本記事は生成AIと共同で執筆しています。事実関係は可能な範囲で公式ドキュメント等と照合していますが、誤りが含まれている可能性があります。重要な判断を行う前にご自身でも一次情報をご確認ください。
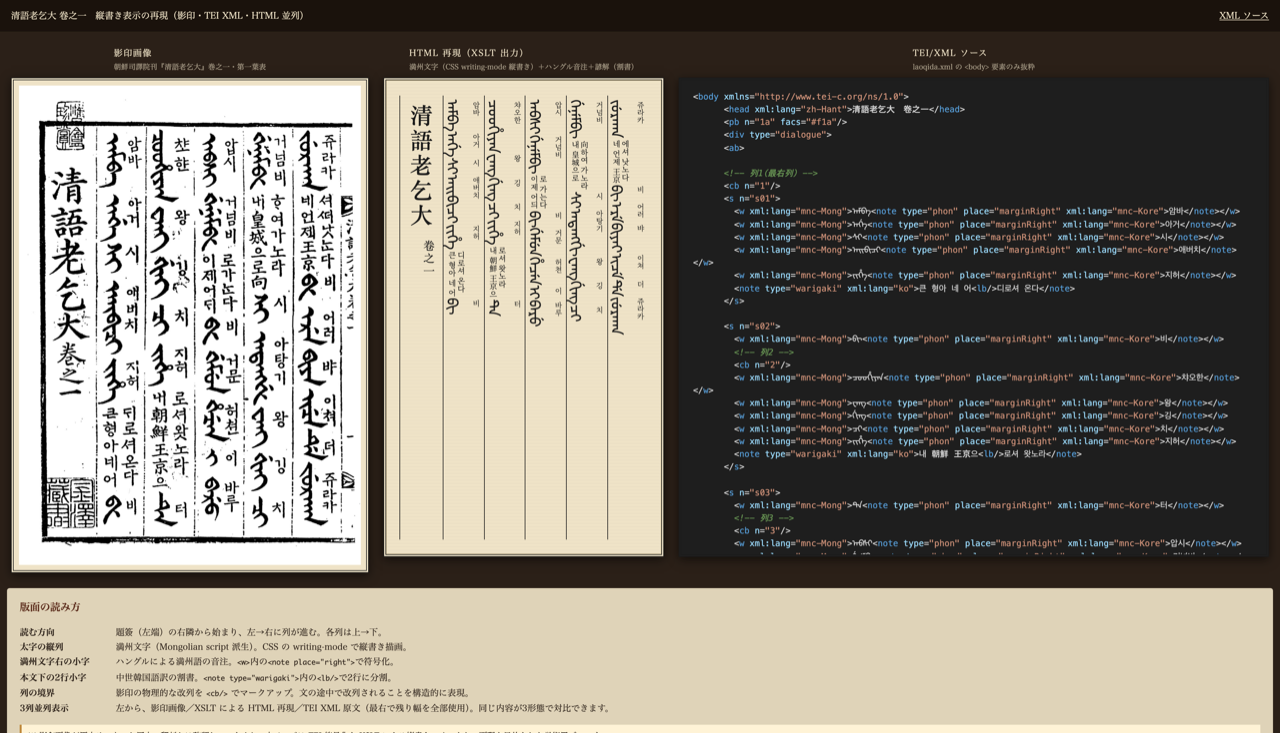
朝鮮司譯院刊『清語老乞大』巻之一・第一葉表を題材に、TEI/XML で版面を符号化し、XSLT で縦書きの HTML 再現を生成する学術用デモを公開しました。
- 公開ページ: https://manchu.vercel.app/(GitHub Pages 版: https://nakamura196.github.io/manchu/)
- リポジトリ: https://github.com/nakamura196/manchu
ページを開くと、影印画像 / XSLT による HTML 再現 / TEI XML ソース、の 3 列が並列に並びます。同じ内容を 3 つの形態で対比して読むためのレイアウトです。
対象資料:清語老乞大とは
『清語老乞大』(チョンオ・ノゴルデ)は朝鮮王朝の司譯院(外国語通訳養成の官署)が編んだ満州語の会話学習書です。元代の漢語会話書『老乞大』を満州語に翻訳し、各語の右側に小字でハングルによる音注、各文の下に中世韓国語訳を割書(双行に分けた小字)で添える形を取ります。康熙〜乾隆年間(17 世紀末〜18 世紀後半)に何度か刊行されました。
ひとつの版面の中に、
- 満州文字(モンゴル文字派生の縦書きスクリプト)の本文
- 各語の右側に添えたハングル音注
- 文末に置いた中世韓国語訳の割書
の 3 層の異なる文字体系・配置規則が共存する、というのが版面構造上の特徴です。
データと可視化を分離する
このプロジェクトでは「TEI/XML(データ)」と「XSLT による HTML + SVG 描画(可視化)」を意図的に分離しました。データ側に版面構造の意味を残し、可視化側はそれを読み解いて表示する、という階層にしてあります。
データ側は TEI 標準要素のみで書きます。ベンダー拡張や独自要素は使いません。版面の物理構造の表現には次の要素を割り当てました。
| TEI 要素 | 用途 |
|---|---|
<cb n="N"/> | 列の境界。文の途中での改列も自然に表現できる |
<w xml:lang="mnc-Mong"> | 満州語の各語(満州文字本体を子テキストとして保持) |
<note type="phon" place="marginRight"> | 各語の右側に添えられたハングル音注 |
<note type="warigaki"> | 中世韓国語訳の割書(内部に <lb/> を置いて 2 行に分割) |
<pb/>, <surface>, <graphic> | 影印画像との対応 |
TEI All RelaxNG スキーマで xmllint --relaxng を通すと valid と判定されます。標準要素だけで「縦書き多層」をかなり表現できることが分かります。
curl -sSL -o /tmp/tei_all.rng \
https://tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng
xmllint --noout --relaxng /tmp/tei_all.rng docs/laoqida.xml
# → docs/laoqida.xml validates
@place には TEI 推奨値のうち最も近い marginRight を採用しました。スキーマ上は open list なので right でも valid ですが、TEI ガイドラインが例示する semi-closed value list(top bottom margin inline 等)に沿うと marginRight のほうが慣用的です。
XML としては次のような形になります。
<cb n="1"/>
<s n="s01">
<w xml:lang="mnc-Mong">ᠠᠮᠪᠠ<note type="phon" place="marginRight" xml:lang="mnc-Kore">암바</note></w>
<w xml:lang="mnc-Mong">ᠠᡤᡝ<note type="phon" place="marginRight" xml:lang="mnc-Kore">아거</note></w>
<w xml:lang="mnc-Mong">ᠰᡳ<note type="phon" place="marginRight" xml:lang="mnc-Kore">시</note></w>
<w xml:lang="mnc-Mong">ᠠᡳᠪᡳᠴᡳ<note type="phon" place="marginRight" xml:lang="mnc-Kore">애버치</note></w>
<w xml:lang="mnc-Mong">ᠵᡳᡥᡝ<note type="phon" place="marginRight" xml:lang="mnc-Kore">지허</note></w>
<note type="warigaki" xml:lang="ko">큰 형아 네 어<lb/>디로셔 온다</note>
</s>
ポイントは 2 点あります。1 つは「文の途中に <cb/> が割り込めること」。たとえば <s> の中で <w>...<cb n="2"/>...<w>... のように、文の途中で改列されても TEI 上は同じ <s> の連続として扱えます。これは版面の物理的な改列が文の論理的な区切りと一致しない、という古典籍の特徴を直接表現します。
もう 1 つは「<note> を単に注釈ではなく、版面上の位置情報を持つ要素として使うこと」。type 属性で意味(音注 / 割書)を、place 属性で物理位置(右添え)を表します。可視化側はこの属性を読み取ってレイアウトを決めます。
XSLT で列に切り出す
XSLT 1.0 で書いた変換スクリプト(docs/laoqida.xsl)が、上記の TEI を HTML に変換します。XSLT 1.0 にしているのは xsltproc でローカル変換でき、ビルド時に静的 HTML を吐けるからです(ブラウザ内蔵の XSLT エンジンを当てにする運用は最近では非推奨です。Chrome は v158 で XSLT 対応を削除予定と告知されており、Edge も追随、WebKit / Firefox も削除を表明しています。ビルド時変換に倒しておくと将来も安心です)。
可視化の中核は「<cb/> をキーに、文書順の <w> と <note type="warigaki"> を列ごとにグループ化する」処理です。
<xsl:variable name="all-cbs" select="//tei:cb"/>
<xsl:template match="tei:cb" mode="column">
<xsl:variable name="this-cb" select="."/>
<xsl:variable name="cb-pos" select="count(preceding::tei:cb) + 1"/>
<xsl:variable name="next-cb" select="$all-cbs[position() = $cb-pos + 1]"/>
<div class="col manchu-col">
<xsl:choose>
<xsl:when test="$next-cb">
<xsl:apply-templates
select="following::tei:w[count(. | $next-cb/preceding::tei:w)
= count($next-cb/preceding::tei:w)]
| following::tei:note[@type='warigaki']
[count(. | $next-cb/preceding::tei:note)
= count($next-cb/preceding::tei:note)]"
mode="content"/>
</xsl:when>
<xsl:otherwise>
<!-- 最終列:以降のすべて -->
<xsl:apply-templates
select="following::tei:w | following::tei:note[@type='warigaki']"
mode="content"/>
</xsl:otherwise>
</xsl:choose>
</div>
</xsl:template>
count(. | $next-cb/preceding::tei:w) = count($next-cb/preceding::tei:w) という条件式は、XSLT 1.0 における set-membership idiom です(XSLT 2.0 以降の intersect 演算子の代わりに使う定石)。ノード集合の合併サイズと元集合のサイズが等しいなら、対象ノードは元集合に含まれている、という判定で、ここでは「次の <cb/> より前にある <w> だけを選ぶ」を表現しています。なお Steve Muench 由来の "Muenchian grouping" は厳密には xsl:key と generate-id() を使うグループ化の別パターンを指すので、ここは set-membership と呼ぶほうが正確です。
満州文字の描画:CSS writing-mode に倒す
縦書き満州文字を Web で出すとき、ぱっと思いつく選択肢は次の 3 つです。
- HTML 要素に CSS
writing-mode: vertical-lrを当て、Mongolian 対応フォントを読ませる - SVG
<text>の中でwriting-mode: vertical-lrを指定し、SVG 経由で描画する - HarfBuzz 等でビルド時にプリレンダーした PNG / SVG を埋め込む
最初は安全策に見えた 2 を採用していましたが、これは iOS Safari で正しく動かないケースがある ことが分かりました。WebKit の SVG <text> 上の writing-mode 実装には歴史的にバグがあり (WebKit Bug 112488)、Mongolian の文字方向についても iOS 17.4 / Safari 17.4(2024 年 3 月)でようやく修正されたという経緯があります (WebKit commit 6c53862、w3c/mlreq#39)。なお writing-mode を SVG <text> の presentation attribute として書く形は SVG 2 で deprecated 扱いです(MDN)。
W3C の Mongolian Layout Requirements と Vertical text styling が推奨しているのは、SVG ではなく HTML + CSS writing-mode: vertical-lr; text-orientation: mixed を直接当てる路線です。Safari 17.4 以降は Mongolian / Phags-pa の上下方向も正しく描画されるため、現時点の主要ブラウザ(macOS / iOS Safari, Chrome, Firefox, Edge)で安定して動きます。
ということで実装はシンプルになりました。
<xsl:template match="tei:w" mode="content">
<xsl:variable name="m-text" select="normalize-space(text()[normalize-space()][1])"/>
<xsl:variable name="phon" select="tei:note[@type='phon']"/>
<span class="word">
<span class="m-text" lang="mnc-Mong"><xsl:value-of select="$m-text"/></span>
<span class="m-pron"><xsl:value-of select="normalize-space($phon)"/></span>
</span>
</xsl:template>
.m-text {
writing-mode: vertical-lr;
text-orientation: mixed;
font-family: "Noto Sans Mongolian", "Mongolian Baiti", serif;
font-size: 22px;
line-height: 1.05;
white-space: nowrap;
display: inline-block;
}
SVG 経由をやめたことで、満州文字本体が 本物の DOM テキストになり、ユーザーの選択・コピー・読み上げ・フォントスケールがすべて素直に効くようになりました。語長に応じた高さ計算も不要です(縦書きフローが自動でレイアウトする)。

iPhone Safari でも縦並びレイアウトで 3 セクションが順に表示されます。

なお、フォント自体の供給状況にも触れておきます。macOS と iOS にはデフォルトで Mongolian script 対応のシステムフォントが入っていません("Mongolian Baiti" は Windows / Office に付属する Microsoft のフォントです)。本デモは Google Fonts の Noto Sans Mongolian を @font-face で読ませて埋める前提です。配信先がオフライン環境になる場合は WOFF2 を self-host するのが堅いです。
右添えハングルと、割書(warigaki)諺解
満州文字 SVG の右側にハングル音注を置く部分は flexbox の素直な使い方です。
.word {
display: flex;
flex-direction: row;
align-items: stretch;
gap: .08rem;
}
.m-pron {
writing-mode: vertical-lr;
font-family: "Noto Serif KR", "Apple SD Gothic Neo", serif;
font-size: .68rem;
/* ... */
}
各 <w> は .word の flex 行で、左に満州文字 SVG、右にハングル音注の縦書き列、を並べます。
割書諺解は、版面では 1 つの列の幅の中に細い字を 2 行並べて入れるという独特の表現です。これも flexbox で 2 つの .wari-line を並べる形に落とし込みました。XSLT 側で <note type="warigaki"> の中の <lb/> 区切りでテキストノードを 2 つに割り、それぞれを縦書きの 1 行として出します。
<xsl:template match="tei:note[@type='warigaki']" mode="content">
<xsl:variable name="lines" select="text()[normalize-space()]"/>
<span class="warigaki">
<span class="wari-line"><xsl:value-of select="normalize-space($lines[1])"/></span>
<span class="wari-line"><xsl:value-of select="normalize-space($lines[2])"/></span>
</span>
</xsl:template>
割書の 2 行をどう数えるか、というのは古典籍ごとに揺れがあります。本デモでは「<note type="warigaki"> の直下のテキストノードを上から数えて 2 つ」、つまり <lb/> で区切られた前後を取る、という単純なルールにしました。3 行以上を許す本格的なデータでは <lb/> ごとに繰り返す形に拡張する余地があります。
列の進行方向
満州文字版面では 題簽が左端、本文の列は左から右へ進み、各列は上から下に読む、という方向です。漢籍の縦書きが右→左に進むのとは逆向きで、これはモンゴル文字系の伝統に由来します。
CSS でこれを再現するときの落とし穴は、ブラウザの writing-mode: vertical-rl(中国・日本語の縦書き)と writing-mode: vertical-lr(モンゴル系)の違いを混同しないことです。漢籍用に書かれた CSS をそのまま流用すると、列の並びが鏡像になります。本デモでは:
- 列の並び: flexbox の
flex-direction: row(左→右) - 各列の中の文字方向:
writing-mode: vertical-lr
を組み合わせています。
影印・HTML 再現・TEI XML の 3 列対比ビュー
ページ全体は影印画像 / XSLT 出力 / XML ソース の 3 列を横並びにして、同じ位置の内容を 3 形態で比較できるようにしました。XML ソース欄は JavaScript で laoqida.xml を fetch して <body> 要素だけを抜き出し、簡易シンタックスハイライト付きで <pre> に流し込みます。
fetch('laoqida.xml', { cache: 'no-store' })
.then(r => r.text())
.then(raw => {
const doc = new DOMParser().parseFromString(raw, 'application/xml');
const bodyEl = doc.getElementsByTagNameNS(
'http://www.tei-c.org/ns/1.0', 'body')[0];
const src = new XMLSerializer().serializeToString(bodyEl);
// ... タグ・属性・文字列・コメント・PI を span で囲むだけの簡易ハイライト
pre.innerHTML = src
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/(<\/?)([\w:.-]+)((?:\s+[\w:.-]+\s*=\s*"[^"]*")*)\s*(\/?>)/g,
/* ... */ );
});
外部ライブラリを入れずに DOM 標準だけで完結させているのは、配布物を 1 つの HTML + CSS + JS に閉じ込めるためです(XSLT が事前に流すスタイルシートと併せて 3 ファイルで動きます)。
デプロイ
docs/ 配下を Vercel と GitHub Pages の両方に配信しています。vercel.json で outputDirectory: docs を指定し、/laoqida.xml のレスポンスに Content-Type: application/xml; charset=utf-8 を明示するだけのシンプルな設定です。
{
"$schema": "https://openapi.vercel.sh/vercel.json",
"outputDirectory": "docs",
"cleanUrls": true,
"trailingSlash": false,
"headers": [
{
"source": "/laoqida.xml",
"headers": [
{ "key": "Content-Type", "value": "application/xml; charset=utf-8" }
]
}
]
}
xsltproc docs/laoqida.xsl docs/laoqida.xml > docs/index.html を手元で実行すれば、デプロイ時には静的 HTML として配信されます。ブラウザ内蔵の XSLT を使う形にしておくと配信は更に薄くできますが、初回表示時のクライアント側コストとファビコン・OG 画像のクロール挙動を考えると、ビルド時に HTML を吐く方が運用が楽でした。
残課題
- 影印画像と TEI のセル単位の双方向リンク。現状は
<surface>と<pb/>でページ全体は紐付いていますが、<zone>単位の bbox は未付与で、影印上の位置とのクリック連動はできていません。 - 第一葉裏以降の符号化。デモは第一葉表のみです。
- 影印画像が原本そのものか写本・翻刻かの確認。本ページは TEI 符号化と XSLT による縦書きレイアウトの再現を目的とした学術用デモで、原本同定までは踏み込めていません。
- 音注(中世韓国語ハングル)と諺解の判読は底本影印からの推定を含みます。誤りがあれば
docs/laoqida.xmlの該当<w>または<note>を修正します。