アクセス制御付き IIIF デジタルアーカイブの構築 — Cloudflare Access で守る Cantaloupe + S3 + Elasticsearch + Next.js
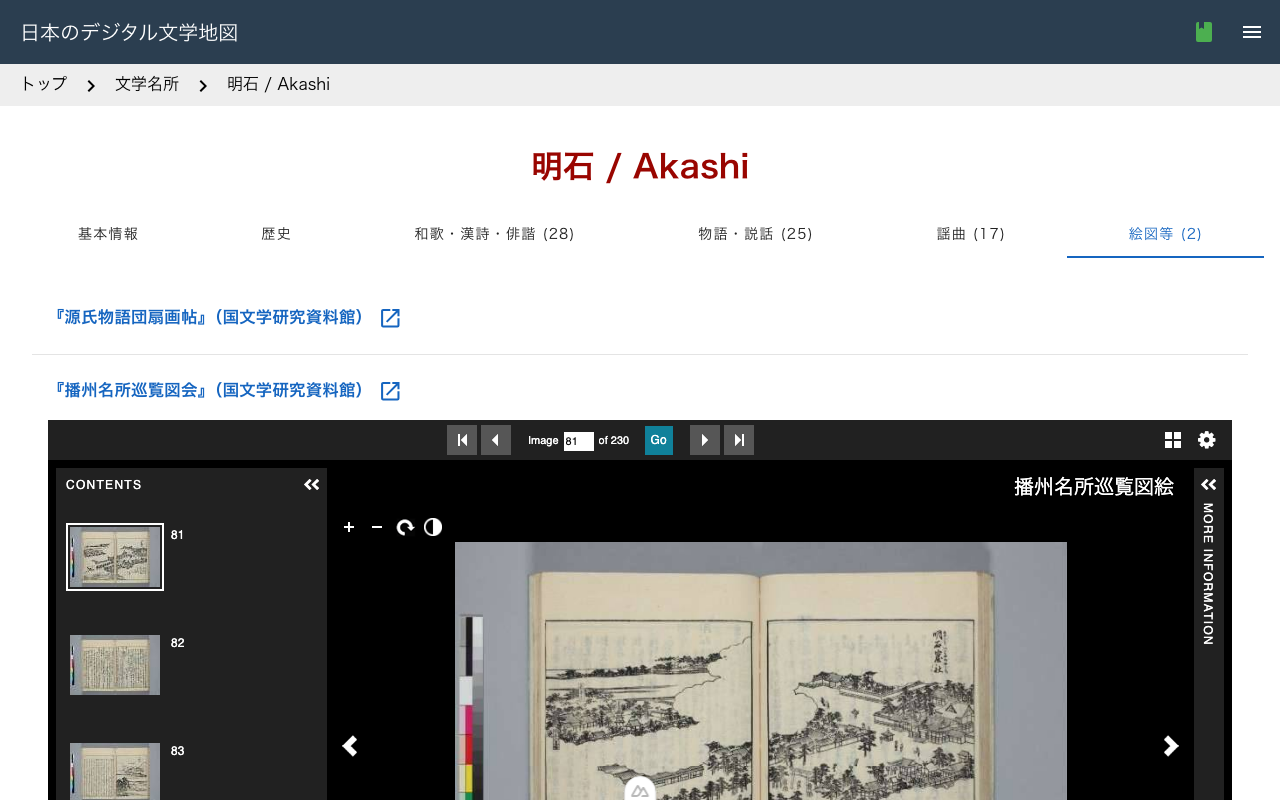
未公開 / 限定公開の歴史写真を、IIIF 規格に準拠した形でアクセス制御付きで配信するアーカイブシステムの構築記録。Cantaloupe(IIIF サーバ)+ S3 互換ストレージ + Elasticsearch(検索)+ Next.js(UI)+ Cloudflare Tunnel + Access という構成で、一般公開できない画像であっても IIIF の利点(規格準拠の高解像度ビューア / manifest 配信)を許可されたメンバー範囲内で享受できる仕組みを設計しました。外部システムからの相互運用には IIIF Auth API 2.0 への拡張が必要となる点も整理しています。
iiifcantaloupeelasticsearchnextjs