This article is co-authored with generative AI. While I have cross-checked facts against official documentation where possible, errors may remain. Please verify primary sources before making important decisions.
Background
I needed to embed a third-party browser-based demo app under static/ on our Nuxt 2 / target: 'static' site:
static/
├── vdiff/
│ ├── index.html # entry point of the embedded tool
│ ├── vdiffjs/...
│ └── opencv/...
└── ...
Pages on our own site link into the embedded app with URLs like /vdiff/?img1=...&img2=.... The links are written in Vue templates as:
<a :href="`/vdiff/?img1=${...}&img2=${...}`">Compare</a>
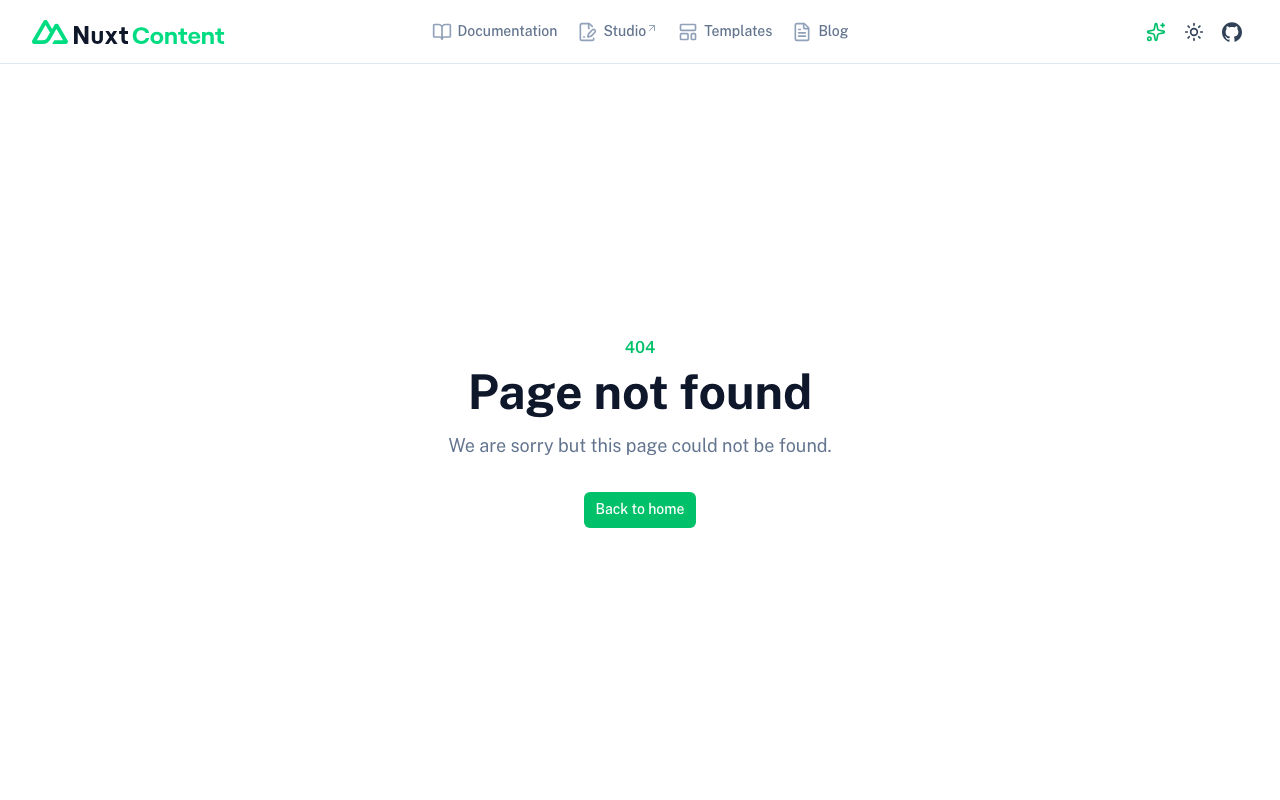
It works fine in local npm run dev, but in production (yarn generate:production → GitHub Pages), hitting /vdiff/ returns Nuxt's "This page could not be found" page.
What was confusing:
- Deeper static files like
/vdiff/vdiffjs/vdiff.bundle.min.jsare served correctly static/vdiff/index.htmldoes exist (909 bytes)- Yet
/vdiff/(with trailing slash) returns Nuxt's 378KB 404 app shell
So only index.html was being replaced with Nuxt's 404 page — everything else was fine.
The cause: Nuxt 2 generate's crawler
Nuxt 2 generate (target: 'static') runs a crawler by default:
- SSR each route, extract links
- For any extracted relative URL not defined in
pages/, write a fallback HTML (404 app shell) todist/<route>/index.html
In my case, the /picture/face/ page emitted lots of <a href> to /vdiff/?img1=... (123 of them). The crawler stripped the query string, treated /vdiff/ as an unknown route, and wrote:
dist/vdiff/index.html ← overwritten with the 404 app shell
Timing-wise, route generation runs after the static/ copy, so the 909-byte index.html I'd placed got clobbered.
Why the existing static/mirador3/ was unaffected
The same site already had static/mirador3/index.html and that one served fine at /mirador3/. The difference was in how the link was constructed:
// mirador3 side (works)
url: process.env.BASE_URL + '/mirador3/?params=' + encodeURIComponent(...)
// → SSR'd HTML contains an absolute URL:
// <a href="https://example.com/mirador3/?params=...">
// vdiff side (broke)
:href="`/vdiff/?img1=${...}`"
// → SSR'd HTML contains a relative URL:
// <a href="/vdiff/?img1=...">
Internally, Nuxt 2's crawler only picks up URLs starting with / (and not //) as internal-route candidates (the check is roughly startsWith('/') && !startsWith('//')). Absolute URLs (https://...) don't begin with /, so they're naturally skipped. Relative URLs (/vdiff/?...) get picked up — hence the difference.
The fix: generate.exclude
Two options:
- Make the link an absolute URL (matching the mirador3 style)
- Use
generate.excludeto remove the path from the crawler's route generation
I went with the second. Rationale:
- A single setting can exclude all mirror paths at once
- No changes to link-construction logic — the change stays inside
nuxt.config.js - Easy to extend: for new mirror directories you just add another regex to the array
// nuxt.config.js
export default {
// ...
generate: {
fallback: true,
exclude: [/^\/vdiff(\/|$)/],
routes() { /* ... */ },
},
}
Trailing (\/|$) makes the regex match both /vdiff and /vdiff/. For multiple tools, either add more entries or combine:
exclude: [/^\/(vdiff|vdiff-seq|iiif-curation-viewer)(\/|$)/]
Note that exclude only affects crawler-driven route generation; routes returned from generate.routes() are unaffected. It's specifically about "don't write a fallback HTML when you encounter an unknown path."
The other gotcha: an old @nuxtjs/pwa Service Worker
With the above, /vdiff/ started returning the correct 909-byte index.html and server-side verification passed. But for some users, old code kept running in the browser.
Specifically, getVDiffUrl() had been rewritten to return /vdiff/?..., but in those users' browsers the URL was still being generated in the old form (http://codh.rois.ac.jp/...).
The server response was returning the new _nuxt/* bundle, but it wasn't reaching the browser. Classic Service Worker cache-first behavior.
Investigating: the site had been PWA-ified with @nuxtjs/pwa in the past, with a workbox-built SW registered at /sw.js. Navigation requests used NetworkFirst, but the build artifacts under /_nuxt/* (hashed JS / CSS) are served CacheFirst at runtime (because cacheAssets is on by default in @nuxtjs/pwa's workbox sub-module), which was preventing the new JS from being fetched.
- nuxt.config.js had
workbox.runtimeCachingwith/_nuxt/asCacheFirstand/.*asStaleWhileRevalidate(30 days). (Note: in workbox v4-style configs, thehandlervalue is PascalCase.) - After the first fetch, the
/_nuxt/*files sit in Cache Storage, and the SW keeps serving them ahead of the network even after I deploy new code.
For the retirement procedure, I followed tech.ldas.jp's "Retiring a stale Service Worker after a framework migration with a kill-switch SW". The key steps were:
1. Disable @nuxtjs/pwa workbox
In nuxt.config.js, disable the workbox sub-module:
export default {
modules: [
// Keep '@nuxtjs/pwa' if you still want manifest / icon
'@nuxtjs/pwa',
],
pwa: {
workbox: false, // ★ stop generating SW
},
}
This ensures subsequent builds no longer overwrite dist/sw.js with a workbox SW.
2. Replace /sw.js with a kill-switch SW
At the same URL the old SW will check (/sw.js), serve a SW that just unregisters itself:
// static/sw.js — kill-switch Service Worker
self.addEventListener('install', () => {
self.skipWaiting()
})
self.addEventListener('activate', (event) => {
event.waitUntil(
(async () => {
const keys = await caches.keys()
await Promise.all(keys.map((k) => caches.delete(k)))
await self.registration.unregister()
const clients = await self.clients.matchAll({
type: 'window',
includeUncontrolled: true,
})
for (const client of clients) {
try { client.navigate(client.url) } catch (_) { /* noop */ }
}
})()
)
})
Notes:
- Don't add a
fetchhandler (otherwise the new SW intercepts requests, defeating the purpose) - Pass
includeUncontrolled: truetoclients.matchAll. The SW just activated and isn't controlling anyone yet, so the default returns an empty array - Per spec,
client.navigate(url)rejects the returned Promise withTypeErrorfor cross-origin URLs (it does NOT throw synchronously). For a kill-switch you're passing a same-origin URL so it doesn't matter, but if you wrap it intry/catchlike above,.catch(() => {})is technically more correct - Keep
Cache-Controlshort. GitHub Pages defaults to max-age=600 which is fine; on your own host,max-age=0, must-revalidateis safer - Leave the kill-switch in place for weeks to months after deployment. Long-tail users still have the old SW running in their browsers
By the way: many Nuxt 2 repos have static/sw.js in .gitignore (treating it as a build artifact). To version-control the kill-switch SW, either:
git add -f static/sw.js
or add !static/sw.js as an exception line in .gitignore.
3. As a belt-and-suspenders, also cleanup from the page itself
The kill-switch SW only activates after the browser does an update check on /sw.js. To kick in faster for long-tail returning users, run the cleanup explicitly in a client plugin:
// plugins/sw-cleanup.client.js
export default () => {
try {
if ('serviceWorker' in navigator) {
navigator.serviceWorker.getRegistrations().then((rs) => {
rs.forEach((r) => r.unregister())
})
}
if (typeof caches !== 'undefined') {
caches.keys().then((ks) => ks.forEach((k) => caches.delete(k)))
}
} catch (_) { /* noop */ }
}
// nuxt.config.js
plugins: [{ src: '~/plugins/sw-cleanup.client.js', mode: 'client' }],
This unregisters SWs and clears Cache Storage on every page visit, so cleanup happens immediately without waiting for the kill-switch SW to activate.
Summary
When embedding a third-party app under static/<tool>/:
- Writing the link as a relative URL causes the crawler to follow it and overwrite
index.htmlwith the 404 app shell - Fix it with
generate.exclude, or switch the link to an absolute URL - If the site previously had
@nuxtjs/pwaworkbox, deployments are blocked for some users by SW caching - Disable workbox, deploy a kill-switch SW + a client-side plugin to retire the old SW + Cache Storage
These four points cover most of the pain.
Nuxt 3 / Vite-era frameworks have opt-in SW behavior by default, so the same problem is unlikely to recur. But if you're still running a Nuxt 2 + @nuxtjs/pwa site, you may keep hitting this on every site change.
References
- Restoring CODH's vdiff.js from the Wayback Machine to Temporarily Bring Back The Tale of Genji's Face Comparison Feature — The mirror work that prompted this post (Wayback
id_flag usage, etc.) - Setting up a dedicated GitHub Pages repository for a temporary CODH-tool mirror — The follow-up that mirrors all CODH tools as a separate repo
- Retiring a stale Service Worker after a framework migration with a kill-switch SW (tech.ldas.jp, JA)
- Nuxt 2 generate.exclude reference
- self-destroying-sw