This article is co-authored with generative AI. While I have cross-checked facts against official documentation where possible, errors may remain. Please verify primary sources before making important decisions.
I built a small scholarly demo that encodes the first folio of the Joseon-era Manchu primer Cing gisun-i Lao Kida (清語老乞大) in TEI/XML and renders its vertical layout — Manchu script, Hangul phonetic gloss, and Korean warigaki translation — using an XSLT 1.0 stylesheet that produces HTML + SVG.
- Live page: https://manchu.vercel.app/ (also on GitHub Pages: https://nakamura196.github.io/manchu/)
- Repository: https://github.com/nakamura196/manchu
The page shows three columns side by side: the facsimile image, the HTML reconstruction produced by XSLT, and the TEI XML source. Same content, three forms, lined up for comparison.
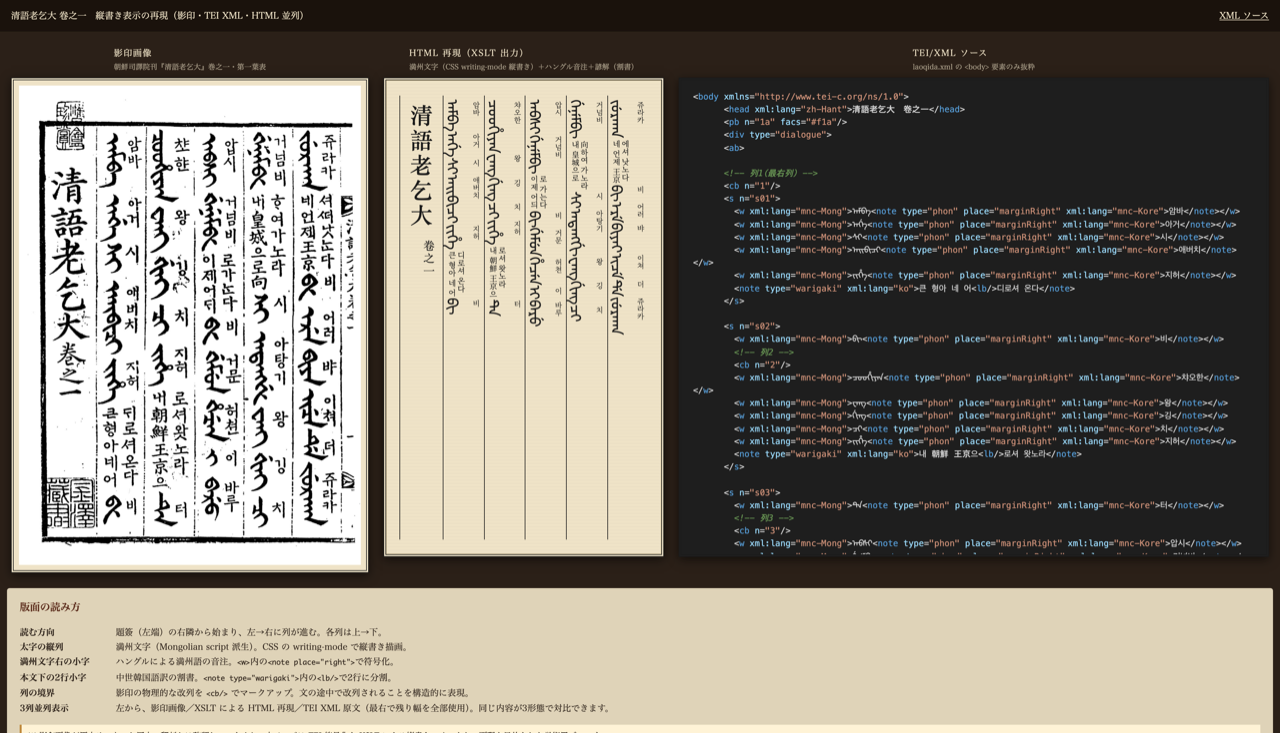
The source: Cing gisun-i Lao Kida
Cing gisun-i Lao Kida (Korean Cheongeo Nogeoldae) is a Manchu conversation primer compiled by the Sayŏgwŏn (司譯院), the bureau of interpreters of the Joseon dynasty. It translates the Yuan-era Chinese conversation manual Lao Kida (老乞大) into Manchu, adds a small-character Hangul phonetic gloss to the right of each Manchu word, and places a middle-Korean translation in two-line warigaki (small-character double-column) form at the end of each utterance. Editions appeared between roughly the late 17th and the late 18th century.
A single woodblock-printed page combines three distinct writing systems with three different placement rules:
- Manchu script (a vertical-writing system derived from Mongolian) for the body text
- Hangul phonetic gloss positioned to the right of each Manchu word
- A middle-Korean translation rendered as small-character warigaki at the end of the utterance
Separating data from visualization
The project keeps the TEI/XML (data) and the XSLT-driven HTML + SVG rendering (visualization) as deliberately separate layers. The data side carries the semantic structure of the page; the visualization side reads that structure and lays it out. Updating one without touching the other is the goal.
The data side uses only standard TEI elements — no vendor extensions. The mapping I settled on:
| TEI element | Role |
|---|---|
<cb n="N"/> | Column boundary. Captures column breaks that happen mid-sentence |
<w xml:lang="mnc-Mong"> | A Manchu word, with the Manchu script as its text content |
<note type="phon" place="marginRight"> | The Hangul phonetic gloss attached to the right of the word |
<note type="warigaki"> | The middle-Korean warigaki translation, with <lb/> splitting it into two lines |
<pb/>, <surface>, <graphic> | Linkage to the facsimile image |
The document validates against the TEI All RelaxNG schema:
curl -sSL -o /tmp/tei_all.rng \
https://tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng
xmllint --noout --relaxng /tmp/tei_all.rng docs/laoqida.xml
# → docs/laoqida.xml validates
Standard TEI already covers most of what you need for a layout this rich. The @place attribute uses the closest of TEI's suggested values, marginRight. The schema accepts arbitrary tokens (it is a semi-closed list), but marginRight matches the canonical phrasing used in the TEI Guidelines for annotations placed to the right of the text they comment on.
Concretely:
<cb n="1"/>
<s n="s01">
<w xml:lang="mnc-Mong">ᠠᠮᠪᠠ<note type="phon" place="marginRight" xml:lang="mnc-Kore">암바</note></w>
<w xml:lang="mnc-Mong">ᠠᡤᡝ<note type="phon" place="marginRight" xml:lang="mnc-Kore">아거</note></w>
<w xml:lang="mnc-Mong">ᠰᡳ<note type="phon" place="marginRight" xml:lang="mnc-Kore">시</note></w>
<w xml:lang="mnc-Mong">ᠠᡳᠪᡳᠴᡳ<note type="phon" place="marginRight" xml:lang="mnc-Kore">애버치</note></w>
<w xml:lang="mnc-Mong">ᠵᡳᡥᡝ<note type="phon" place="marginRight" xml:lang="mnc-Kore">지허</note></w>
<note type="warigaki" xml:lang="ko">큰 형아 네 어<lb/>디로셔 온다</note>
</s>
Two design points are worth highlighting.
First, <cb/> is allowed to break in mid-sentence. A <s> can carry the sequence <w>...<cb n="2"/>...<w>..., modelling the case where the physical column break of the woodblock does not align with the logical sentence boundary — exactly what happens on the page.
Second, <note> is used as a positional element, not merely as an annotation. type carries the semantic role (phonetic gloss / warigaki) and place carries the physical position (right of the word). The visualization reads these attributes to decide where each note goes.
Splitting columns in XSLT 1.0
The XSLT stylesheet (docs/laoqida.xsl) maps TEI to HTML. I kept it at XSLT 1.0 so that xsltproc can run the same transform for static builds. The browsers' built-in XSLT engines are no longer a reliable target — Chrome announced removal of XSLT support in v158 (Nov 2026), Edge is following, and WebKit and Firefox have both signalled intent to remove XSLT as well. Running the transform at build time is now the safer pattern.
The core of the transform is "group document-order <w> and <note type='warigaki'> nodes by the <cb/> markers between them":
<xsl:variable name="all-cbs" select="//tei:cb"/>
<xsl:template match="tei:cb" mode="column">
<xsl:variable name="this-cb" select="."/>
<xsl:variable name="cb-pos" select="count(preceding::tei:cb) + 1"/>
<xsl:variable name="next-cb" select="$all-cbs[position() = $cb-pos + 1]"/>
<div class="col manchu-col">
<xsl:choose>
<xsl:when test="$next-cb">
<xsl:apply-templates
select="following::tei:w[count(. | $next-cb/preceding::tei:w)
= count($next-cb/preceding::tei:w)]
| following::tei:note[@type='warigaki']
[count(. | $next-cb/preceding::tei:note)
= count($next-cb/preceding::tei:note)]"
mode="content"/>
</xsl:when>
<xsl:otherwise>
<!-- final column: everything that follows -->
<xsl:apply-templates
select="following::tei:w | following::tei:note[@type='warigaki']"
mode="content"/>
</xsl:otherwise>
</xsl:choose>
</div>
</xsl:template>
The predicate count(. | $next-cb/preceding::tei:w) = count($next-cb/preceding::tei:w) is the standard XSLT 1.0 set-membership idiom — testing whether adding the candidate node to the set changes the cardinality. XSLT 2.0 added intersect for the same job; in 1.0 this construction stands in for it. (Strictly speaking, "Muenchian grouping" is Steve Muench's separate xsl:key + generate-id() pattern; this is a different idiom.)
Drawing Manchu script: pick CSS, not SVG
Three obvious approaches exist for rendering vertical Manchu in the browser:
- Plain HTML element with CSS
writing-mode: vertical-lrand a Mongolian-capable font - SVG
<text>withwriting-mode: vertical-lr - Pre-rendered PNG / SVG generated at build time via HarfBuzz or a headless browser
I initially picked option 2 thinking SVG would be more deterministic. That turned out to be wrong on iOS Safari. WebKit has a long history of issues with writing-mode on SVG <text> (WebKit Bug 112488); the Mongolian-character upright/rotation handling specifically was only fixed in Safari 17.4 (March 2024) — see WebKit commit 6c53862 and the resolution of w3c/mlreq#39. On top of that, MDN flags writing-mode as an SVG presentation attribute as deprecated in SVG 2.
The path that W3C's Mongolian Layout Requirements and the W3C i18n vertical-text article actually recommend is option 1: plain HTML with writing-mode: vertical-lr; text-orientation: mixed. With WebKit 17.4+ (covers all iOS shipping in 2026), this renders correctly across macOS / iOS Safari, Chrome, Firefox, and Edge.
So the implementation collapses to:
<xsl:template match="tei:w" mode="content">
<xsl:variable name="m-text" select="normalize-space(text()[normalize-space()][1])"/>
<xsl:variable name="phon" select="tei:note[@type='phon']"/>
<span class="word">
<span class="m-text" lang="mnc-Mong"><xsl:value-of select="$m-text"/></span>
<span class="m-pron"><xsl:value-of select="normalize-space($phon)"/></span>
</span>
</xsl:template>
.m-text {
writing-mode: vertical-lr;
text-orientation: mixed;
font-family: "Noto Sans Mongolian", "Mongolian Baiti", serif;
font-size: 22px;
line-height: 1.05;
white-space: nowrap;
display: inline-block;
}
Dropping the SVG wrapper means the Manchu body text is real DOM text — selection, copy/paste, font scaling, screen readers, and CSS font-size all work without extra effort. The per-word height calculation needed by the SVG version is gone too; the vertical writing-mode flow handles it.

iPhone Safari renders the three sections stacked vertically.

A note on font availability: neither macOS nor iOS ships a default Mongolian-script font. "Mongolian Baiti" is a Microsoft font bundled with Windows / Office. The demo loads Noto Sans Mongolian via Google Fonts through @font-face; for offline deployment, self-hosting the WOFF2 is the robust choice.
Right-side Hangul gloss and warigaki
Placing the Hangul gloss to the right of each SVG-rendered Manchu word is a straightforward flexbox arrangement:
.word {
display: flex;
flex-direction: row;
align-items: stretch;
gap: .08rem;
}
.m-pron {
writing-mode: vertical-lr;
font-family: "Noto Serif KR", "Apple SD Gothic Neo", serif;
font-size: .68rem;
/* ... */
}
Each <w> becomes a .word flex row containing the Manchu SVG on the left and a vertical-text column of Hangul on the right.
Warigaki is the more idiosyncratic case: a single physical column on the page holds two parallel lines of small Korean text, side by side. I render it as a flex row of two .wari-line vertical columns. The XSLT splits the text content of <note type="warigaki"> on its <lb/> and emits each side separately:
<xsl:template match="tei:note[@type='warigaki']" mode="content">
<xsl:variable name="lines" select="text()[normalize-space()]"/>
<span class="warigaki">
<span class="wari-line"><xsl:value-of select="normalize-space($lines[1])"/></span>
<span class="wari-line"><xsl:value-of select="normalize-space($lines[2])"/></span>
</span>
</xsl:template>
How many lines a warigaki note may have is corpus-dependent. The demo assumes exactly two. Generalising to N lines is a matter of looping through the <lb/>-separated chunks.
Column flow direction
Manchu-script pages read column-by-column from left to right, with each column running top to bottom. That is the opposite direction from the Chinese / Japanese vertical convention (right to left across columns), and follows the Mongolian-script tradition.
A common pitfall when reusing CSS written for Chinese / Japanese facsimile is conflating writing-mode: vertical-rl with vertical-lr. The two differ both in glyph orientation defaults and in the direction columns stack. In this demo the layout combines:
- Column ordering across the page: flexbox
flex-direction: row(left → right) - Text direction inside each column:
writing-mode: vertical-lr
A three-panel comparison view
The page lays out three panels side by side: facsimile image / XSLT-rendered HTML / TEI XML source. JavaScript fetches laoqida.xml, extracts just its <body>, and runs a small syntax-highlighter on the result before injecting it into a <pre>:
fetch('laoqida.xml', { cache: 'no-store' })
.then(r => r.text())
.then(raw => {
const doc = new DOMParser().parseFromString(raw, 'application/xml');
const bodyEl = doc.getElementsByTagNameNS(
'http://www.tei-c.org/ns/1.0', 'body')[0];
const src = new XMLSerializer().serializeToString(bodyEl);
pre.innerHTML = src
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/(<\/?)([\w:.-]+)((?:\s+[\w:.-]+\s*=\s*"[^"]*")*)\s*(\/?>)/g,
/* tag / attribute styling */);
});
No external libraries are loaded; the highlighter is a handful of regex-driven <span> wrappers. The whole deliverable is HTML + CSS + one short script, plus the XSLT that produces the HTML at build time.
Deployment
docs/ is served by both Vercel and GitHub Pages. The vercel.json is minimal — it just points outputDirectory at docs/ and adds the right Content-Type for the XML file:
{
"$schema": "https://openapi.vercel.sh/vercel.json",
"outputDirectory": "docs",
"cleanUrls": true,
"trailingSlash": false,
"headers": [
{
"source": "/laoqida.xml",
"headers": [
{ "key": "Content-Type", "value": "application/xml; charset=utf-8" }
]
}
]
}
xsltproc docs/laoqida.xsl docs/laoqida.xml > docs/index.html runs once locally; the deployed site then serves static HTML. Letting the browser apply the XSLT at load time is also possible, but generating HTML at build time keeps the first-paint cost smaller and avoids surprises with crawler behaviour (OG images, etc.).
Open issues
- Bidirectional linkage between facsimile zones and TEI cells. The page-level link is already there via
<surface>and<pb/>, but per-<zone>bounding boxes are not yet attached, so clicking a Manchu word on the rendered page does not jump to its location on the facsimile (and vice versa). - Encoding of folios after 1a. The demo covers only the recto of the first folio.
- The provenance of the facsimile image — original vs. manuscript copy vs. transcription — has not been verified. This page is a scholarly demo of TEI encoding and XSLT-driven layout reproduction, not a study of the source object itself.
- The Hangul phonetic readings and warigaki translations include estimations from the image. Corrections to
docs/laoqida.xmlare welcome.