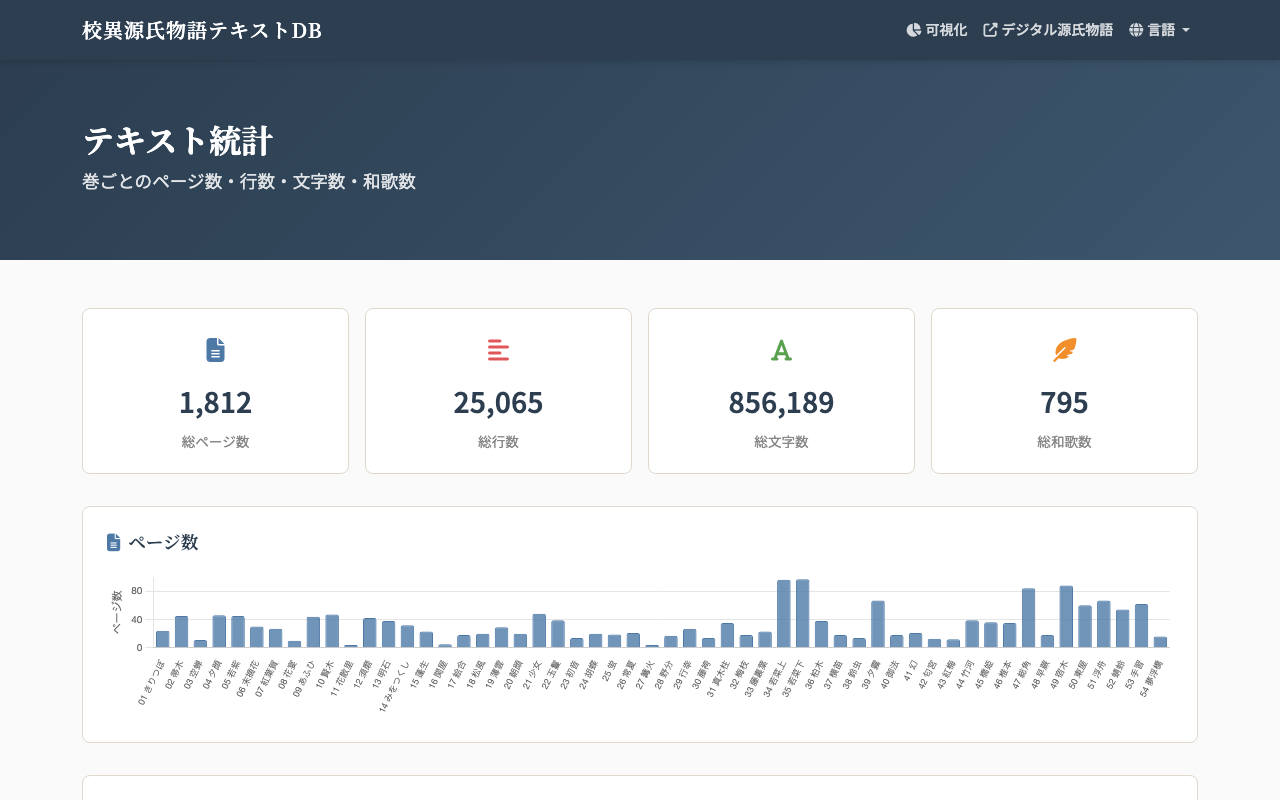
TEI/XMLの翻刻データから統計ページをCI/CDで自動更新する — 『校異源氏物語』テキストDBの事例
TEI/XMLで構造化された翻刻テキストから、巻ごとのページ数・行数・文字数・和歌数を集計する統計ページを生成し、GitHub Actionsで再ビルド・再公開まで自動化する仕組みを紹介します。
teixmldhgithub-actions
TEI/XMLで構造化された翻刻テキストから、巻ごとのページ数・行数・文字数・和歌数を集計する統計ページを生成し、GitHub Actionsで再ビルド・再公開まで自動化する仕組みを紹介します。
東北大学デジタルアーカイブ(touda.tohoku.ac.jp/collection)で利用できる公開 API を調査し、OAI-PMH を使って setSpec 単位でメタデータを取得し Excel に出力する手順を整理しました。
researchmapには公式の書き込みAPIとCSV/JSON/JSONLインポート機能が用意されていますが、個人ユーザーから見るとそれぞれ制約があります。本記事では選択肢を整理した上で、完全自動化とPDF添付に対応するPlaywrightスクリプトの実装を紹介します。
調整さん(chouseisan.com)の出欠回答を Playwright で自動入力し、◯/△/× の判定は Google カレンダーと照合して Claude Code(claude.ai Google Calendar MCP 経由)に任せる構成を作成した記録です。fetch / fill / submit の3段階に分け、判定ルールは CLAUDE.md に記述する形にしました。
国立国会図書館が公開する日本語OCR「NDLOCR-Lite」をCLIではなくPythonスクリプトからimportして呼び出す方法と、その際のハマりどころをまとめます。
YOLOv5の学習済みモデル(best.pt)をHugging Face HubにアップロードしてModel Cardを設定し、Gradio製のデモをSpacesにデプロイするまでの手順と、発生したトラブルの解決策をまとめます。
Zennで公開していた記事を自前ブログに移行する際、Playwrightと非公式APIを使って508記事の本文を移転通知に一括置換した記録です。
デジタル延喜式の開発で、TEI XMLのスタンドオフ注釈をVue.js向けにインライン化する際に遭遇した文書構造崩壊のバグと、DOM操作ベースの解決策についての記録
App Store Connect Sales Reports APIの日次レポート反映時刻とYouTube Data API v3のクォータリセット時刻を実際に観測した記録です。
XCUITestでシミュレータのスクリーンショットを撮影し、PythonのPillowでマーケティング画像を生成、App Store Connect APIでアップロードするまでの全工程をシェルスクリプト1本で自動化する方法を解説します。
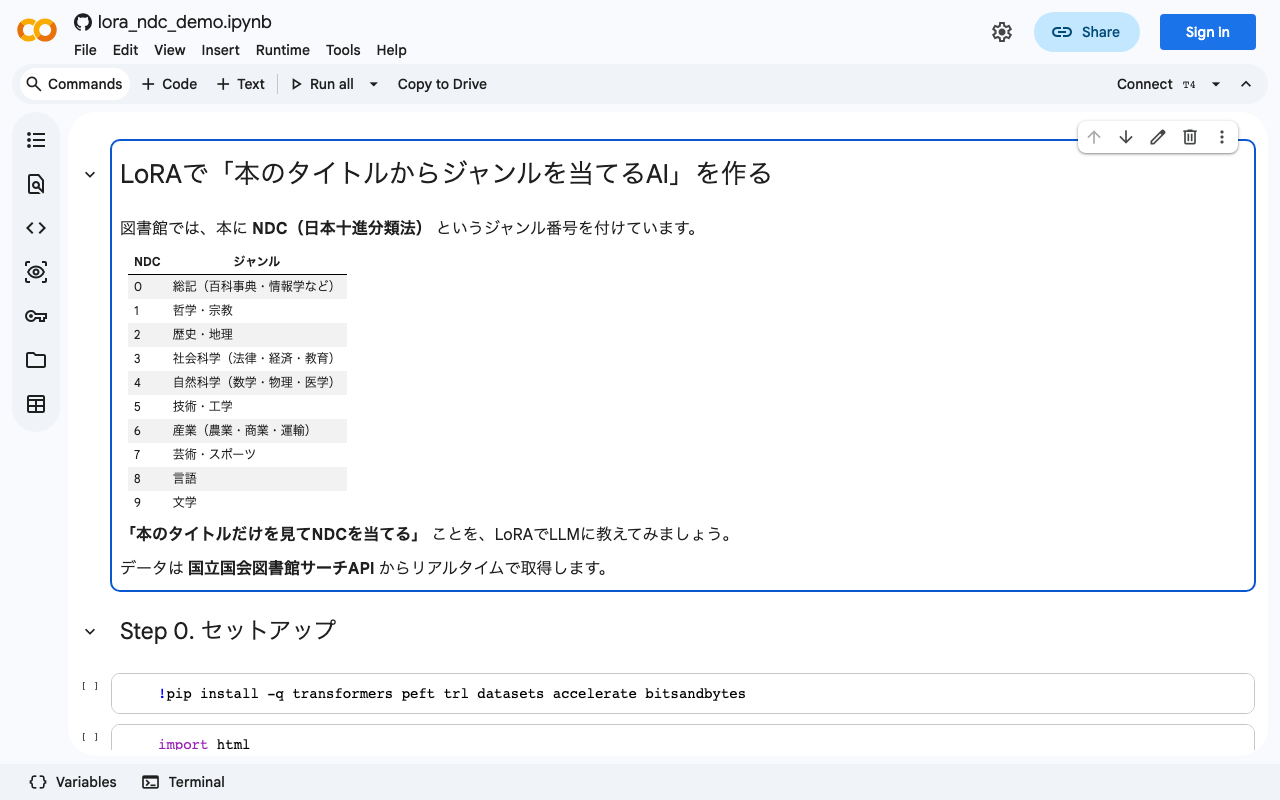
国立国会図書館サーチAPIから書誌データを取得し、LoRAにより小型日本語LLMをファインチューニングすることで、書名のみからNDC(日本十進分類法)の第1次区分を推定するモデルを構築する実践的チュートリアル。

researchmapでは科研費と業績の紐付けをAPI・CSVインポートで行えないため、Playwrightでブラウザ操作を自動化するスクリプトを作成した
App Store Connect REST APIを使い、iOSアプリのアップデート版をビルド・アップロードから審査提出までコマンドラインで完結させる手順を解説する。
StoreKit 2とApp Store Connect APIを使い、iOSアプリにチップ(Tip Jar)機能を実装し、商品登録・ローカライズ・価格設定・スクリーンショットアップロード・TestFlight配信までをコマンドラインから完了させる手順を解説する。
Chrome Headless モードの --screenshot で HTML を画像化する際、画面下部に白い帯が出る原因と、確実な解決方法を紹介します。
Three.js と @pixiv/three-vrm を使ってヘッドレス Chrome 上で VRM モデルをアニメーションさせ、VOICEVOX のリップシンクと組み合わせて VTuber 風解説動画を自動生成するパイプラインの実装メモ。
App Store Connect REST APIを使い、メタデータ・スクリーンショット・年齢レーティング・ビルド紐付けなど審査提出に必要なほぼ全作業をコマンドラインから完了させる手順を解説する。

はてなブログのAtomPub APIを使って、公開済み記事を一括で実質非公開にする方法
OpenITI mARkdownからTEI XMLへの自動変換ツール「oitei」を試す

Deep Zoom画像を完全復元:タイル画像からBigTIFFへの変換技術
GitHub File History Analyzerの紹介:ファイル編集履歴をAIで分析するツール
DHConvalidatorにおける'ref'に関する不具合への対応

ArchivematicaのPreservation planningにおいて、Normalizationのルールを追加する

AtoM(Access to Memory)のAPIを使って、オブジェクトを登録してみる
WordファイルをTEI XMLに変換する方法:TEIgarage APIの活用ガイ
DrupalのJSON:APIを用いて、ユーザ名とパスワードでデータ登録を行う
大きな画像から部分画像の座標を取得する方法
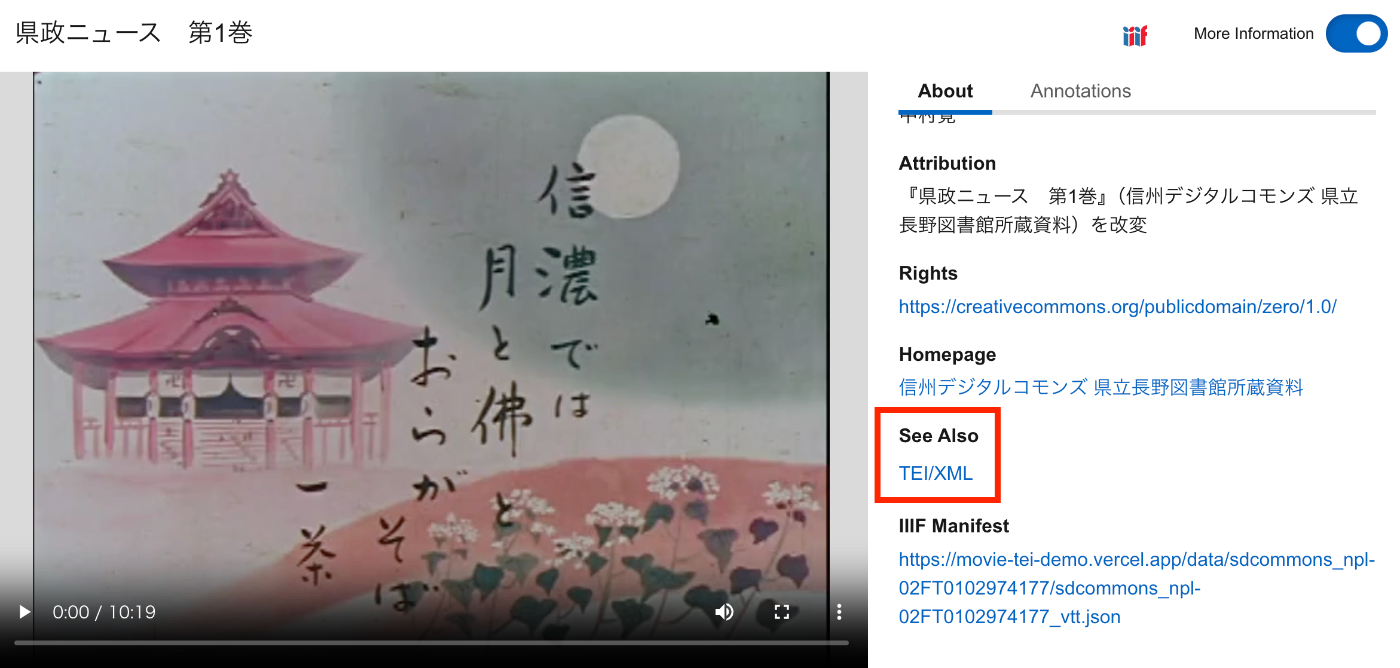
vttファイルからTEI/XMLを作成する
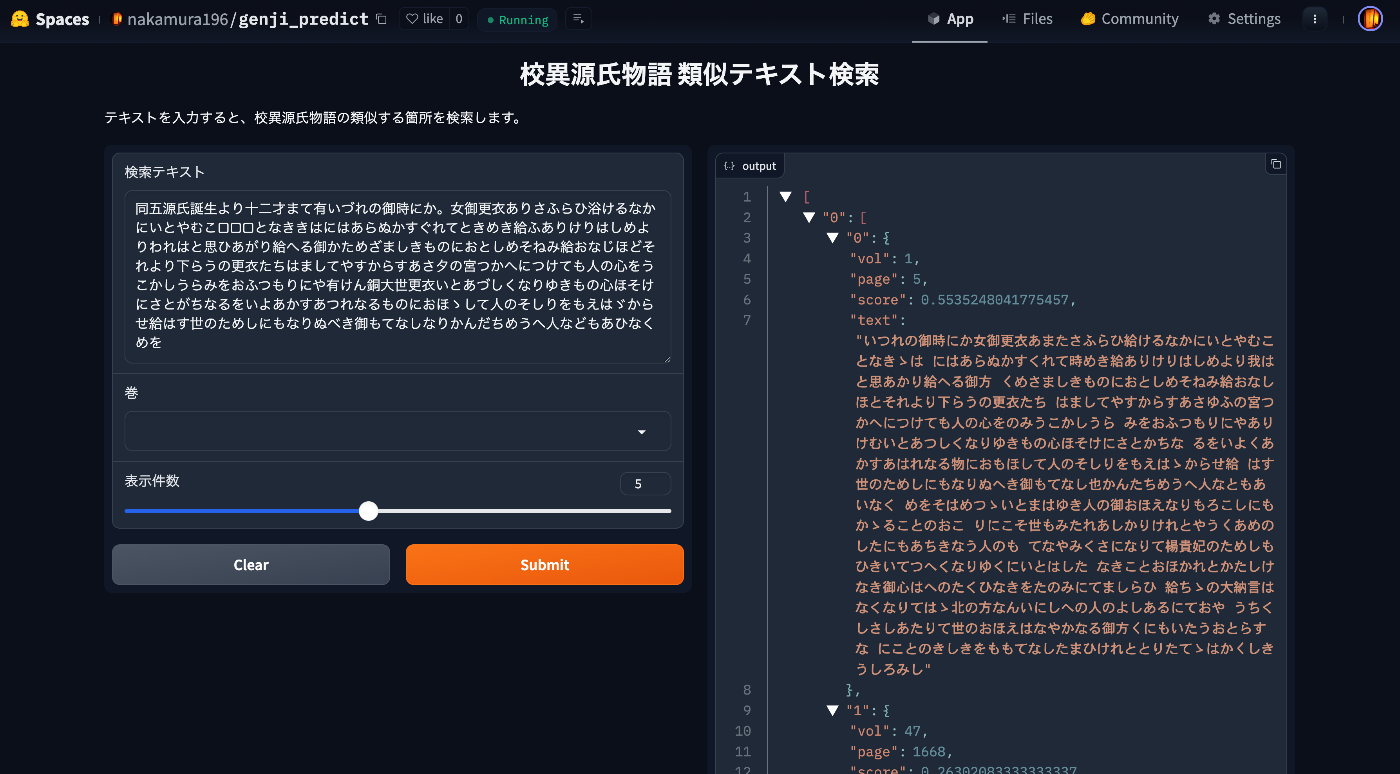
校異源氏物語に対する類似テキスト検索アプリを作成しました。

Alfrescoのファイルに対して、Archivematicaを使ってAIPを作成する
Pythonを使ってOmeka Sにメディアをアップロードする方法

ジオコーディングのライブラリを試す
LLMに関するメモ
GakuNin RDMのAPIを使って、ファイルのアップロードなどを行う

YOLOv11xと日本古典籍くずし字データセットを用いた文字の検出モデルの構築
mdx.jpを用いてYOLOv11のクラス分類(くずし字認識)の学習を試す
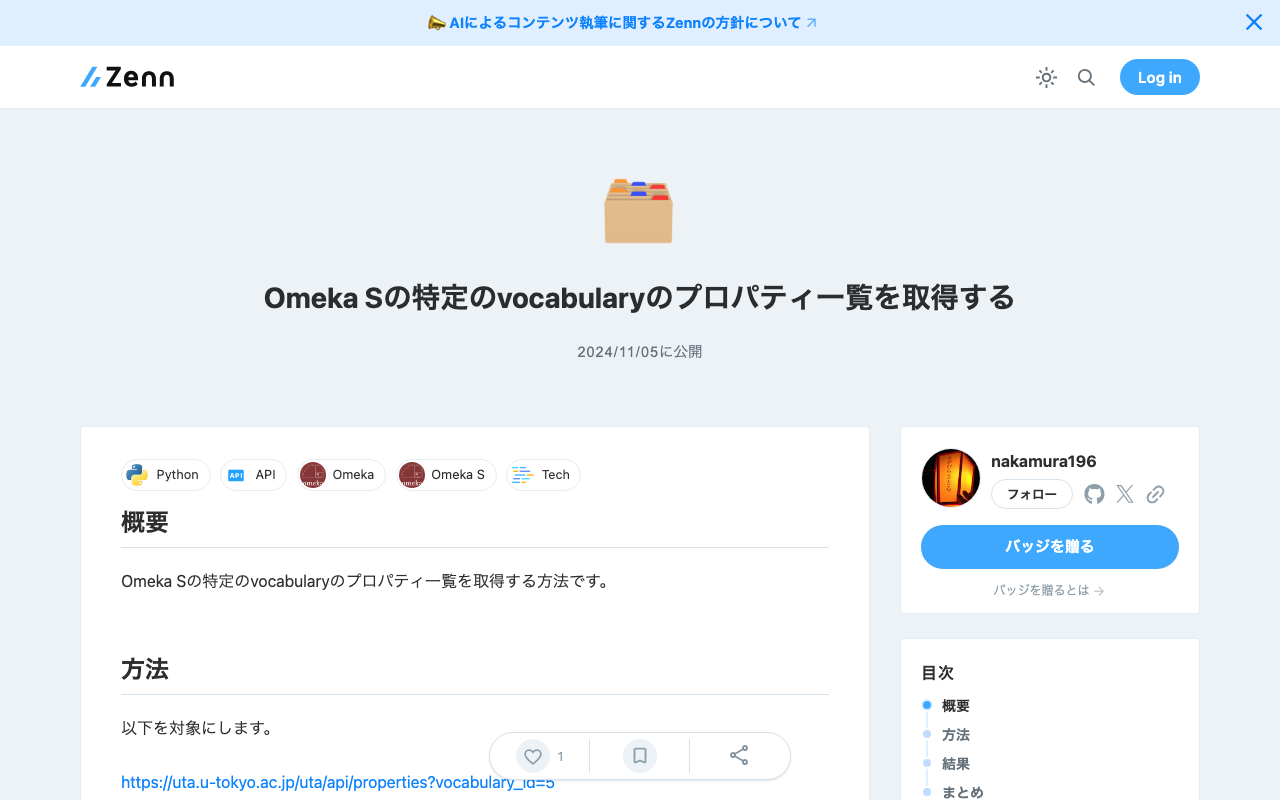
Omeka Sの特定のvocabularyのプロパティ一覧を取得する

Google Cloud Vision APIを用いて、単一ページから構成される透明テキスト付きPDFを作成する
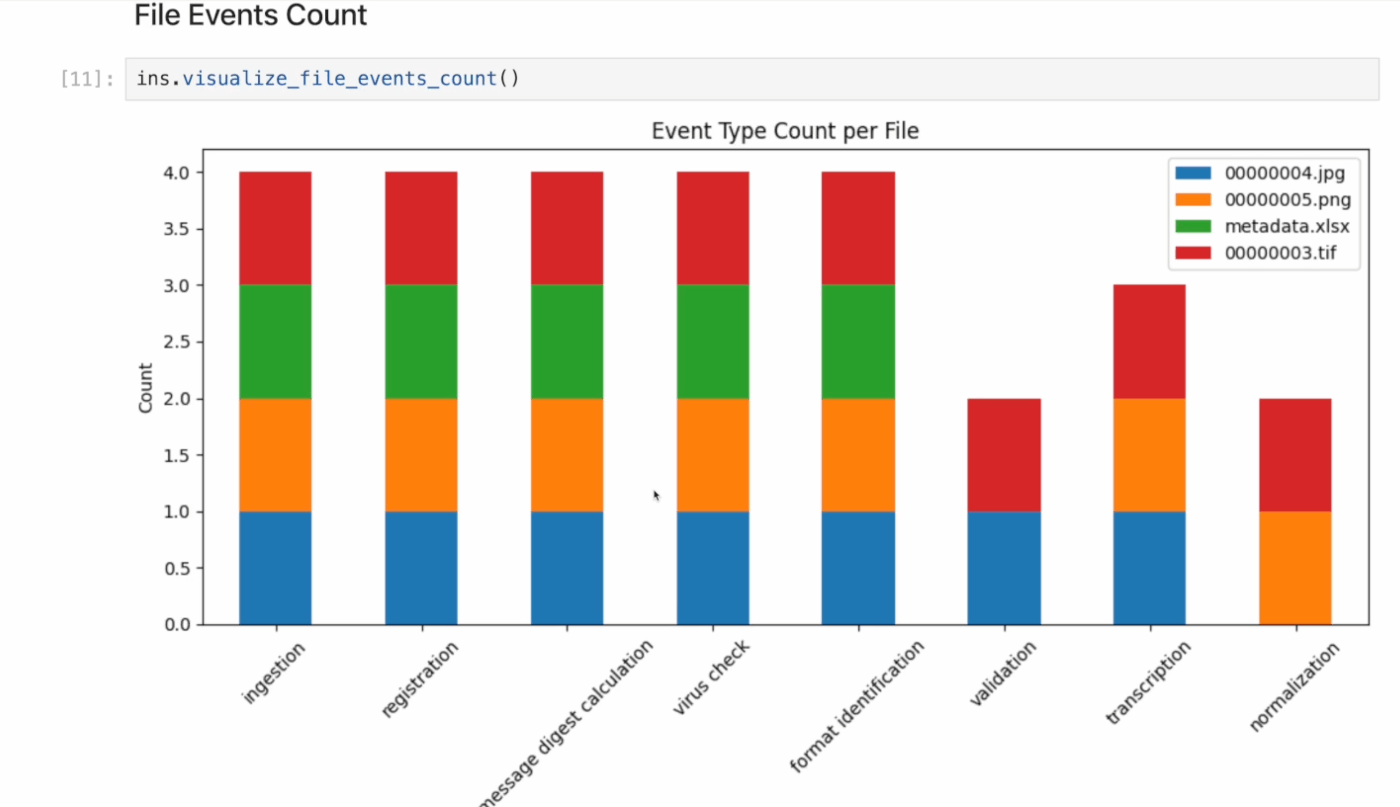
ArchivematicaのMETSファイルの内容を可視化するPythonライブラリ
iiif-prezi3を使って、動画に関するIIIF v3マニフェストを作成する
pythonを使ってcvatのデータを操作する

GUIE(Google Universal Image Embedding)の学習済みモデルを使用して類似画像検索を行う

画像ファイルに対してGoogle Cloud Visionを適用して、IIIFマニフェストおよびTEI/XMLファイルを作成する
Pythonを使ってRDFデータをDydraに登録する
vsdxファイルからrdfファイルを作成するライブラリ
OAI-PMHリポジトリからPythonでレコードを全件取得する

DrupalのREST APIを使って、複数のコンテンツを一括削除する

ZoteroのAPIとStreamlitを使ったアプリ開発
Content Negotiationを使って、PythonでURIからRDFを取得する
iiif-prezi3を試す
「ARC2によるRDFグラフの視覚化」をPythonで利用する
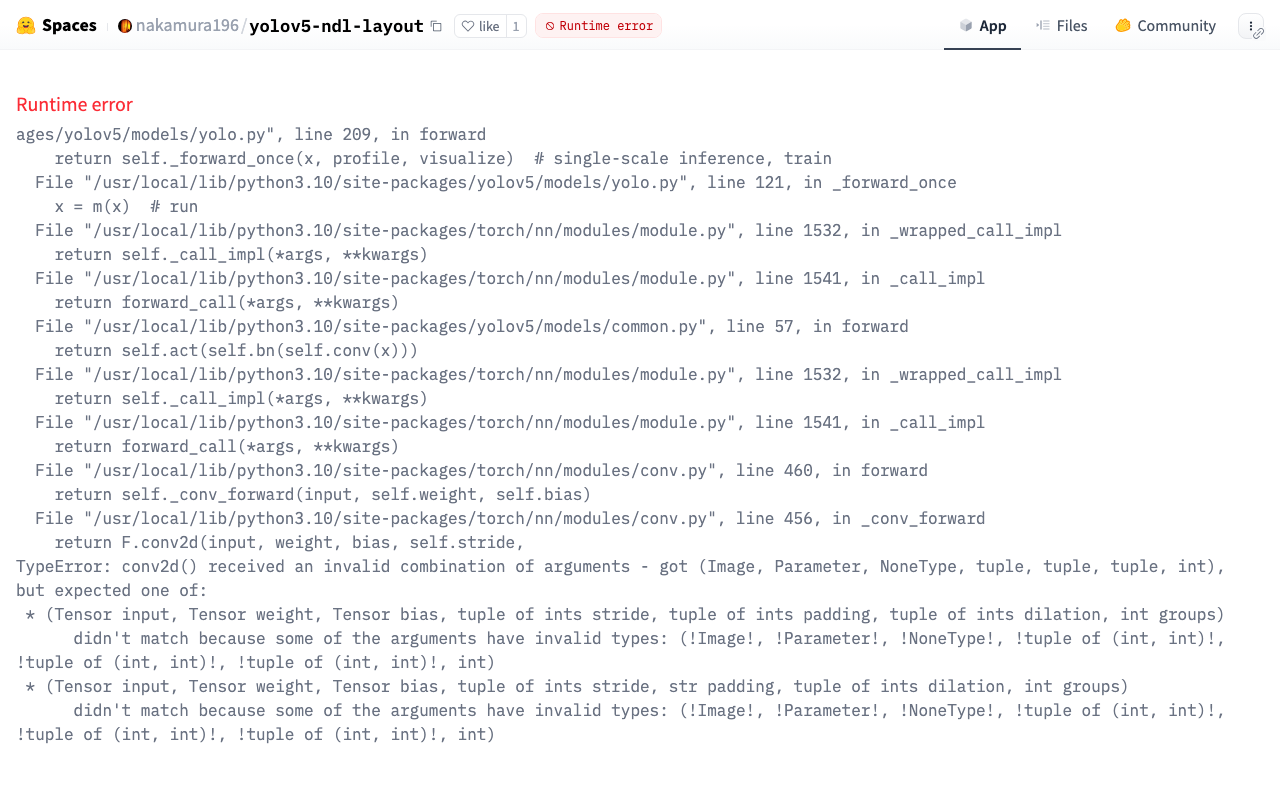
Hugging Face SpacesとYOLOv5モデル(NDL-DocLデータセットで学習済み)を使った推論アプリの修正

PythonでXML文字列を整形する
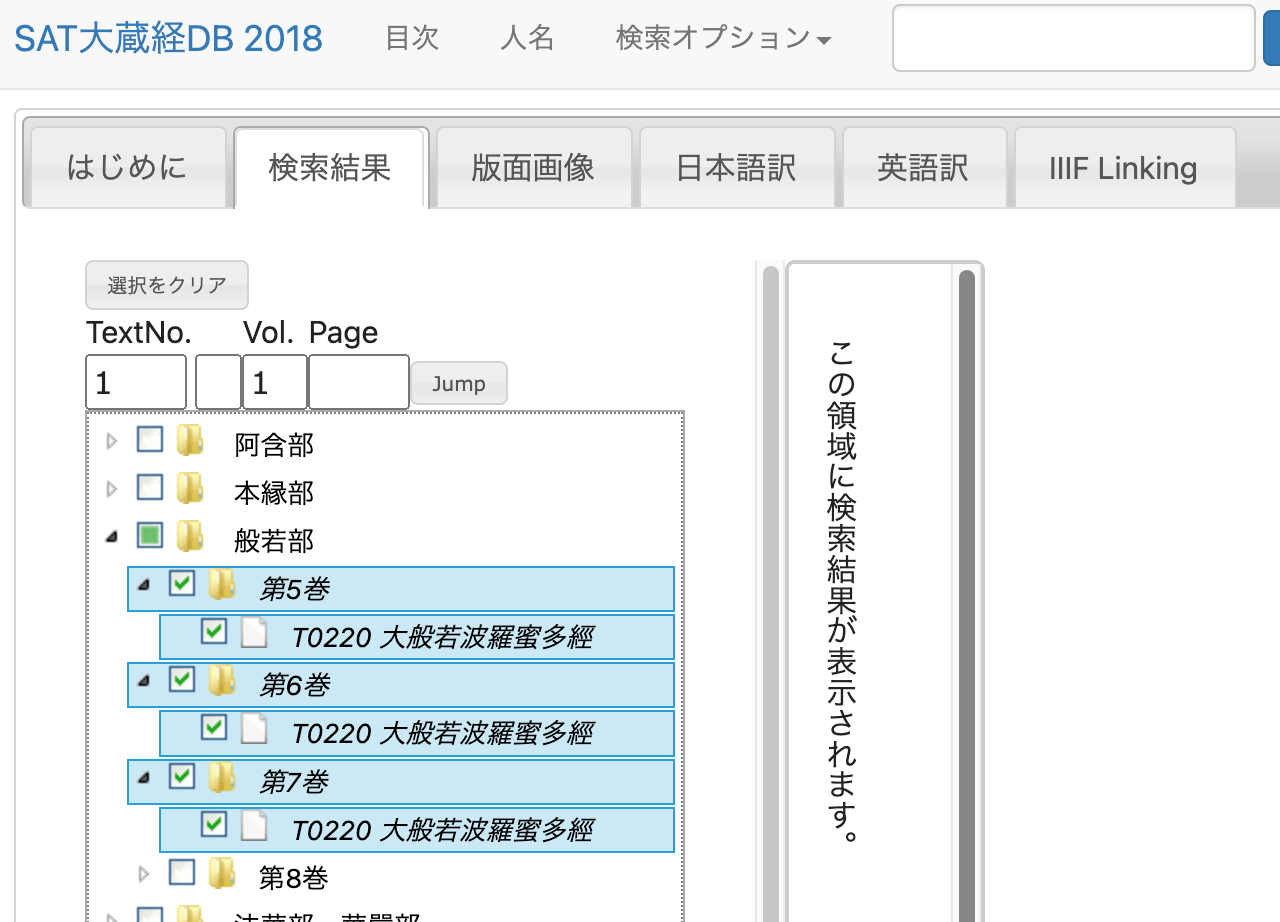
「SAT大蔵経DB 2018」で公開されているテキストの分析例
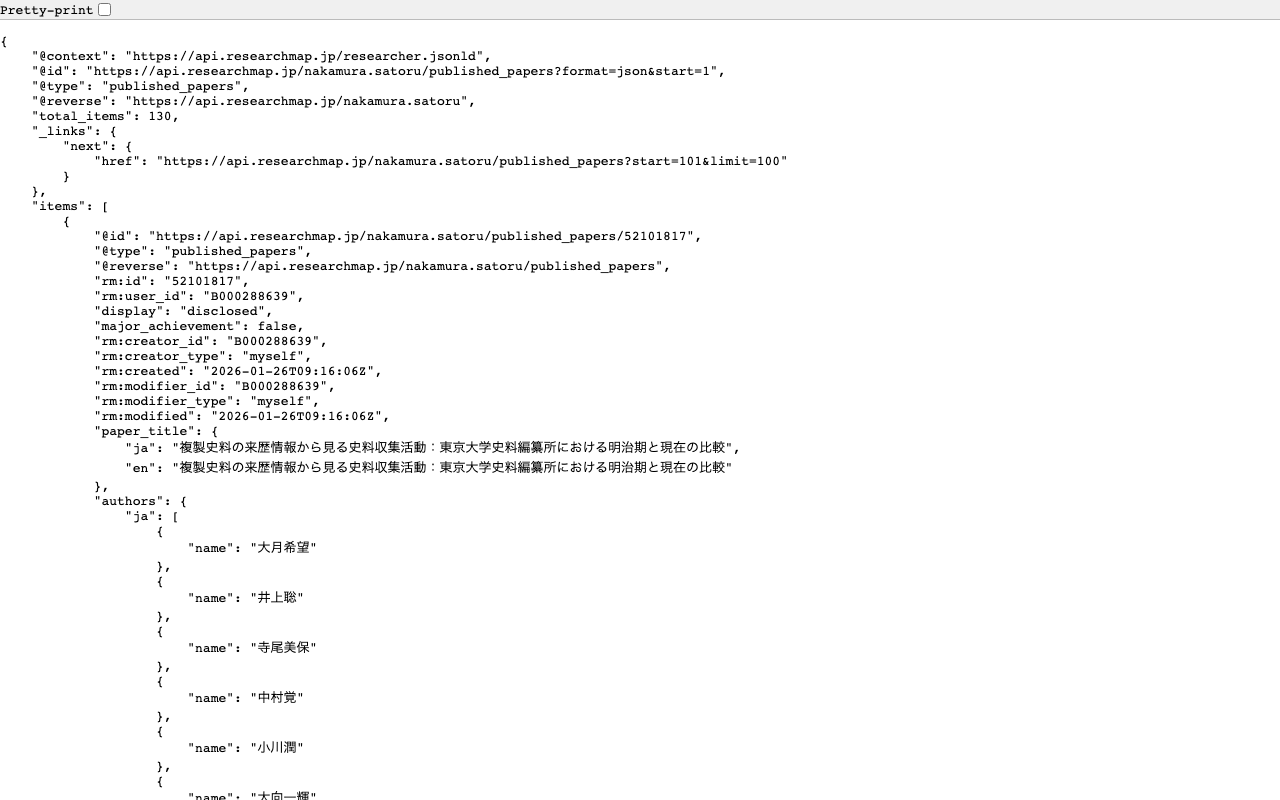
researchmapのapiを使う
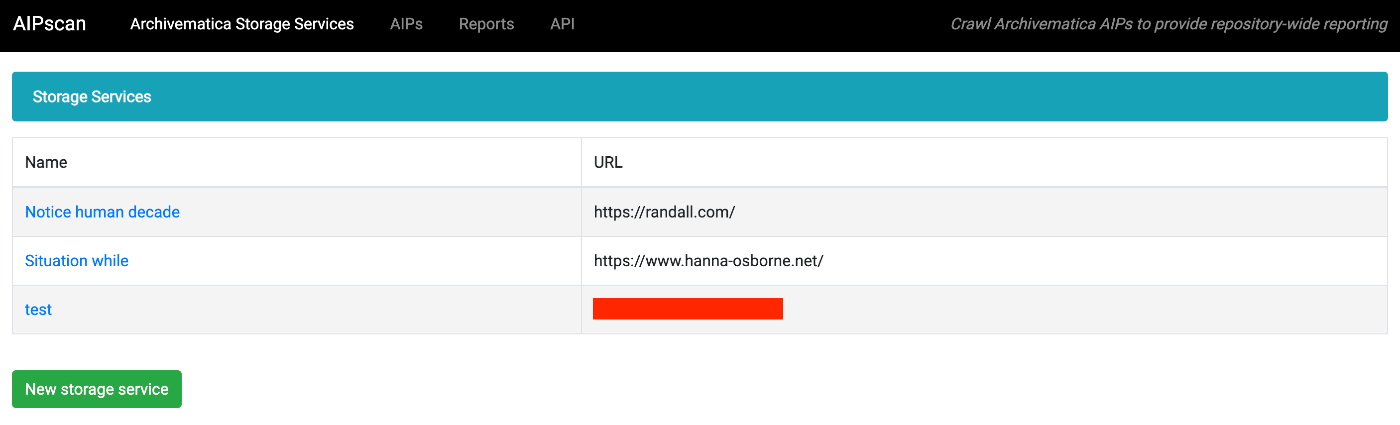
AIPscanを試す

デジタル源氏物語における校異源氏物語と現代語訳の対応づけ
AttributeError: 'ImageDraw' object has no attribute 'textsize'への対応
Amazon SNSを用いたEC2上のVirtuosoの再起動

Google Mapsの短縮URLから緯度経度を取得する際の備忘録
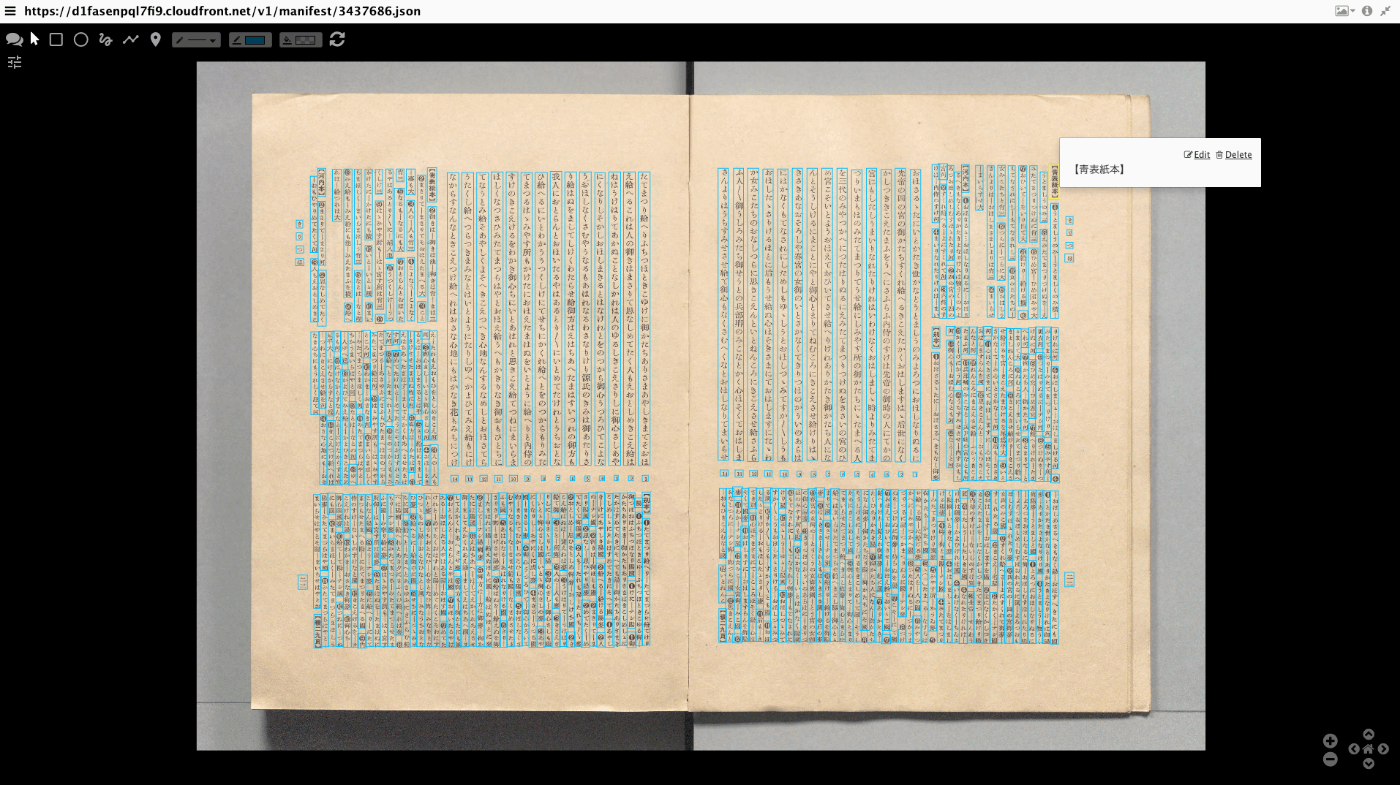
Omeka Classic IIIF Toolkitにデータを一括登録する

WikibaseSyncを試す
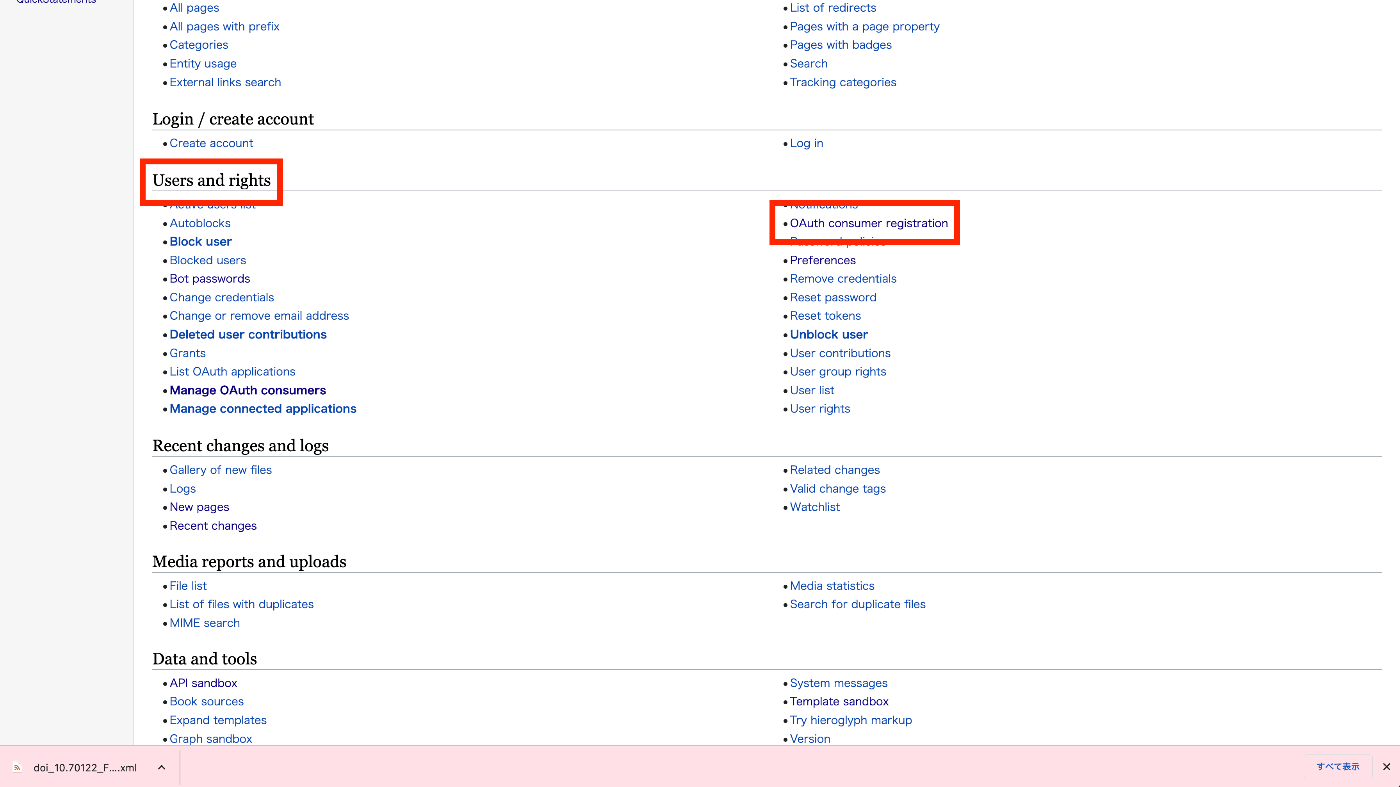
wikibaseのapiをつかってみる

Dataverseを試す
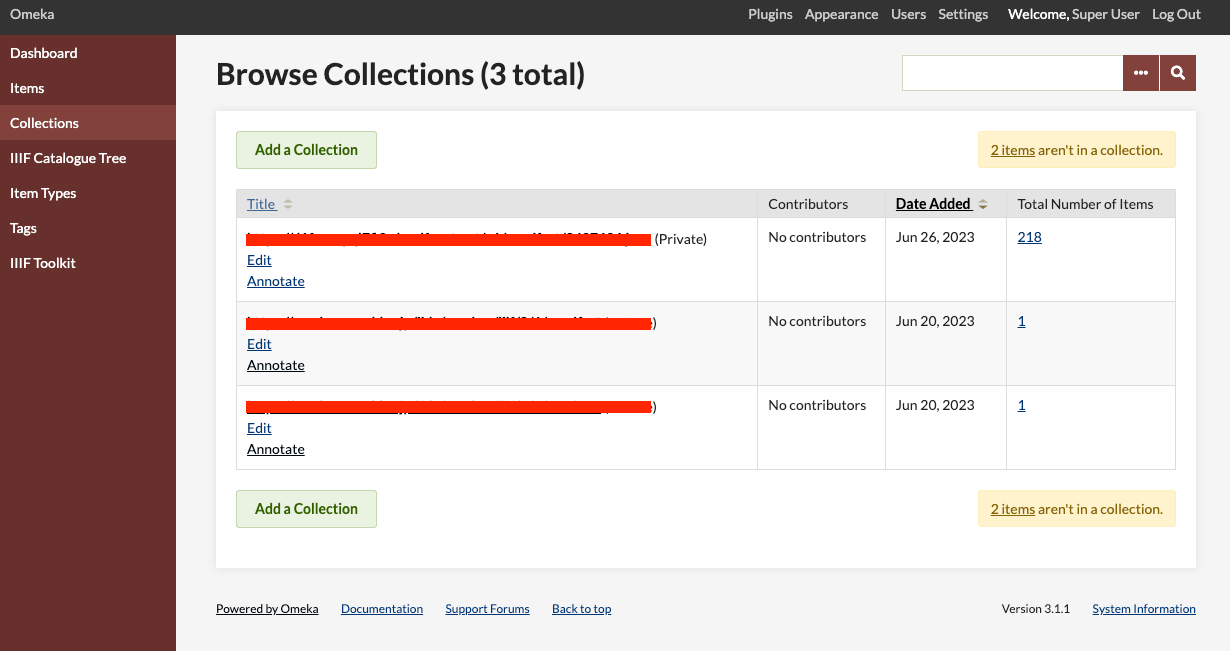
Omeka Classicでコレクションを一括削除する方法
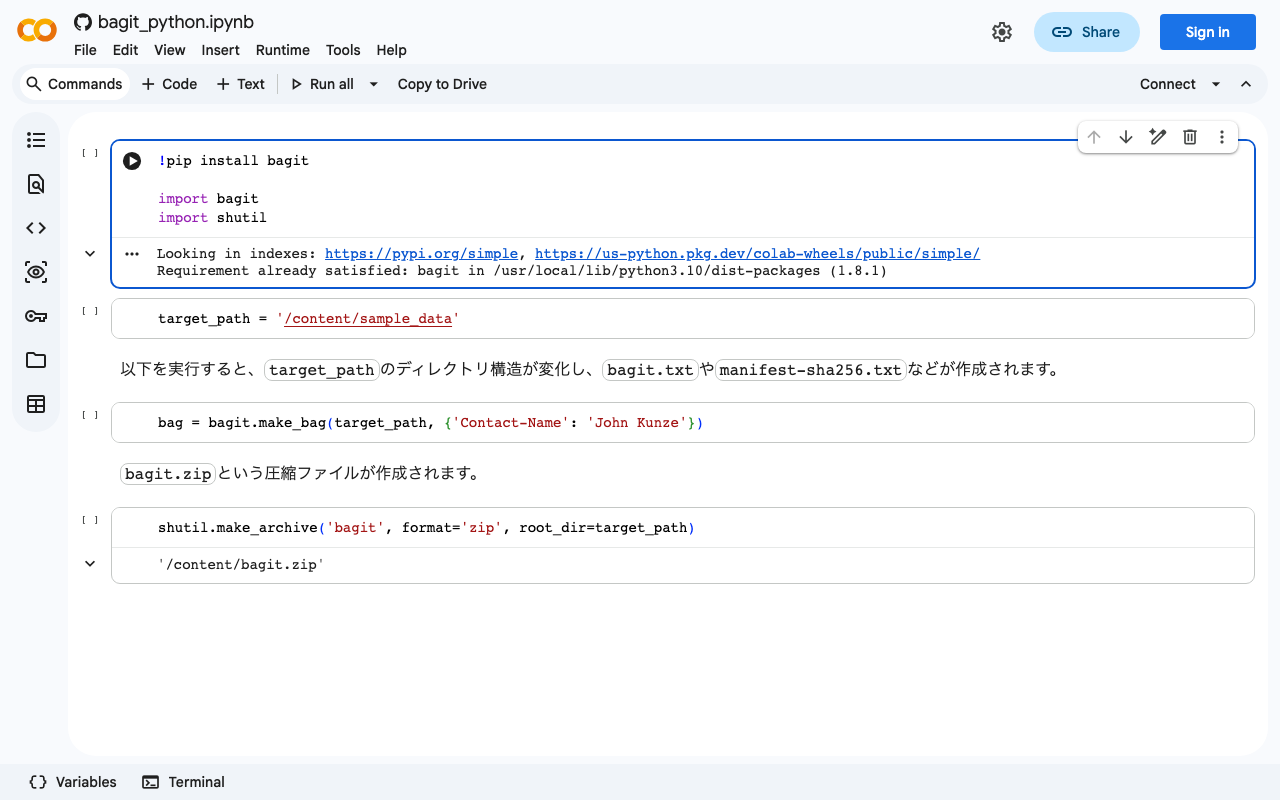
bagit-pythonを試す
DjangoとAWS OpenSearchを接続する
Drupal Key authを用いたコンテンツの登録と多言語対応

Wagtailを試す

Django REST framework JSON:API(DJA)に独自のモデルのビューをカスタマイズする
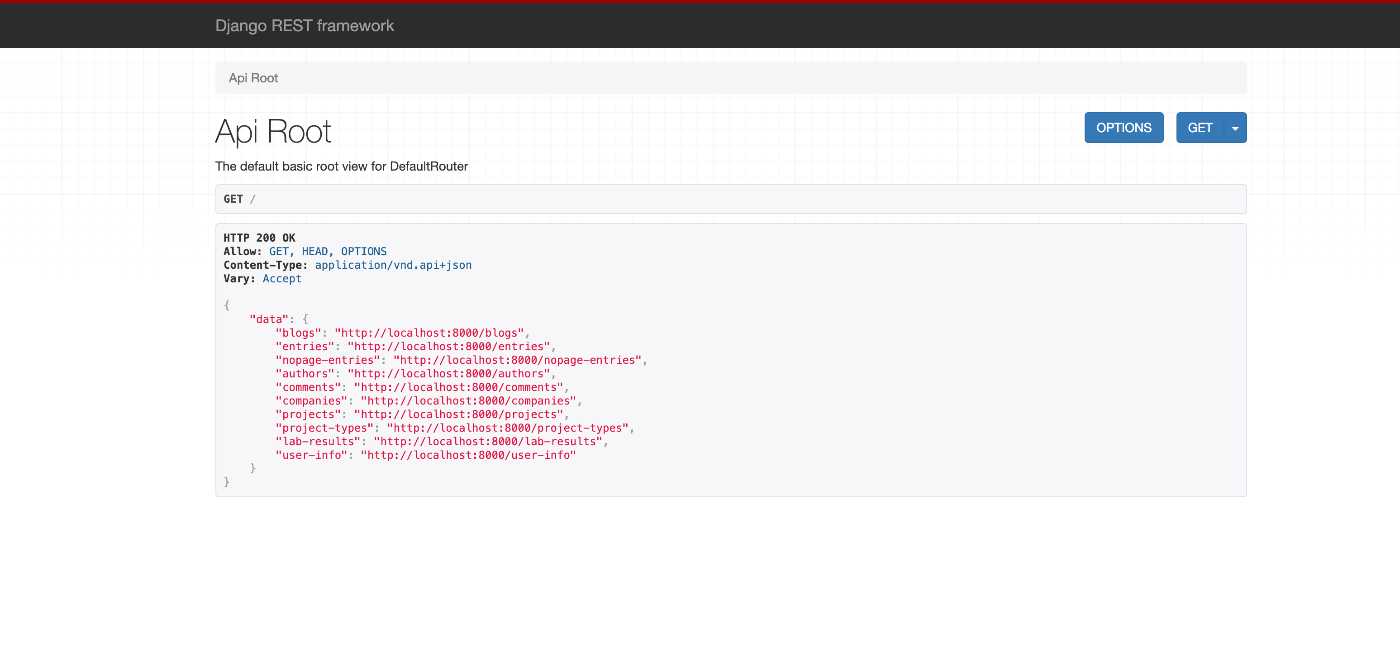
Django REST framework JSON:API(DJA)に独自のモデルを追加する

Django REST framework JSON:API(DJA)を試す

IIIFマニフェストファイルからPDFファイルを作成する
JPCOARスキーマ(v1)を用いたxmlファイルのバリデーションツールの試作
Google Colabを用いたNDL古典籍OCRチュートリアルの不具合の修正および機能追加を行いました。
Pythonを使ってDrupalのタクソノミーの登録とコンテンツへの追加
Pythonを使ってDrupalのコンテンツを更新・削除する

Pythonを使ってDrupalにコンテンツを追加する
ExcelからRDFを作成する
TEI/XMLファイルからrespStmtのnameの値を抽出する方法(GPT-4による解説)

nbdevを使用する際の備忘録
IIIF Image API level 0による画像公開方法

Google Colabを用いたNDL
JPCOARスキーマを用いたxmlファイルのバリデーション
RELAX NGスキーマを操作するライブラリjingtrangを試す:rngファイルの作成編
RELAX NGスキーマを操作するライブラリjingtrangを試す:検証編

WordをTEI/XMLに変換する
Google ColabでTesseractを動かす(日本語対応)

Vertex AIのworkbenchを使用した際、HuggingFaceのTrainer()が開始されない事象への対処法
ResourceSyncのPythonライブラリを試す
Omeka SのREST APIとやりとりするためのPythonパッケージ

python-docxを用いた両側ルビ

Pythonを用いてTEI/XMLファイルをEPUBに変換する
XMLファイルで文字列のみを抽出して処理する方法
BeautifulSoupでxml:id属性を与える方法
Virtuoso RDFストアに対して、curlおよびpythonを用いてRDFファイルを登録・削除する方法

二つのテキスト間の差分を抽出するプログラムを作成しました。
ファイルのアップロード(python)とダウンロード(php)

python-docxを用いたMicrosoft Wordファイルの作成:テンプレート、int2kanjiの利用など
Google Colabを用いたNDLOCRの実行にかかる時間について
Google Colabを用いたジャパンサーチRDFストアに対するSPARQLの実行例

AWS Lambdaを用いた物体検出API(Flask + yolov5)の構築
【Google Colab】はてなブログのAtomPub APIを用いた記事一覧の取得