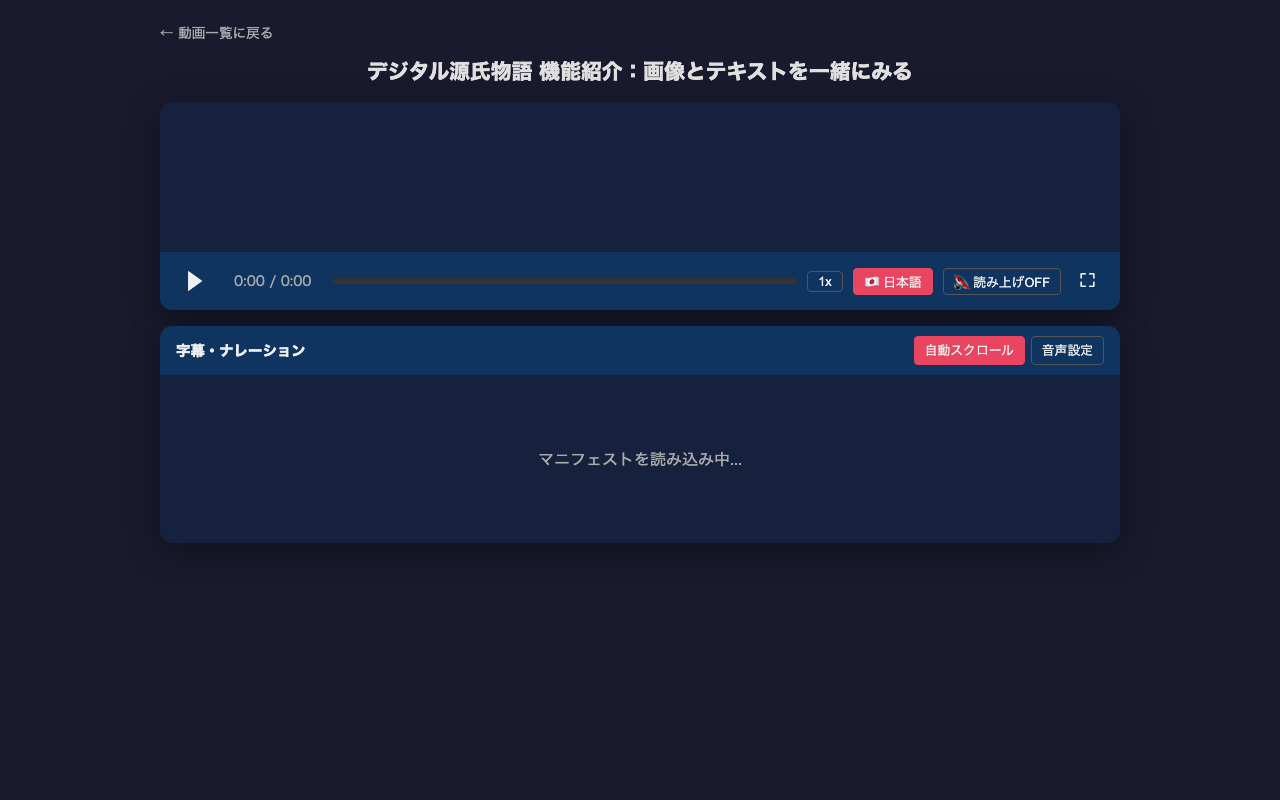
Claude Codeを使って動画に多言語字幕を自動生成し、IIIF v3マニフェストで公開する
動画コンテンツに字幕をつける作業は手間がかかります。本記事では、Claude Code(CLI版Claude)を使い、動画のフレーム分析から多言語字幕(VTT)の生成、IIIF v3マニフェストの作成までを効率的に行う方法を紹介します。 実際のプロジェクトについてはこちらの記事をご覧ください。 全体の流れ 1. 動画ファイル(mp4)を用意する 2. ffmpegでシーンチェンジを検出 3. シーンチェンジポイントのフレームを抽出 4. Claude Codeでフレーム画像を読み取り、内容を把握 5. シーンチェンジのタイムスタンプに基づいてVTTファイルを作成 6. 英語字幕も同様に作成 7. IIIF v3マニフェストを作成 8. HTMLプレーヤーで動画・字幕・読み上げを同期 前提条件 Claude Code(CLI版) ffmpeg / ffprobe 字幕をつけたい動画ファイル(mp4) # macOSの場合 brew install ffmpeg Step 1: シーンチェンジの検出 動画の画面が切り替わるタイミングを自動検出します。これが字幕のタイムスタンプの基準になります。 ffmpeg -i "video.mp4" \ -vf "select='gt(scene,0.15)',showinfo" \ -vsync vfr -f null - 2>&1 \ | grep "pts_time" \ | sed 's/.*pts_time:\([0-9.]*\).*/\1/' 出力例: 3.033333 8.066667 20.066667 25.066667 32.100000 ... なぜシーンチェンジ検出が重要か 最初は3秒間隔でフレームを抽出していましたが、実際の画面切り替えとずれが生じました。シーンチェンジ検出を使うことで、実際に画面が変わるタイミングに基づいた正確な字幕タイミングが得られます。 Step 2: シーンチェンジポイントのフレーム抽出 mkdir -p scenes ffmpeg -i "video.mp4" \ -vf "select='gt(scene,0.15)'" \ -vsync vfr -q:v 2 \ scenes/scene_%03d.jpg Step 3: Claude Codeでフレーム画像の内容を読み取る Claude Codeのマルチモーダル機能で、抽出したフレーム画像の内容を読み取ります。 ...