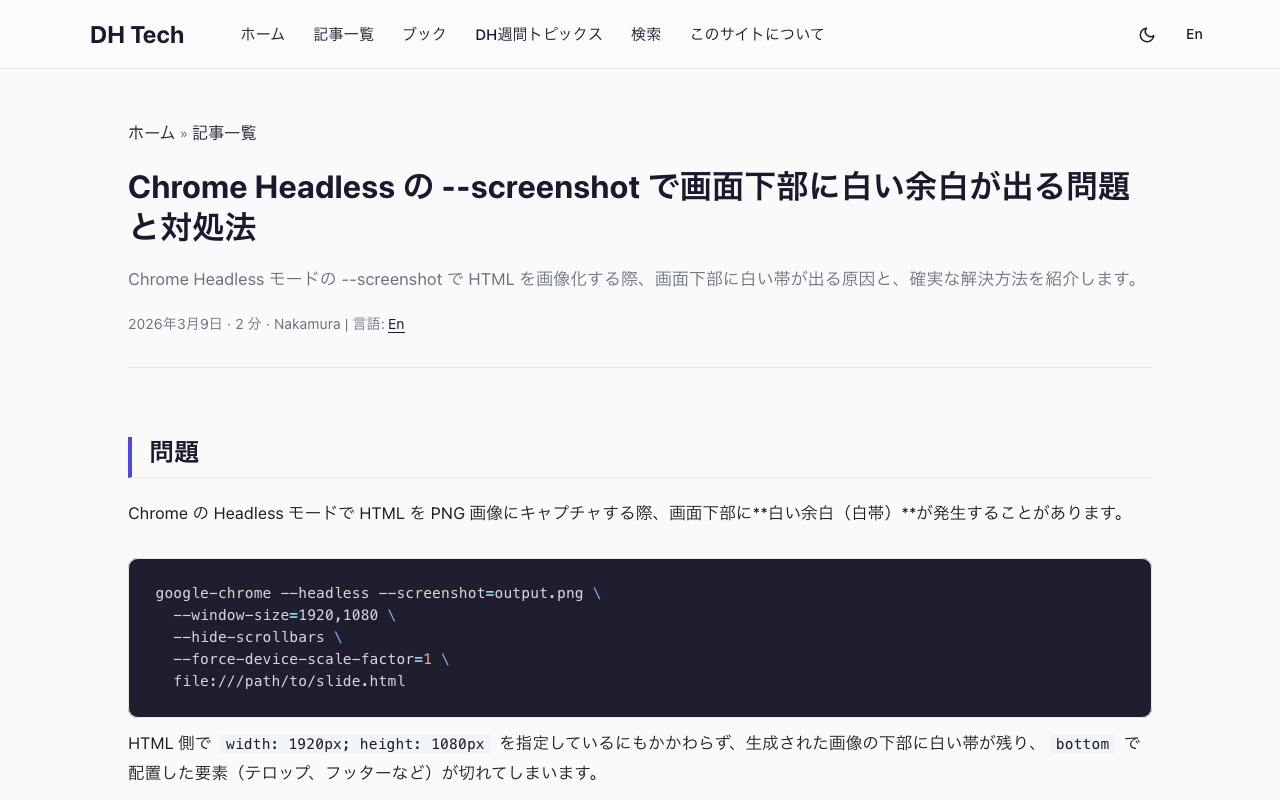
はじめに
技術ブログの記事を VTuber 風の解説動画に自動変換できたら面白いのでは――そんな思いつきから、Three.js + Puppeteer で VRM キャラクターをフレーム単位でレンダリングし、VOICEVOX の音声とリップシンクさせて動画を生成するパイプラインを作りました。
この記事では、実装で得られた知見とハマりどころを共有します。
全体のパイプライン
処理の流れは以下の通りです。
- Markdown 記事を読み込み → LLM(OpenRouter API)でセクション分割された台本を生成
- VOICEVOX でセクションごとに音声(WAV)と音素タイミングを生成
- Three.js + @pixiv/three-vrm でヘッドレス Chrome 上に VRM モデルを描画し、音素データに基づくリップシンクアニメーションをフレーム連番 PNG として出力
- スライド画像を自動生成(HTML → Chrome ヘッドレス → PNG)
- FFmpeg でスライド背景 + VRM アニメーション + 音声を合成し、MP4 動画を出力
Python スクリプトがオーケストレーション役を担い、VRM レンダリングは Node.js スクリプトを子プロセスとして呼び出す構成です。
使用技術
| 役割 | 技術 |
|---|---|
| 3D レンダリング | Three.js v0.172 |
| VRM 読み込み | @pixiv/three-vrm v3.3.3 |
| ヘッドレスブラウザ | puppeteer-core (SwiftShader) |
| 音声合成 | VOICEVOX Engine (Docker) |
| 動画合成 | FFmpeg |
| パイプライン制御 | Python |
| VRM モデル | AvatarSample_C (VRoid Hub / 無料ライセンス) |
ヘッドレス Chrome で VRM を読み込む
課題: file:// の CORS 制限
最初の壁は、ヘッドレス Chrome 上で VRM ファイルを読み込む方法でした。ローカルの .vrm ファイルを file:// プロトコルで読もうとすると CORS エラーで弾かれます。
解決策: Base64 エンコーディング
VRM ファイルを Node.js 側で Base64 にエンコードし、HTML テンプレートに文字列として埋め込むことで回避しました。
// Node.js 側: VRM を Base64 に変換
const vrmData = readFileSync(resolve(opts.vrm));
const vrmBase64 = vrmData.toString("base64");
// この文字列を HTML テンプレートに埋め込んで page.setContent() で渡す
ブラウザ側では Base64 をデコードして ArrayBuffer に変換し、GLTFLoader.parse() に渡します。
// ブラウザ側: Base64 → ArrayBuffer → GLTFLoader
const binary = atob(b64);
const bytes = new Uint8Array(binary.length);
for (let i = 0; i < binary.length; i++) bytes[i] = binary.charCodeAt(i);
const loader = new GLTFLoader();
loader.register((parser) => new VRM.VRMLoaderPlugin(parser));
loader.parse(bytes.buffer, '', async (gltf) => {
const vrm = gltf.userData.vrm;
VRM.VRMUtils.removeUnnecessaryVertices(vrm.scene);
VRM.VRMUtils.combineSkeletons(vrm.scene);
scene.add(vrm.scene);
});
VRM ファイルは数十 MB になることもあるので Base64 文字列もそれなりのサイズになりますが、page.setContent() で直接 HTML を設定するため、ネットワーク転送は発生せず実用上問題ありませんでした。
ボーン操作の罠: vrm.update() の呼び出し順序
課題: setNormalizedPose で首が折れる
@pixiv/three-vrm v3 では humanoid.setNormalizedPose() でボーンの回転を指定できますが、これを使って腕のポーズを設定したところ、首が不自然に折れ曲がるという問題が発生しました。正規化座標系と実際のボーン階層の変換で、意図しない回転が蓄積されてしまうようです。
解決策: getRawBoneNode() + vrm.update() の後に適用
解決策は、正規化 API を使わず getRawBoneNode() で直接ボーンノードを取得し、vrm.update() を呼んだ後に回転を設定することでした。
// ボーンノードの取得(初期化時)
const humanoid = vrm.humanoid;
const getBone = (name) => humanoid.getRawBoneNode(name);
const bones = {
lua: getBone('leftUpperArm'), lla: getBone('leftLowerArm'),
rua: getBone('rightUpperArm'), rla: getBone('rightLowerArm'),
spine: getBone('spine'), chest: getBone('chest'),
head: getBone('head'), neck: getBone('neck'),
};
レンダリングループでは、必ず vrm.update() を先に呼び、その後にボーンの回転を設定します。vrm.update() が正規化ポーズをリセットするため、順序を逆にするとポーズが上書きされてしまいます。
window.__render = function(dt) {
if (currentVrm) {
// 1. まず vrm.update() を呼ぶ(正規化ポーズのリセットが走る)
currentVrm.update(dt);
// 2. その後にボーン操作
const b = window.__bones;
if (b) {
// 腕を下ろすポーズ
if (b.lua) b.lua.rotation.z = 1.05;
if (b.rua) b.rua.rotation.z = -1.05;
// ... 他のボーン操作
}
}
renderer.render(scene, camera);
};
この「vrm.update() の後に操作する」というのが重要なポイントです。ドキュメントにも明記されていますが、実際にハマらないと気づきにくい部分でした。
カメラ設定: バストアップ構図
VTuber 風の動画ではキャラクターの上半身(バストアップ)を映すのが自然です。VRM モデルはおおむね Y 軸方向に身長 1.6〜1.7m 程度のスケールになっているので、以下のような設定で顔の高さに合わせました。
const camera = new THREE.PerspectiveCamera(35, W / H, 0.1, 100);
camera.position.set(0, 1.45, -1.3); // 顔の高さ、少し後ろから
camera.lookAt(0, 1.45, 0); // 顔を見る
PerspectiveCamera の FOV を 35 度と狭めにすることで、望遠レンズ的な圧縮効果が得られ、顔の歪みが少なくなります。
VOICEVOX からリップシンクデータを取得する
音素タイミングの抽出
VOICEVOX の audio_query API は、音声合成のパラメータとともに音素ごとのタイミング情報を返してくれます。これがリップシンクの鍵です。
def extract_phonemes(audio_query: dict) -> list[dict]:
"""accent_phrases から音素タイミングリストを生成する。"""
phonemes = []
current_time = 0.0
for phrase in audio_query.get("accent_phrases", []):
for mora in phrase.get("moras", []):
# 子音部分(口は閉じ気味)
consonant_len = mora.get("consonant_length")
if consonant_len and consonant_len > 0:
phonemes.append({
"time": round(current_time, 4),
"duration": round(consonant_len, 4),
"vowel": "N", # 子音中は口を閉じる
})
current_time += consonant_len
# 母音部分
vowel = mora.get("vowel", "N")
vowel_len = mora.get("vowel_length", 0.1)
if vowel_len and vowel_len > 0:
phonemes.append({
"time": round(current_time, 4),
"duration": round(vowel_len, 4),
"vowel": vowel.lower(),
})
current_time += vowel_len
# フレーズ間のポーズ
pause = phrase.get("pause_mora")
if pause:
pause_len = pause.get("vowel_length", 0.2)
phonemes.append({
"time": round(current_time, 4),
"duration": round(pause_len, 4),
"vowel": "pau",
})
current_time += pause_len
return phonemes
出力される JSON はこのような形式です。
[
{"time": 0.0, "duration": 0.08, "vowel": "N"},
{"time": 0.08, "duration": 0.12, "vowel": "o"},
{"time": 0.20, "duration": 0.06, "vowel": "N"},
{"time": 0.26, "duration": 0.10, "vowel": "a"},
...
]
母音 → VRM Expression のマッピング
VRM の表情(Expression)には口の形に対応する aa, ih, ou, ee, oh が定義されています。VOICEVOX の母音とのマッピングは単純です。
const vowelToExpr = {
'a': 'aa', // あ → 口を大きく開ける
'i': 'ih', // い → 横に引く
'u': 'ou', // う → すぼめる
'e': 'ee', // え → 少し開ける
'o': 'oh', // お → 丸く開ける
'N': null, // 子音・撥音 → 口を閉じる
'cl': null, // 促音
'pau': null, // ポーズ
};
口の開閉は瞬時に切り替えると不自然なので、weight をフレームごとに補間して滑らかに遷移させています。
window.__setPhoneme = function(vowel, dt) {
const em = currentVrm.expressionManager;
const targetExpr = vowelToExpr[vowel] || null;
const speed = 15;
// すべての口表情をリセット
for (const name of ['aa', 'ih', 'ou', 'ee', 'oh']) {
em.setValue(name, 0);
}
// ターゲットの表情に向かって補間
if (targetExpr) {
weight = Math.min(1.0, weight + dt * speed);
em.setValue(targetExpr, weight);
} else {
weight = Math.max(0, weight - dt * speed);
if (prevExpr) em.setValue(prevExpr, weight);
}
};
アイドルアニメーション: 生きているように見せる
口パクだけでは棒立ちのマネキンのようになってしまいます。微細な動きを加えることで「生きている感」を出します。
// vrm.update(dt) の後に適用
// 1. 呼吸: 胸ボーンの微小な前後回転
const breath = Math.sin(breathPhase) * 0.01;
if (bones.chest) bones.chest.rotation.x = breath;
// 2. 体の揺れ: 脊椎ボーンの左右揺れ
const sway = Math.sin(totalTime * 0.6) * 0.015;
if (bones.spine) bones.spine.rotation.z = sway;
// 3. 頭の動き: 話しながら少し傾く
const headTilt = Math.sin(totalTime * 0.8) * 0.02;
const headNod = Math.sin(totalTime * 1.5) * 0.015;
if (bones.head) {
bones.head.rotation.z = headTilt;
bones.head.rotation.x = headNod;
}
// 4. 腕の揺れ: 自然な微動
const armSwing = Math.sin(totalTime * 1.2) * 0.03;
if (bones.lua) bones.lua.rotation.z = 1.05 + armSwing;
if (bones.rua) bones.rua.rotation.z = -(1.05 + armSwing);
各アニメーションのポイントは以下の通りです。
- 周波数をずらす: 呼吸 (0.8Hz)、体揺れ (0.6Hz)、頭 (0.8Hz / 1.5Hz)、腕 (1.2Hz) と異なる周波数にすることで機械的な繰り返しを避ける
- 振幅は控えめに: 0.01〜0.03 rad 程度。大きくしすぎると不自然になる
- まばたき: 3〜6秒のランダム間隔で 0.15 秒かけてまばたきする
まばたきは Expression の blink を使います。
blinkTimer += dt;
if (!blinkState && blinkTimer > 3 + Math.random() * 3) {
blinkState = true;
blinkTimer = 0;
}
if (blinkState) {
const p = blinkTimer / 0.15;
const v = p < 0.5 ? p * 2 : p < 1 ? (1 - p) * 2 : 0;
em.setValue('blink', v);
if (p >= 1) { blinkState = false; blinkTimer = 0; }
}
フレーム単位レンダリングの仕組み
リアルタイムレンダリングではなく、Puppeteer 経由でフレームごとにスクリーンショットを撮る方式を採用しています。
// Node.js 側: フレームループ
for (let frame = 0; frame < totalFrames; frame++) {
const currentTime = frame / opts.fps;
const currentPhoneme = findPhoneme(phonemes, currentTime);
await page.evaluate(
(phoneme, dt) => {
window.__setPhoneme(phoneme, dt);
window.__render(dt);
},
currentPhoneme,
1.0 / opts.fps
);
await page.screenshot({
path: `${outputDir}/frame_${String(frame).padStart(6, '0')}.png`,
omitBackground: true, // 透過背景
});
}
この方式のメリットは以下の通りです。
- フレーム落ちがない: リアルタイムではないので、GPU 性能に関係なく全フレームが確実にレンダリングされる
- 透過背景:
omitBackground: trueで透過 PNG を出力し、FFmpeg で好きな背景に合成できる - SwiftShader:
--use-angle=swiftshaderにより GPU がない環境(CI/CD など)でも動作する
デメリットは速度で、30fps × 60秒で 1800 枚のスクリーンショットを撮るため、それなりに時間がかかります。
FFmpeg による合成
最後に FFmpeg でスライド背景、VRM フレーム、音声を合成します。
ffmpeg -y \
-loop 1 -i slide.png \ # スライド背景
-framerate 30 -i frames/frame_%06d.png \ # VRM フレーム連番
-i audio.wav \ # 音声
-filter_complex "[1]scale=360:360[vrm];[0][vrm]overlay=x=W-w-20:y=H-h-20:shortest=1[vout]" \
-map "[vout]" -map "2:a" \
-c:v libx264 -preset fast \
-c:a aac -b:a 192k \
-pix_fmt yuv420p \
output.mp4
VRM のフレームを 360x360 にスケールし、スライドの右下に配置しています。各セクションの動画を生成した後、concat でまとめて一本の動画にします。
VRM モデルについて
今回は VRoid Hub で公開されている AvatarSample_C を使用しました。VRoid Hub のサンプルモデルは個人利用・商用利用ともに許可されており、気軽に試せます。
自分で VRoid Studio を使ってオリジナルモデルを作成し、.vrm 形式でエクスポートすることもできます。
まとめ
Three.js + @pixiv/three-vrm + Puppeteer の組み合わせで、VRM キャラクターのアニメーション動画を完全にプログラマティックに生成できました。
実装上のハマりどころをまとめると、以下の通りです。
- VRM 読み込み: ヘッドレス Chrome では
file://の CORS があるため、Base64 エンコーディングで回避 - ボーン操作:
setNormalizedPoseではなくgetRawBoneNodeを使い、vrm.update()の後に回転を適用 - リップシンク: VOICEVOX の
accent_phrases→moraから母音を抽出し、VRM Expression にマッピング - 自然な動き: 呼吸・体揺れ・頭の傾き・まばたきを異なる周波数の sin 波で実現
VTuber 的な解説動画の自動生成はまだ荒削りですが、ブログ記事を入力するだけで動画が出てくるのはなかなか楽しいです。VOICEVOX のクレジット表記も忘れずに。
動画版(生成AIによる自動生成): この記事の内容をずんだもん×四国めたんの掛け合いで解説しています。自動生成のため、内容に誤りがある可能性があります。正確な情報は記事本文をご参照ください。