概要
KotenOCR v1.3.0をリリースしました。従来の古典籍(くずし字)OCRに加えて、近代の活字・手書き文字を認識するNDLOCR-Liteモデルに対応しています。
App Store(無料): https://apps.apple.com/jp/app/kotenocr/id6760045646
デモ動画
古典籍OCR(くずし字)と近代OCR(活字)の両モードの動作を紹介します。
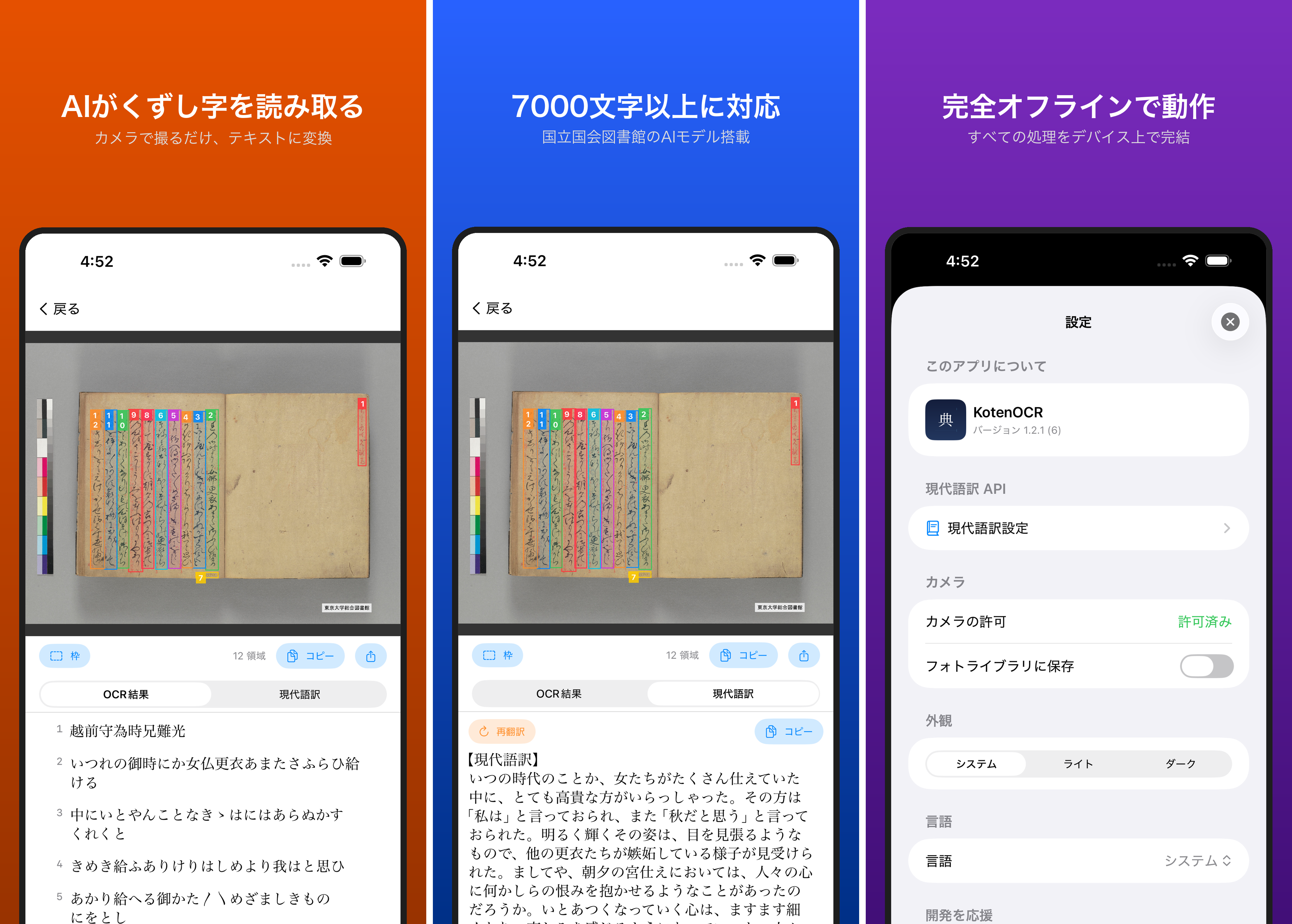
v1.3.0の変更点
主な変更は以下のとおりです。
- NDLOCR-Lite(近代活字OCR)への対応。古典籍モードと近代モードの2つを切り替えて使用可能
- 確認画面で「古典籍 OCR」「近代 OCR」をワンタップで選択できるUI。設定画面を開く必要がない
- OCR結果画面から「戻る」で確認画面に戻り、別モードで再実行可能
- 認識処理の並列化(古典籍1.4倍、近代6.7倍の高速化)
- スプラッシュ画面の追加
- フィードバックメール送信機能の追加
- クラッシュリスクの修正(安全な配列アクセス、force unwrapの除去)
2つのOCRモード
v1.3.0では、対象文書に応じて2つのモードを使い分けることができます。
| モード | 対象 | 検出モデル | 認識モデル | 元モデル |
|---|---|---|---|---|
| 古典籍 | くずし字 | RTMDet-S | PARSeq(1モデル) | NDL古典籍OCR-Lite |
| 近代 | 活字・手書き | DEIMv2-S | PARSeq cascade(3モデル) | NDLOCR-Lite |
古典籍モードは、変体仮名や草書体の漢字で書かれた古典籍を対象としています。近代モードは、明治以降の活字印刷物や手書き文書を対象としています。
近代モードでは、文字列の長さに応じて30文字・50文字・100文字の3つのPARSeqモデルを自動選択するcascade方式を採用しています。
並列化による高速化
認識処理をwithThrowingTaskGroupで並列化することで、処理速度が向上しています。iOSシミュレータ上での計測結果は以下のとおりです。
古典籍(源氏物語、21領域)
| 方式 | 処理時間 |
|---|---|
| 逐次 | 4.55s |
| 並列 | 3.24s |
| 高速化率 | 1.4x |
近代活字(NDLデジタルコレクション、98領域)
| 方式 | 処理時間 |
|---|---|
| 逐次 | 7.59s |
| 並列 | 1.13s |
| 高速化率 | 6.7x |
領域数が多い近代モードのほうが並列化の効果が大きくなっています。これはSwift Concurrencyの協調スレッドプールがCPUコア数に応じて同時実行数を制限する仕組みによるもので、領域数が少ない場合はロック競合のオーバーヘッドが相対的に大きくなります。並列化の詳細は別記事にまとめています。
なお、上記の計測はシミュレータ上で行ったものであり、実機での性能は異なる可能性があります。
ソースコード公開
リポジトリをGitHubで公開しています。MITライセンスです。
リンク
- App Store: https://apps.apple.com/jp/app/kotenocr/id6760045646
- GitHub: https://github.com/nakamura196/koten-ocr-ios
- NDL古典籍OCR-Lite: https://github.com/ndl-lab/ndlkotenocr-lite
- NDLOCR-Lite: https://github.com/ndl-lab/ndlocr-lite