KotenOCR: 近代OCRの検出重複を解消する(NMS追加とクラスフィルタリング)
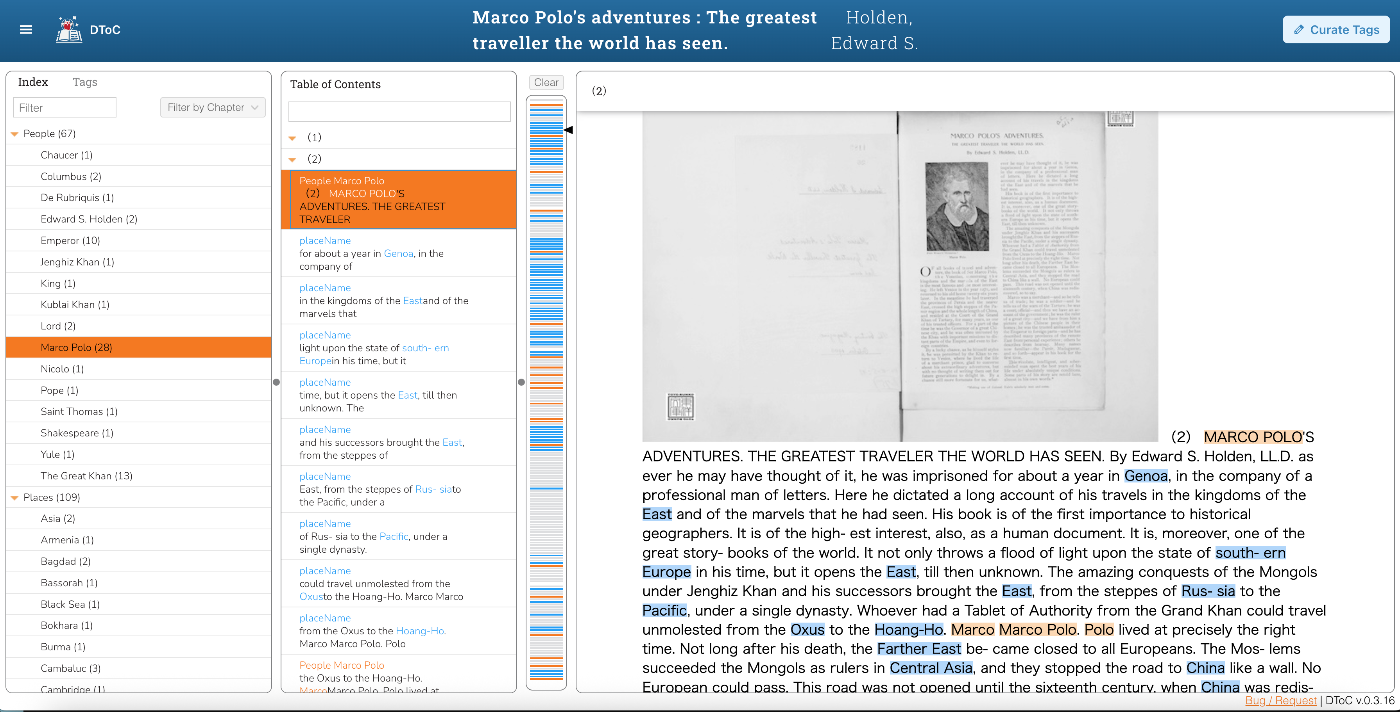
はじめに KotenOCRは、国立国会図書館(NDL)が公開したOCRモデルをiOS上で動作させ、くずし字や近代活字をオフラインで認識するアプリです。 近代OCRモード(NDLモード)では、NDLのDEIMv2-Sモデルでレイアウト検出を行い、PARSeQで文字認識を行います。しかし、iOS実装の検出結果が本家のndlocr-liteと比べて明らかに多く、テキストが重複して認識されるという問題がありました。 本記事では、原因の調査から修正までの過程を記録します。 症状:検出数が多すぎる テスト画像として、NDLデジタルコレクションから取得した「校異源氏物語」の序文ページを使いました。 本家ndlocr-liteでは17件の行検出(line_main、line_captionなど)が得られるのに対し、iOS実装では28件の検出が返り、OCR結果にも重複テキストや文字化けが混入していました。 検出数が多い原因は大きく3つありました。 原因1:NMS(Non-Maximum Suppression)が未実装だった DEIMv2モデルのONNX出力は、内部でNMSを完了した結果を返すと想定していました。しかし本家ndlocr-liteのコードを読むと、モデル推論後に追加のNMS(IoU閾値=0.2)を適用していることがわかりました。 つまり、モデル出力にはまだ重複する矩形が含まれており、後処理でそれを除去する必要があったのです。 修正:NMSの追加 DEIMDetector.swiftにNMS処理を追加しました。 // DEIMDetector.swift — postprocess() の末尾 // Sort by score descending let sorted = detections.sorted { $0.score > $1.score } // Apply NMS to remove overlapping detections let nmsResult = applyNMS(sorted, iouThreshold: iouThreshold) return Array(nmsResult.prefix(maxDetections)) NMS本体の実装は以下のとおりです。スコア降順にソートされた検出結果を走査し、既に採用した矩形とのIoUが閾値を超える場合は除外します。 // DEIMDetector.swift /// Apply Non-Maximum Suppression to remove overlapping detections. private func applyNMS(_ detections: [Detection], iouThreshold: Float) -> [Detection] { var kept: [Detection] = [] for det in detections { var shouldKeep = true for existing in kept { if computeIoU(det.box, existing.box) > iouThreshold { shouldKeep = false break } } if shouldKeep { kept.append(det) } } return kept } /// Compute Intersection over Union between two boxes [x1, y1, x2, y2]. private func computeIoU(_ a: [Int], _ b: [Int]) -> Float { let x1 = max(a[0], b[0]) let y1 = max(a[1], b[1]) let x2 = min(a[2], b[2]) let y2 = min(a[3], b[3]) let interW = max(0, x2 - x1) let interH = max(0, y2 - y1) let interArea = Float(interW * interH) let areaA = Float((a[2] - a[0]) * (a[3] - a[1])) let areaB = Float((b[2] - b[0]) * (b[3] - b[1])) let unionArea = areaA + areaB - interArea guard unionArea > 0 else { return 0 } return interArea / unionArea } 原因2:全クラスをOCRに送っていた DEIMv2モデルは17クラスのレイアウト要素を検出します。 ...