Overview
KotenOCR v1.3.0 is now available. In addition to the existing classical Japanese text (kuzushiji) OCR, this release adds support for modern printed and handwritten Japanese text using the NDLOCR-Lite model.
App Store (free): https://apps.apple.com/jp/app/kotenocr/id6760045646
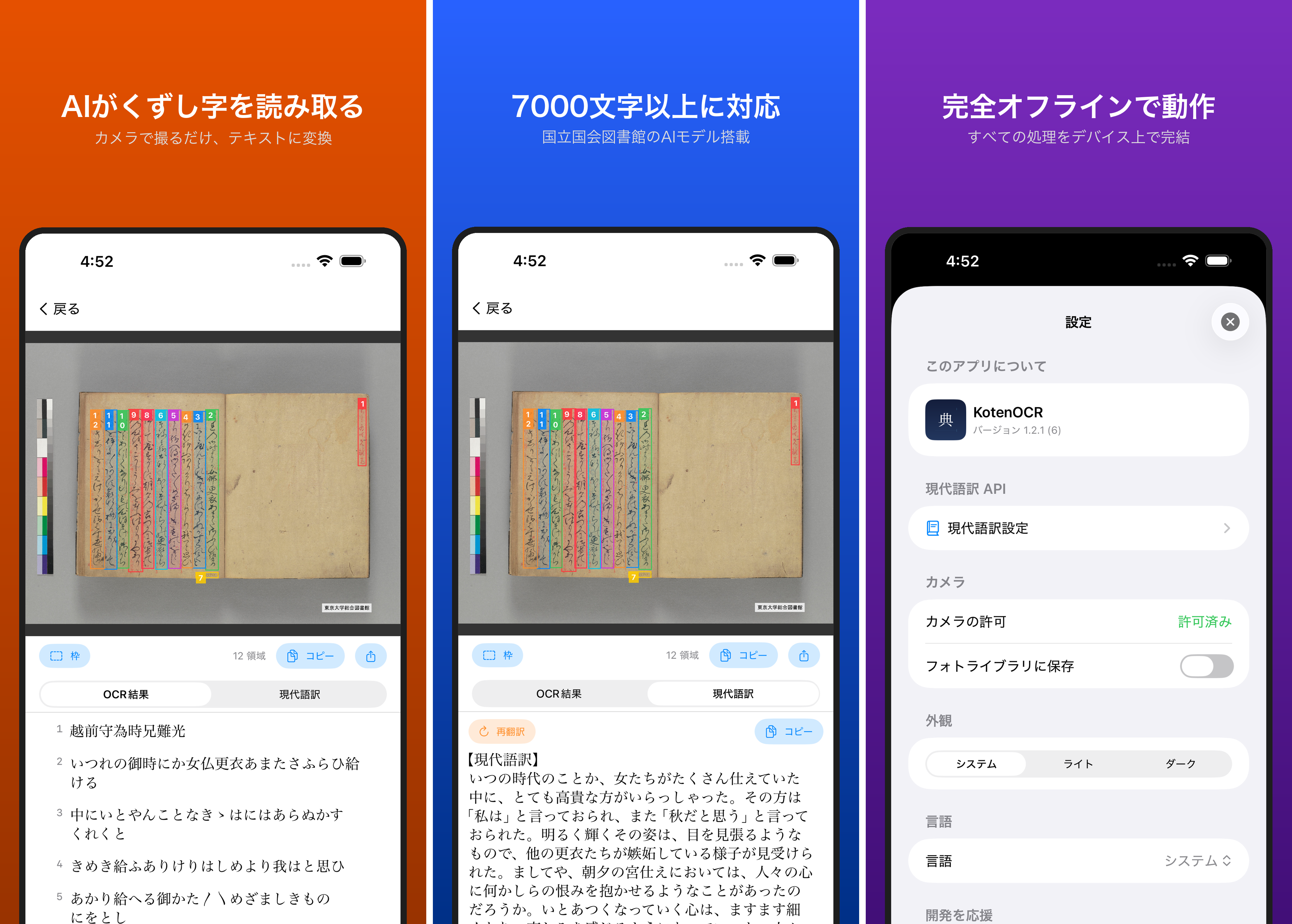
What’s New in v1.3.0
The main changes are as follows:
- NDLOCR-Lite (modern printed text OCR) support. Users can switch between Classical and Modern OCR modes
- One-tap OCR mode selection on the confirm screen — no need to open a settings menu
- Back button from the result screen returns to the confirm screen for re-OCR with a different mode
- Parallelized recognition (1.4x speedup for Classical, 6.7x for Modern)
- Splash screen
- Feedback email with device info
- Crash risk fixes (safe array access, removed force unwraps)
Two OCR Modes
v1.3.0 provides two modes depending on the type of document being scanned.
| Mode | Target | Detection Model | Recognition Model | Source |
|---|---|---|---|---|
| Classical | Kuzushiji (cursive script) | RTMDet-S | PARSeq (1 model) | NDL Koten OCR-Lite |
| Modern | Printed & handwritten | DEIMv2-S | PARSeq cascade (3 models) | NDLOCR-Lite |
The Classical mode targets pre-modern manuscripts written in cursive kana and kanji. The Modern mode targets printed books and handwritten documents from the Meiji period onward.
In Modern mode, a cascade approach automatically selects from three PARSeq models (30-char, 50-char, 100-char) based on the predicted length of each text region.
Performance Improvement from Parallelization
Recognition processing is parallelized using withThrowingTaskGroup, improving throughput. The following benchmarks were measured on the iOS Simulator.
Classical (Genji Monogatari, 21 regions)
| Method | Time |
|---|---|
| Sequential | 4.55s |
| Parallel | 3.24s |
| Speedup | 1.4x |
Modern (NDL Digital Collections, 98 regions)
| Method | Time |
|---|---|
| Sequential | 7.59s |
| Parallel | 1.13s |
| Speedup | 6.7x |
The Modern mode benefits more from parallelization due to the larger number of regions. Swift Concurrency’s cooperative thread pool limits concurrency to the number of CPU cores. With fewer regions (21), lock contention overhead in ONNX Runtime sessions is relatively higher, limiting the speedup to 1.4x. With more regions (98), the available cores are utilized more efficiently, yielding a 6.7x speedup. For more details on the parallelization approach, see the related post.
Note that these measurements were taken on the iOS Simulator; performance on physical devices may differ.
Open Source
The repository is public on GitHub under the MIT License.
Links
- App Store: https://apps.apple.com/jp/app/kotenocr/id6760045646
- GitHub: https://github.com/nakamura196/koten-ocr-ios
- NDL Koten OCR-Lite: https://github.com/ndl-lab/ndlkotenocr-lite
- NDLOCR-Lite: https://github.com/ndl-lab/ndlocr-lite