はじめに
IIIF(International Image Interoperability Framework)は、デジタルアーカイブの画像を相互運用可能な形で公開するための国際標準です。世界中の図書館・博物館が採用しており、高解像度画像の深層ズームや、異なる機関のコレクションを横断的に閲覧することを可能にしています。
本記事では、IIIF画像の一部領域にAI生成動画を重ねて表示する「IIIF Animated Viewer」を開発した過程を紹介します。題材は東京大学が公開する「百鬼夜行図」――妖怪たちの行列を描いた絵巻物です。
静止画の妖怪たちが、ゆらゆらと動き出す。そんな体験を、IIIF標準の枠組みの中で実現しました。
狙い
1. 絵巻物に「動き」を与える
絵巻物は本来、巻きながら読む動的なメディアです。右から左へ進む行列、風にはためく衣、揺れる炎――静止画でありながら動きを内包しています。AI動画生成でその潜在的な動きを顕在化させることで、作品の新しい鑑賞体験を提供できるのではないか、という着想がありました。
2. IIIF標準に準拠する
独自フォーマットではなく、IIIF Presentation API 3.0のマニフェストとして動画情報を記述します。これにより、他のIIIFビューアとの互換性を保ちつつ、既存のIIIFエコシステムに乗る形で動画アノテーションを提供できます。
3. 汎用的なパイプラインにする
百鬼夜行図だけでなく、他のIIIF資料にも適用可能な仕組みを目指しました。マニフェストのメタデータと全体画像からコンテキストを自動生成し、個別領域のプロンプト生成に反映するアーキテクチャにしています。
デモ
デモは GitHub Pages で公開しています。
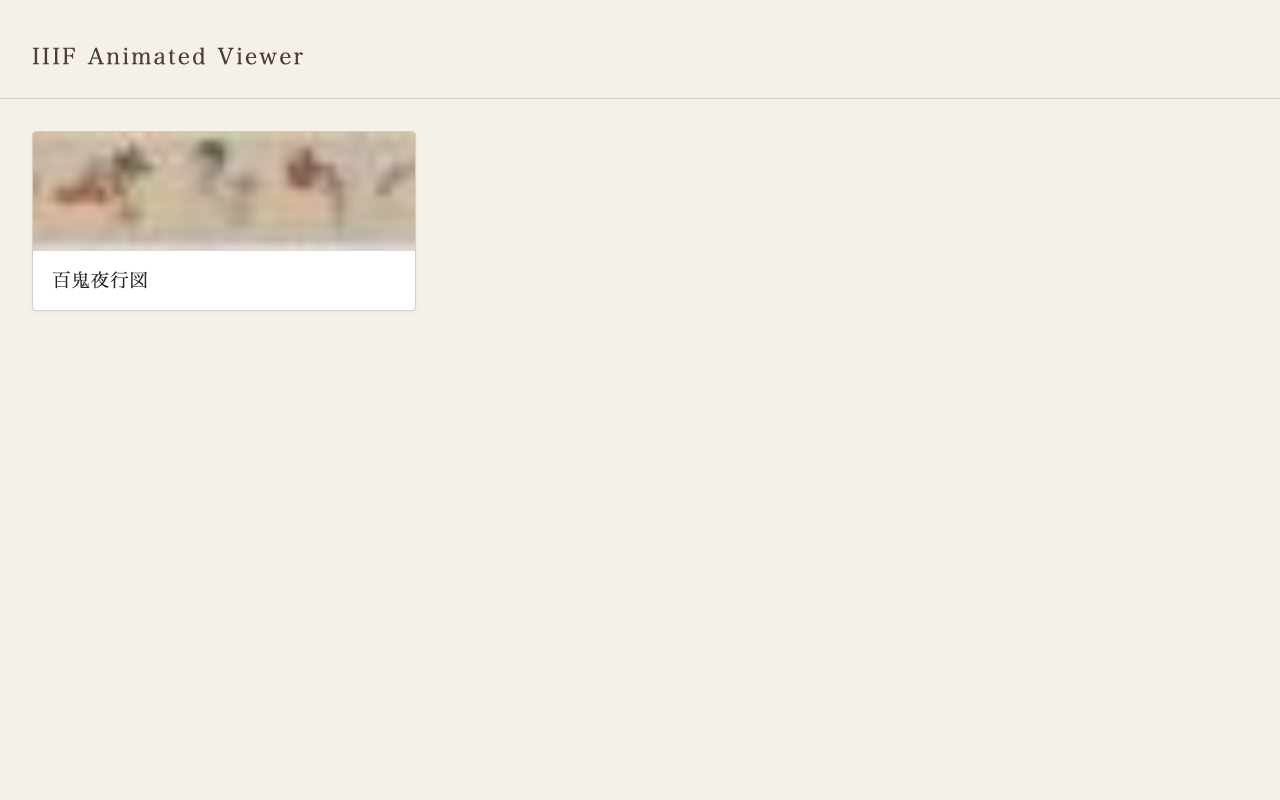 コレクション一覧ページ。IIIFコレクションからマニフェスト一覧を読み込み、サムネイル付きで表示する。
コレクション一覧ページ。IIIFコレクションからマニフェスト一覧を読み込み、サムネイル付きで表示する。
 ビューア全体表示。百鬼夜行図の全体像がOpenSeadragonで表示され、下部に再生ボタンがある。
ビューア全体表示。百鬼夜行図の全体像がOpenSeadragonで表示され、下部に再生ボタンがある。
 ズームすると個々の妖怪が確認でき、動画オーバーレイが元画像の上に重なって表示される。
ズームすると個々の妖怪が確認でき、動画オーバーレイが元画像の上に重なって表示される。
システム構成
docs/ … GitHub Pages公開ディレクトリ
index.html … コレクション一覧ページ
viewer.html … OpenSeadragon + 動画オーバーレイビューア
collection.json … IIIF Collection
manifest.json … IIIF Manifest(動画アノテーション含む)
runs/run_002/ … 生成動画ファイル
scripts/
pipeline.py … 一括生成パイプライン
process_raw.py … Veo生成動画のトリミング+manifest更新
workspace/
anno.json … 領域アノテーション(19件)
context.txt … 自動生成コンテキスト
runs/ … 中間データ(クロップ画像、プロンプト等)
IIIFマニフェストでの動画アノテーション
従来のIIIFアノテーション
IIIF Presentation API 3.0では、Canvasに対するアノテーションとして画像を配置します。
{
"type": "Annotation",
"motivation": "painting",
"body": {
"type": "Image",
"id": "https://example.org/image.jpg",
"service": [{ "id": "https://example.org/iiif/image", "type": "ImageService2" }]
},
"target": "https://example.org/canvas/1"
}
動画をアノテーションとして追加する
IIIF 3.0の仕様上、bodyのtypeはImageに限定されていません。VideoやSoundも記述可能です。この仕様を活用し、Canvas上の特定領域に動画をオーバーレイするアノテーションを追加しました。
{
"type": "Annotation",
"motivation": "painting",
"body": {
"id": "runs/run_002/video_005.mp4",
"type": "Video",
"format": "video/mp4",
"width": 978,
"height": 1080
},
"target": "https://example.org/canvas/1#xywh=38601,181,2440,2690"
}
ポイントは以下の通りです。
motivation: "painting":Canvasの視覚的表現に寄与するアノテーションであることを示すbody.type: "Video":bodyが動画リソースであることを宣言targetのフラグメント#xywh=:Canvas上の配置領域をピクセル座標で指定
動きの説明もアノテーションで保存
AI生成プロンプト(動きの説明文)は、describingモチベーションの別のAnnotationPageに保存しています。
{
"type": "Annotation",
"motivation": "describing",
"body": {
"type": "TextualBody",
"value": "A kappa-like demon strides forward with determined steps...",
"language": "en",
"format": "text/plain"
},
"target": "https://example.org/canvas/1#xywh=38601,181,2440,2690"
}
これにより、動画の生成意図やプロンプトもIIIFマニフェスト内に構造化して保持できます。
マニフェスト全体構造
{
"@context": "http://iiif.io/api/presentation/3/context.json",
"type": "Manifest",
"label": { "ja": ["百鬼夜行図"] },
"viewingDirection": "right-to-left",
"items": [{
"type": "Canvas",
"width": 79508,
"height": 3082,
"items": [
{ "type": "AnnotationPage", "items": [/* 元画像(IIIF Image Service) */] }
],
"annotations": [
{ "type": "AnnotationPage", "items": [/* painting: 動画オーバーレイ */] },
{ "type": "AnnotationPage", "items": [/* describing: 動きの説明文 */] }
]
}]
}
items配下のAnnotationPageが元画像(主コンテンツ)、annotations配下が追加の動画・説明文アノテーションという構造です。IIIF標準のitemsとannotationsの役割分担をそのまま活用しています。
ビューアの実装
OpenSeadragonへの動画オーバーレイ
ビューアはOpenSeadragonを使った深層ズーム表示に、HTML <video> 要素を重ねる構成です。
// マニフェストからVideoアノテーションを抽出
for (const anno of videoAnnos) {
const match = anno.target.match(/#xywh=(\d+),(\d+),(\d+),(\d+)/);
const [imgX, imgY, imgW, imgH] = match.slice(1).map(Number);
const video = document.createElement('video');
video.src = anno.body.id;
video.loop = true;
video.muted = true;
osdContainer.appendChild(video);
// ビューポート変更に追従
function updatePosition() {
const viewportRect = viewer.viewport.imageToViewportRectangle(imgX, imgY, imgW, imgH);
const webRect = viewer.viewport.viewportToViewerElementRectangle(viewportRect);
video.style.left = webRect.x + 'px';
video.style.top = webRect.y + 'px';
video.style.width = webRect.width + 'px';
video.style.height = webRect.height + 'px';
}
viewer.addHandler('update-viewport', updatePosition);
viewer.addHandler('animation', updatePosition);
}
OpenSeadragonのimageToViewportRectangleとviewportToViewerElementRectangleを組み合わせることで、画像座標系からブラウザのDOM座標系への変換を行い、ズーム・パンに動画が追従します。
動画のブレンディング
動画の境界が不自然にならないよう、CSSのマスクとフィルタで調整しています。
.video-overlay {
/* 端をフェードアウトさせて元画像に溶け込ませる */
mask-image:
linear-gradient(to right, transparent, black 5%, black 95%, transparent),
linear-gradient(to bottom, transparent, black 5%, black 95%, transparent);
mask-composite: intersect;
/* 元画像の色味に近づける */
filter: brightness(1.05) saturate(0.85);
}
動画生成パイプライン
Phase 0: コンテキスト自動生成
マニフェストのメタデータ(タイトル、説明、閲覧方向等)と全体画像をClaude Visionに入力し、資料の概要を英語で自動生成します。
def ensure_context(manifest, canvas):
"""context.txt が無ければ自動生成する。既存なら再利用。"""
if CONTEXT_PATH.exists():
return CONTEXT_PATH.read_text().strip()
context = generate_context(manifest, canvas)
CONTEXT_PATH.write_text(context)
return context
手動で編集した場合はそちらを優先するため、既存ファイルがあれば再利用します。
Phase 1-2: 領域クロップとプロンプト生成
anno.jsonの各領域に対して、IIIF Image APIで画像を切り出し、コンテキスト+個別画像からアニメーションプロンプトを生成します。
IIIF Image API: {base}/{x},{y},{w},{h}/full/0/default.jpg
プロンプトには以下の要件を含めています。
- 資料全体のコンテキスト(百鬼夜行図であること、右から左への行列等)
- ループ可能な動き(始点と終点が近い状態になるよう)
- 元の画風を維持する指示
Phase 3: 動画生成
当初はReplicate経由のMiniMax video-01を使用しましたが、最終的にはGoogle Veo(Flow GUI)を採用しました(後述の試行錯誤を参照)。
試行錯誤
AI動画生成モデルの選定
本プロジェクトでは、複数の動画生成モデルを試しました。
MiniMax video-01(Replicate経由)
最初に採用したモデルです。APIで自動化でき、7本の動画を生成できました。しかし以下の問題がありました。
- 無料枠の制限に早期に到達(402エラー)
- 一部の妖怪が「センシティブコンテンツ」として拒否される
- 極端なアスペクト比(縦長すぎる領域)を受け付けない
Google Veo
Veo APIも試みましたが、APIのクォータが0で利用不可でした。ただし、Google AI Studioの「Flow」GUIからは生成可能だったため、半自動ワークフローに切り替えました。
アスペクト比の問題
絵巻物のクロップ領域は様々なアスペクト比を持ちますが、Veoは16:9のみ対応です。そこで以下のワークフローを構築しました。
- 入力前:元画像を16:9にパディング(余白を追加)
- Veoで動画生成:16:9の動画として出力
- 出力後:ffmpegでパディング部分をクロップして元のアスペクト比に戻す
def get_padded_size(orig_w, orig_h):
"""16:9 パディング後のサイズとオフセットを計算する。"""
target_h = int(orig_w * 9 / 16)
if target_h < orig_h:
target_w = int(orig_h * 16 / 9)
target_h = orig_h
else:
target_w = orig_w
return target_w, target_h, pad_x, pad_y
キャラクター一貫性の問題
初期の生成では、動画の途中で妖怪の外見が変わってしまう(例:色が変わる、形が変形する)問題がありました。プロンプトに以下の指示を追加することで改善しました。
"Maintain the exact appearance of the original figure throughout the animation. Do not change, morph, add, or replace any characters."
プロンプトの改善
プロンプトは段階的に改良しました。
- 初期:個別画像のみから動きを記述 → 文脈が不足
- コンテキスト追加:資料全体の情報を事前に生成して各プロンプトに注入
- ループ指示追加:「始点に戻る循環的な動き」を明示
- 一貫性指示追加:キャラクターの外見変化を禁止
- 画風指示追加:「元の作品のスタイルでの穏やかなアニメーション」で締める
まとめ
動画アノテーションの可能性
IIIF Presentation API 3.0で動画をアノテーションとして記述する手法は、まだ広く普及していません。しかし、仕様としてはすでにサポートされており、以下のような応用が考えられます。
- 絵巻物・絵画の部分アニメーション:本記事で紹介したアプローチ
- 古地図上の動態表示:歴史地図上に時代ごとの変遷を動画で重ねる
- 修復過程の可視化:修復前後の変化を動画として記録し、対応領域に紐付ける
技術的なポイント
- IIIF標準の
annotationsにVideoアノテーションを追加するだけで、既存のマニフェスト構造を壊さない paintingモチベーションで視覚的オーバーレイ、describingモチベーションでメタデータ保存と使い分ける- OpenSeadragonのビューポート変換APIにより、ズーム・パンと動画を同期できる
- AI生成のコンテキストとプロンプトもマニフェスト内に保存することで、再現性を確保する
リポジトリ
- デモ: GitHub Pages
- ソースコード: GitHub
動画版(生成AIによる自動生成): この記事の内容をずんだもん×四国めたんの掛け合いで解説しています。自動生成のため、内容に誤りがある可能性があります。正確な情報は記事本文をご参照ください。