Claude Code がコンタクトシート+対応記事を確認 → SRT原稿を作成]
↓
[5. YouTube Data API の captions.insert で SRT をアップロード]
ステップ 1〜2、5 は Python スクリプト、3 は ffmpeg、4 は Claude Code(画像入力)が担当します。
1. 対象動画の音声・字幕の現状を調査
字幕の有無は YouTube Data API の captions.list で取得できます。公開動画への読み取りであれば API キーだけで呼び出せます (今回もこの経路で 800本超を一括チェックしました)。OAuth で呼ぶ場合は youtube scope だと 403 を返すので、youtube.force-ssl scope のトークンが必要です (書き込み系の captions.insert / update / delete は scope 必須)。
音声の有無は yt-dlp のフォーマット情報だけでは判定できません。YouTube は無音動画にも音声トラックを付けて配信している場合があるためです。実際に音声を取得して ffmpeg の volumedetect フィルタで音量を計測する必要がありそうです。
# 音声を WAV としてダウンロード
subprocess.run(['yt-dlp', '-f', 'worstaudio/bestaudio', '-x', '--audio-format', 'wav',
'-o', f'{vid}.%(ext)s', f'https://youtu.be/{vid}'], check=True)
# 音量計測
out = subprocess.check_output(
['ffmpeg', '-i', f'{vid}.wav', '-af', 'volumedetect',
'-vn', '-sn', '-dn', '-f', 'null', '/dev/null'],
stderr=subprocess.STDOUT).decode()
# 出力中の "mean_volume: -X.X dB" "max_volume: -X.X dB" をパース
完全な無音であれば mean_volume max_volume ともに -91 dB 付近の値(実質的な底)になります。
2. 動画ダウンロードとコンタクトシート生成
字幕原稿の作成には動画の内容を視覚的に把握する必要があります。動画再生をコマで眺める代わりに、ffmpeg のタイル合成機能でキーフレームを1枚の画像に並べる「コンタクトシート」を作成します。
def make_sheet(video_path, sheet_path, dur: float):
n = max(4, min(12, int(dur) // 4)) # 動画尺に応じて4〜12枚
cols = 3
rows = (n + cols - 1) // cols
interval = max(1, int(dur) // n)
cmd = ['ffmpeg', '-y', '-i', video_path,
'-vf', f'fps=1/{interval},scale=480:-1,'
f'tile={cols}x{rows}:padding=4:color=white',
'-frames:v', '1', '-q:v', '2', sheet_path]
subprocess.run(cmd, check=True)
fps=1/N で N 秒に1枚のペースで抽出し、tile=3x? で3列のグリッドに並べています。padding と背景色を指定すると、後でフレームの境界が見やすくなります。ffprobe の duration は float なので、tile=3x3.0 のような指定が ffmpeg 側で Invalid argument になる場合があります。int(dur) で整数化するか、tile= に渡す前に int() で揃えておくと安全です。
生成されるコンタクトシートの例(Alfresco + Archivematica の AIP 作成デモ、34秒、9枚)です。
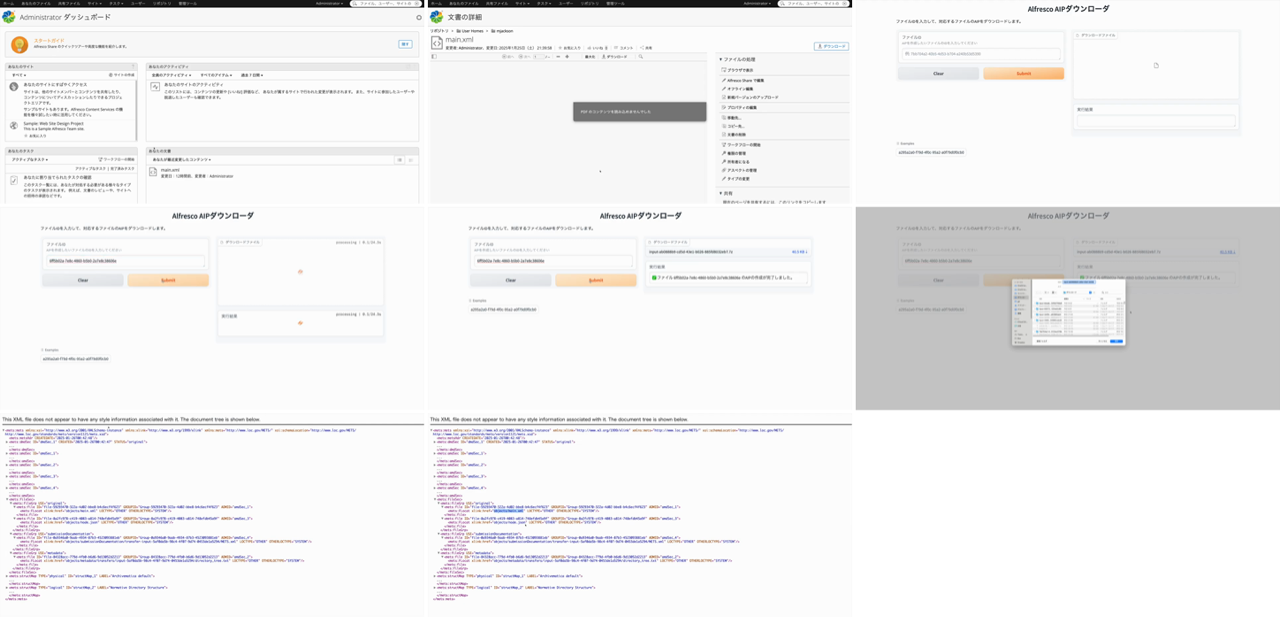
3. Claude Code でコンタクトシートを確認して SRT 原稿を作成
ここが本手順のポイントです。Claude Code は画像を直接入力できるため、コンタクトシートを Read させて画面で起きていることを把握させます。対応するブログ記事の本文を Read で渡しておくと、文脈を補ってくれてキャプションの精度が上がります。
確認結果は SRT そのものではなく、Python の dict として書き出してもらうとレビュー・修正が楽です。
SRT_DATA = {
"7WCO7JoMnWc": [
(0, "Alfresco + Archivematica で AIP を作成するパイプラインのデモです。"),
(8, "Alfresco の管理画面でファイルを選択し、AIP化のリクエストを送ります。"),
(16, "Archivematica が AIP(Archival Information Package)を生成して返します。"),
(24, "AIP の中身(METS XML など)も画面で確認できます。"),
(30, "詳しい構築手順はブログ記事を参照してください。"),
],
# ... 他の動画
}
各エントリは (開始秒, 字幕テキスト) のタプルで、終了時刻は次キャプションの開始時刻、または動画の終端としています。これを SRT 形式に書き出すコードは以下です。
from pathlib import Path
import subprocess
def fmt(t: float) -> str:
h = int(t // 3600)
m = int((t % 3600) // 60)
s = int(t % 60)
ms = int((t - int(t)) * 1000)
return f"{h:02d}:{m:02d}:{s:02d},{ms:03d}"
def ffprobe_duration(p: str) -> float:
out = subprocess.check_output(['ffprobe', '-v', 'error', '-show_entries',
'format=duration', '-of',
'default=nokey=1:noprint_wrappers=1', p]).decode()
return float(out.strip())
for vid, items in SRT_DATA.items():
d = ffprobe_duration(f'{vid}.mp4')
lines = []
for i, (start, text) in enumerate(items):
end = items[i + 1][0] if i + 1 < len(items) else d
lines.append(f"{i + 1}\n{fmt(start)} --> {fmt(end)}\n{text}\n")
Path(f'{vid}.srt').write_text('\n'.join(lines), encoding='utf-8')
字幕は短く保ち、長尺動画でも10行程度に収める運用にしました。詳細はブログ記事側に誘導する方針です。
4. captions.insert でアップロード
YouTube Data API の captions.insert は、SRT/VTT などの字幕ファイルをマルチパートでアップロードする呼び出しです。
from googleapiclient.http import MediaFileUpload
from google.oauth2.credentials import Credentials
from google.auth.transport.requests import Request
from googleapiclient.discovery import build
import os
SCOPES = ['https://www.googleapis.com/auth/youtube.force-ssl']
TOKEN = os.path.expanduser('~/.youtube_comments_token.json')
creds = Credentials.from_authorized_user_file(TOKEN, SCOPES)
if not creds.valid:
if creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
raise RuntimeError('Token invalid and cannot be refreshed; re-run the OAuth flow.')
yt = build('youtube', 'v3', credentials=creds)
for srt in Path('.').glob('*.srt'):
vid = srt.stem
media = MediaFileUpload(str(srt), mimetype='application/octet-stream', resumable=False)
body = {
'snippet': {
'videoId': vid,
'language': 'ja',
'name': '日本語',
'isDraft': False,
}
}
resp = yt.captions().insert(part='snippet', body=body, media_body=media).execute()
print(f"{vid}: caption_id={resp['id']}")
isDraft: False で公開状態として登録します。
認証スコープ
captions.insert には https://www.googleapis.com/auth/youtube.force-ssl スコープの OAuth トークンが必要です。動画情報の更新で使う youtube scope では 403 になるようでした。
youtube scope のトークンが既にあっても、追加スコープを要求する場合は別ファイルでトークンを取得し直すのが安全です。今回は ~/.youtube_comments_token.json という別ファイルを使用しました。
from google_auth_oauthlib.flow import InstalledAppFlow
CLIENT_SECRET = os.path.expanduser('~/.youtube_client_secret.json')
TOKEN = os.path.expanduser('~/.youtube_comments_token.json')
if not os.path.exists(TOKEN):
flow = InstalledAppFlow.from_client_secrets_file(
CLIENT_SECRET, ['https://www.googleapis.com/auth/youtube.force-ssl'])
creds = flow.run_local_server(port=0)
with open(TOKEN, 'w') as f:
f.write(creds.to_json())
ハマりどころ
通常の youtube scope では captions.insert が 403
captions.insert / update / delete は youtube.force-ssl スコープが必須です。一方、読み取り系の captions.list は API キーで呼べるので、字幕有無の確認だけなら追加スコープを取らなくても通ります。OAuth で書き込みまで行う場合は force-ssl 用に別トークンを取り直すのが楽でした。
動画の実音声有無は yt-dlp の acodec だけでは判定できない
yt-dlp が返すフォーマットに acodec != 'none' を持つものがあるからといって、実際に音が入っているとは限らないようです。無音の動画にも音声トラックが付いて配信されているケースがあるため、実音声の判定にはダウンロード後の WAV を ffmpeg volumedetect で計測する手順を入れています。
一括処理中の DNS 解決失敗
順次ダウンロードしていると、途中で Failed to resolve 'www.youtube.com' が断続的に出ました。原因はおそらくネットワーク側の一時的な問題ですが、スクリプト側でも既存ファイルがあればスキップする仕組みを入れて、再実行で続きから処理できるようにしておくと無難です。
関連メモ: description には半角の < > を入れない
別作業で動画の説明文を更新した際、本文中に <app><lem>...</lem></app> のような XML タグ例を含んだ description を videos.update で送ったところ invalidDescription で 400 が返りました。半角の < > は description で許容されないため、フルワイドの 〈〉 等への置換が必要です。description と caption は別の話ですが、YouTube への文字列送信で詰まったらまずこの2点(scope と特殊文字)を確認するのが早そうです。
字幕の精度について
Claude Code は画面のフレームと記事本文から内容を推定するため、画面遷移の細かな違いや、画面上の小さな UI 要素をすべて拾えるとは限りません。本記事の運用では、字幕は「この動画は◯◯のデモです」「△△の操作を行っています」程度の粒度に留め、詳細はブログ記事の説明欄リンクに誘導する方針としました。視聴者が記事側に飛べる状態が担保されていれば、字幕は内容の道しるべ程度で十分機能するという考え方です。
精度を上げたい場合は、各セクションの代表フレームを単独画像として Read で確認させたり、対応するブログ記事のスクリーンショット箇所と紐付けて推定させたりすると改善できそうです。