AI画像生成でiOSアプリアイコンを作るためのプロンプトテンプレート
はじめに iOSアプリのアイコンをAI画像生成ツール(Gemini、ChatGPT/DALL-E、Midjourney等)で作る際、Apple Human Interface Guidelines(HIG)に準拠した画像を一発で生成するのは意外と難しいです。
よくある失敗:
角丸が事前に適用されている(iOSが自動で角丸マスクをかけるので不要) 四隅に白い隙間がある テキストが入っている 細かすぎて小サイズで潰れる 本記事では、これらの問題を回避するプロンプトテンプレートを紹介します。
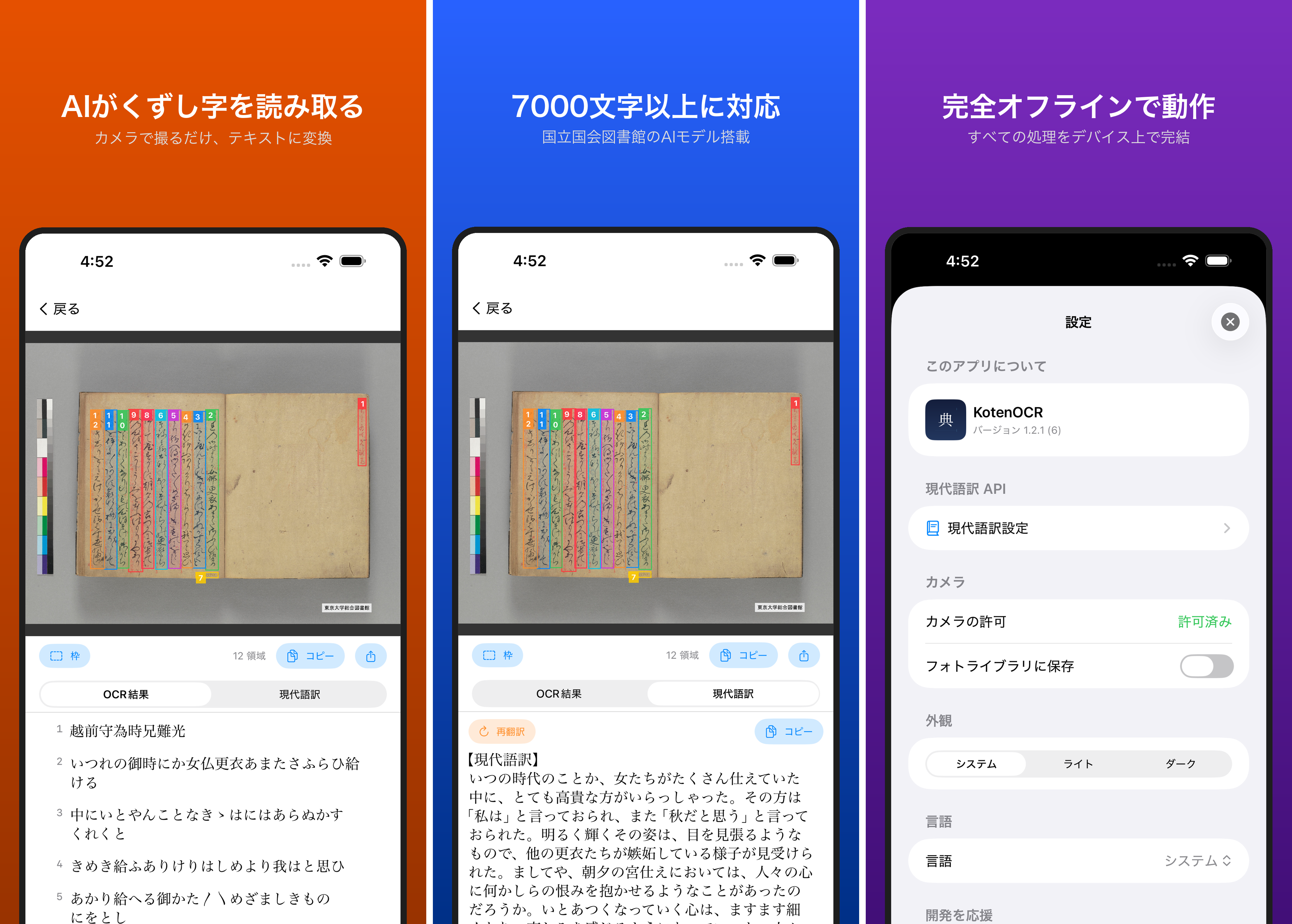
テンプレート A flat, square 1024x1024 app icon for an iOS app called "{{APP_NAME}}" that {{APP_DESCRIPTION}}. Design requirements: - Fill the entire canvas edge-to-edge with a uniform {{BACKGROUND_COLOR}} background. No white areas, no transparency, no empty corners. - Do NOT include frames, borders, or decorative edges of any kind. - Center illustration: {{ILLUSTRATION_DESCRIPTION}}, rendered in {{INK_COLOR}} line art style. - Include one {{ACCENT_COLOR}} {{ACCENT_ELEMENT}} placed on the illustration to {{ACCENT_PURPOSE}}. - {{OPTIONAL_ELEMENT}} - Style: elegant, minimal color palette ({{COLOR_PALETTE}}), flat design, no gradients on illustration, no shadows, no 3D effects. - Detailed enough to be interesting but clear at small sizes (29px). Medium-weight lines. - Do NOT add any text, letters, or characters. - Do NOT pre-round corners — perfectly square image. iOS applies rounded corners automatically. - Output: square PNG, 1024x1024 pixels. ```text ## 変数一覧 | 変数 | 説明 | 例 | |------|------|-----| | `APP_NAME` | アプリ名 | IIIF AR | | `APP_DESCRIPTION` | 機能を1文で | places historical maps in AR | | `BACKGROUND_COLOR` | 背景色 | warm cream (#F0E4CC) | | `ILLUSTRATION_DESCRIPTION` | 中央イラストの内容 | a Japanese landscape with mountains | | `INK_COLOR` | イラストの線画色 | dark navy (#1A237E) | | `ACCENT_COLOR` | アクセント色 | blue (#1565C0) | | `ACCENT_ELEMENT` | アクセント要素 | AR pin marker | | `ACCENT_PURPOSE` | アクセントの意図 | suggest spatial placement | | `OPTIONAL_ELEMENT` | 追加要素(不要なら行ごと削除) | a subtle perspective grid | | `COLOR_PALETTE` | 色パレットの説明 | cream + navy + blue accent | ## 使用例 ### 歴史的絵図ARアプリ ```text A flat, square 1024x1024 app icon for an iOS app called "IIIF AR" that places high-resolution cultural heritage images in augmented reality at real-world scale. Design requirements: - Fill the entire canvas edge-to-edge with a uniform warm cream/parchment (#F0E4CC) background. No white areas, no transparency, no empty corners. - Do NOT include frames, borders, or decorative edges of any kind. - Center illustration: a stylized composition showing overlapping cultural heritage imagery — such as a fragment of a traditional Japanese landscape painting with mountains, water, and architecture — rendered in dark navy (#1A237E) line art style. - Include one blue (#1565C0) location/AR pin marker placed on the illustration to suggest spatial placement. - Optionally include a subtle perspective grid (2-3 thin lines) at the bottom to hint at AR floor placement. - Style: elegant, minimal color palette (cream + navy ink + one blue accent), flat design, no gradients on illustration, no shadows, no 3D effects. - Detailed enough to be interesting but clear at small sizes (29px). Medium-weight lines. - Do NOT add any text, letters, or characters. - Do NOT pre-round corners — perfectly square image. iOS applies rounded corners automatically. - Output: square PNG, 1024x1024 pixels. ```text ### くずし字OCRアプリ ```text A flat, square 1024x1024 app icon for an iOS app called "KotenOCR" that recognizes classical Japanese cursive script (kuzushiji) using on-device AI. Design requirements: - Fill the entire canvas edge-to-edge with a uniform warm ivory (#FAF3E8) background. No white areas, no transparency, no empty corners. - Do NOT include frames, borders, or decorative edges of any kind. - Center illustration: a stylized fragment of a classical Japanese manuscript page with elegant brushstroke characters, rendered in dark sumi ink (#2C1810) line art style. - Include one teal (#00897B) scanning/recognition indicator (such as a viewfinder bracket or highlight box) placed over one character to suggest OCR recognition. - Style: elegant, minimal color palette (ivory + sumi ink + one teal accent), flat design, no gradients on illustration, no shadows, no 3D effects. - Detailed enough to be interesting but clear at small sizes (29px). Medium-weight lines. - Do NOT add any text, letters, or characters. - Do NOT pre-round corners — perfectly square image. iOS applies rounded corners automatically. - Output: square PNG, 1024x1024 pixels. ```text ## Apple HIG準拠チェックリスト 生成後に以下を確認してください。 - [ ] 正方形(1024×1024px)で、角丸なし - [ ] 四隅まで背景色で塗りつぶされている(透明や白の隙間なし) - [ ] テキストが含まれていない - [ ] 写真ではなくイラスト/グラフィック - [ ] 29pxに縮小しても何のアプリかわかる - [ ] Apple製品のレプリカが含まれていない - [ ] カスタムのハイライトやドロップシャドウがない ## 適用方法 ```bash # 生成した画像を配置 cp ~/Downloads/generated_icon.png \ {PROJECT}/Assets.xcassets/AppIcon.appiconset/AppIcon.png # ビルドして確認 xcodegen generate xcodebuild build -project {PROJECT}.xcodeproj -scheme {SCHEME} ... ```text ## 参考 - [Apple Human Interface Guidelines - App Icons](https://developer.apple.com/design/human-interface-guidelines/app-icons)
2026年3月24日 · 4 分 · Nakamura