はじめに
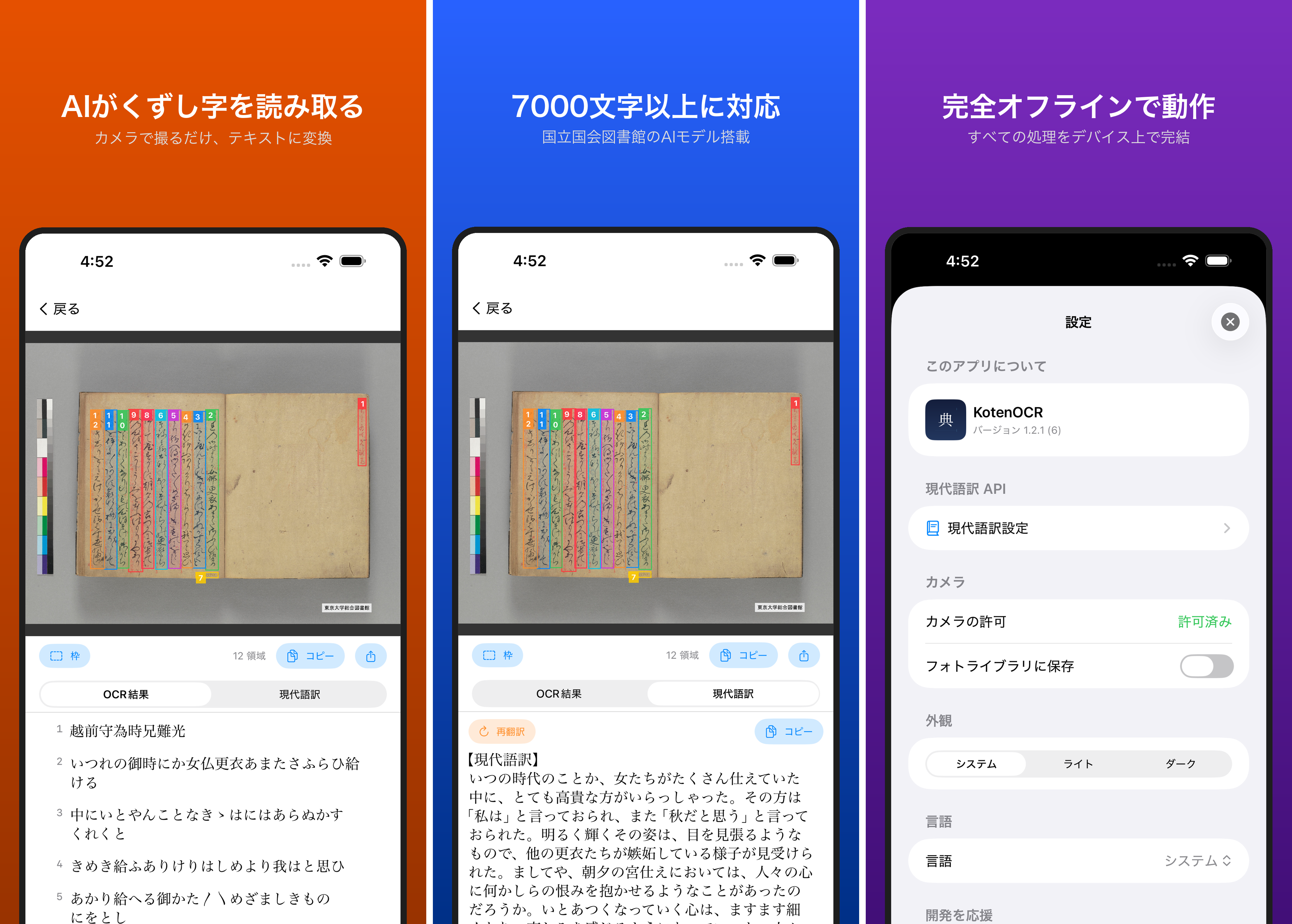
KotenOCRは、国立国会図書館(NDL)が公開したOCRモデルをiOS上で動作させ、くずし字や近代活字をオフラインで認識するアプリです。
近代OCRモード(NDLモード)では、NDLのDEIMv2-Sモデルでレイアウト検出を行い、PARSeQで文字認識を行います。しかし、iOS実装の検出結果が本家のndlocr-liteと比べて明らかに多く、テキストが重複して認識されるという問題がありました。
本記事では、原因の調査から修正までの過程を記録します。
症状:検出数が多すぎる
テスト画像として、NDLデジタルコレクションから取得した「校異源氏物語」の序文ページを使いました。
本家ndlocr-liteでは17件の行検出(line_main、line_captionなど)が得られるのに対し、iOS実装では28件の検出が返り、OCR結果にも重複テキストや文字化けが混入していました。
検出数が多い原因は大きく3つありました。
原因1:NMS(Non-Maximum Suppression)が未実装だった
DEIMv2モデルのONNX出力は、内部でNMSを完了した結果を返すと想定していました。しかし本家ndlocr-liteのコードを読むと、モデル推論後に追加のNMS(IoU閾値=0.2)を適用していることがわかりました。
つまり、モデル出力にはまだ重複する矩形が含まれており、後処理でそれを除去する必要があったのです。
修正:NMSの追加
DEIMDetector.swiftにNMS処理を追加しました。
// DEIMDetector.swift — postprocess() の末尾
// Sort by score descending
let sorted = detections.sorted { $0.score > $1.score }
// Apply NMS to remove overlapping detections
let nmsResult = applyNMS(sorted, iouThreshold: iouThreshold)
return Array(nmsResult.prefix(maxDetections))
NMS本体の実装は以下のとおりです。スコア降順にソートされた検出結果を走査し、既に採用した矩形とのIoUが閾値を超える場合は除外します。
// DEIMDetector.swift
/// Apply Non-Maximum Suppression to remove overlapping detections.
private func applyNMS(_ detections: [Detection], iouThreshold: Float) -> [Detection] {
var kept: [Detection] = []
for det in detections {
var shouldKeep = true
for existing in kept {
if computeIoU(det.box, existing.box) > iouThreshold {
shouldKeep = false
break
}
}
if shouldKeep {
kept.append(det)
}
}
return kept
}
/// Compute Intersection over Union between two boxes [x1, y1, x2, y2].
private func computeIoU(_ a: [Int], _ b: [Int]) -> Float {
let x1 = max(a[0], b[0])
let y1 = max(a[1], b[1])
let x2 = min(a[2], b[2])
let y2 = min(a[3], b[3])
let interW = max(0, x2 - x1)
let interH = max(0, y2 - y1)
let interArea = Float(interW * interH)
let areaA = Float((a[2] - a[0]) * (a[3] - a[1]))
let areaB = Float((b[2] - b[0]) * (b[3] - b[1]))
let unionArea = areaA + areaB - interArea
guard unionArea > 0 else { return 0 }
return interArea / unionArea
}
原因2:全クラスをOCRに送っていた
DEIMv2モデルは17クラスのレイアウト要素を検出します。
| カテゴリ | クラス名 | 用途 |
|---|---|---|
| 行(テキスト認識対象) | line_main, line_header, line_caption, line_title など | OCR対象 |
| ブロック(構造情報) | text_block, block_fig, block_pillar, block_rubi など | 構造アノテーション |
本家ndlocr-liteでは、line_*で始まるクラスのみをテキスト認識に送ります。text_blockはページ内の段落領域を表す矩形で、個別の行と物理的に重なるため、これをOCRに送ると同じテキストが二重に認識されてしまいます。
iOS実装では全クラスを区別なくOCR認識に送っていたため、text_blockとline_mainの両方が認識対象になり、重複テキストが発生していました。
修正:line_*クラスのフィルタリング
OCREngine.swiftのprocessNDL()で、検出結果をline_*クラスのみにフィルタリングするようにしました。
// OCREngine.swift — processNDL()
// Step 1: Layout detection
let allDetections = try await Task.detached(priority: .userInitiated) {
try detector.detect(image: image)
}.value
// Filter to line_* classes only (text_block and block_* are structural, not for OCR)
let detections = allDetections.filter { $0.className.hasPrefix("line_") }
この1行のフィルタリングにより、text_blockやblock_figなどの構造情報は検出結果に残りつつも、OCR認識の対象からは除外されます。将来的にレイアウト構造を可視化する機能を追加する際には、allDetectionsを活用できます。
原因3:検出パラメータの差異
本家ndlocr-liteとiOS実装でパラメータが異なっていました。
| パラメータ | 本家ndlocr-lite | iOS(修正前) | iOS(修正後) |
|---|---|---|---|
| scoreThreshold | 0.2 | 0.25 | 0.2 |
| maxDetections | 100 | 300 | 100 |
| iouThreshold (NMS) | 0.2 | なし | 0.2 |
特にiouThresholdが存在しなかったことが致命的でした。scoreThresholdを0.25にしていたのは、NMSがない状態でノイズを減らそうとした名残だったと思われますが、本来はNMSで重複を除去すべきです。
修正:パラメータの統一
// OCREngine.swift — loadNDLModels()
self.ndlDetector = try DEIMDetector(
env: env, modelPath: detModelPath, configPath: configPath,
scoreThreshold: 0.2, confThreshold: 0.25,
iouThreshold: 0.2, maxDetections: 100
)
DEIMDetectorの初期化時にイニシャライザのデフォルト値として本家と同じパラメータを設定しています。
// DEIMDetector.swift
init(env: ORTEnv, modelPath: String, configPath: String,
scoreThreshold: Float = 0.2, confThreshold: Float = 0.25,
iouThreshold: Float = 0.2, maxDetections: Int = 100) throws {
修正結果
校異源氏物語の序文ページで比較した結果です。
| 修正前 | 修正後 | |
|---|---|---|
| 検出数 | 28件(text_block含む) | 17件(line_*のみ) |
| 重複テキスト | あり | なし |
| 本家との一致 | 不一致 | 一致 |
修正前はtext_blockが個別の行と重複して検出され、同じテキストが繰り返し認識されたり、矩形が大きすぎて文字化けしたりしていました。修正後は本家ndlocr-liteと同等の17件の行検出のみとなり、クリーンなOCR結果が得られるようになりました。
まとめ
iOS上でONNXモデルを動かす際、Pythonの本家実装との差異が思わぬバグを生むことがあります。今回の教訓をまとめます。
- ONNXモデルの出力を過信しない — モデルがNMSを内包しているとは限らない。本家の後処理コードを必ず確認する
- 検出クラスの用途を理解する — レイアウト検出モデルは構造情報(ブロック)と認識対象(行)を同時に出力する。すべてをOCRに送ると重複が発生する
- パラメータは本家に合わせる — 閾値の微妙な違いが結果に大きく影響する。特にNMSのIoU閾値は検出品質に直結する
本家ndlocr-liteのPythonコードとiOS(Swift + ONNX Runtime)の実装を丁寧に突き合わせることで、同等の検出精度を実現できました。