本記事は生成AIと共同で執筆しています。事実関係は可能な範囲で公式ドキュメント等と照合していますが、誤りが含まれている可能性があります。重要な判断を行う前にご自身でも一次情報をご確認ください。
対象:人文学・歴史学・美術史・図書館情報学などの研究者で、デジタル史料に注釈を残したい方。プログラミング知識は不要です。
IMMARKUS は、IIIF 画像に注釈をつけるためのオープンソースの画像注釈ツールです。ベルギーの KU Leuven が中心となる ERC プロジェクト Regionalizing Infrastructures in Chinese History (RegInfra) で開発され、研究者・デジタル人文学者・文化遺産機関の専門家を主な対象としています。
史料の画像に「この妖怪は何か」「この一節は誰への言及か」といった注釈を残したいとき、論文の脚注や表計算ソフトに書き留める方法もあります。ただしその形だと、注釈は画像の領域そのものとは結びつかず、共有や集計には別途手間がかかります。IMMARKUS は、注釈を画像上の領域に直接ひもづけ、W3C 標準形式のまま保存することを目的としたツールです。
本稿では、IMMARKUS を初めて使う場合の操作を、最初の注釈を作って W3C 標準形式で書き出すところまで順に説明します。題材には、東京大学デジタルアーカイブで公開されている「百鬼夜行図」の IIIF マニフェストを使います。
1. IMMARKUS の特徴
研究目的の画像注釈ツールには CVAT、Label Studio、VIA、Recogito などがあり、Mirador にも IIIF 注釈レイヤがあります。そのなかで IMMARKUS の特徴として、次の 3 点が挙げられます。
- IIIF と W3C Web Annotation をネイティブに扱う
注釈は最初から
@context: http://www.w3.org/ns/anno.jsonldの Linked Data として保存されます。後から研究データ向けの形式に変換する工程は不要です。 - ローカルファースト ブラウザの File System Access API を使い、ユーザーが選んだフォルダにすべてのデータが保存されます。サーバへの登録は不要で、未公開の資料も手元で扱えます。
- スキーマ駆動 「人物」「橋」「都市壁」「妖怪」などのエンティティクラスとプロパティを先に設計してから注釈する設計です。分類タグを後付けで増やす方式と比べると、データセットの一貫性を最初から保ちやすくなります。
2. 前提となる 2 つの仕様(最小知識)
IIIF(International Image Interoperability Framework)
世界中の図書館・博物館・大学が採用している画像配信の標準です。ここで押さえておきたいのは、次の 2 種類の URL があるという点です。
- Image API:画像そのもの。タイル化された高解像度画像を、必要な領域・縮尺だけ取得できます。
- Presentation Manifest:画像の集合とメタデータを束ねた JSON。これをビュアーに渡すと一つの作品としてめくれます。
IMMARKUS が読むのは後者の Presentation Manifest URL です。
W3C Web Annotation Data Model
「あるリソースの、ある領域に対して、ある内容をひもづける」という構造をモデル化した W3C 勧告です。最小の例は次のとおりです。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"type": "Annotation",
"target": { "source": "...", "selector": { "type": "FragmentSelector", "value": "xywh=..." } },
"body": [ { "purpose": "classifying", "source": "Person" } ]
}
target が「どこに」、body が「何を」を表します。IMMARKUS が書き出す JSON もすべてこの形式です。
3. セットアップ(所要 5 分)
3.1 推奨ブラウザ
File System Access API が必要なため、Chrome または Edge のデスクトップ版を使います。調べた限りでは、Safari / Firefox では一部の機能が動かないようです。
3.2 作業フォルダを用意する
ホームディレクトリ配下に空のフォルダを作ります。例:
~/Documents/immarkus-hyakkiyagyou/
このフォルダの中に、IMMARKUS が次のような管理ファイルを書き込みます(実際の出力例)。
| ファイル | 役割 |
|---|---|
_immarkus.model.json | エンティティクラス・プロパティ・関係型などのデータモデル |
_immarkus.folder.meta.json | フォルダ単位のメタデータ |
_immarkus.relations.json | エンティティ間の関係注釈 |
_iiif.<id>.json | インポートした IIIF マニフェストの正規化情報 |
_iiif.<id>.annotations.json | その IIIF リソースに付けた注釈の配列 |
フォルダごと共有・バックアップすれば、同じ状態を別の環境で再現できます。Git で管理することもできます。
3.3 IMMARKUS を開く
- https://immarkus.xmarkus.org/ にアクセスします。
- Open New Folder をクリックし、用意したフォルダを選択します。
- ブラウザがフォルダの編集許可を尋ねるので、Edit files を許可します。
これで作業空間が立ち上がります。
本稿の検証は公開版 v1.1.1(Build 13.04.2026)で行いました。リポジトリの
package.jsonには次バージョン v1.2.0 の記載がありますが、確認した時点ではデプロイされていないようです。
4. データモデルを先に作る
スキーマを注釈の前にどれだけ練るかは、研究データの扱いやすさに影響します。IMMARKUS では左サイドバーの Data Model タブから設計します。Data Model 画面は次の 4 つのサブタブで構成されます。
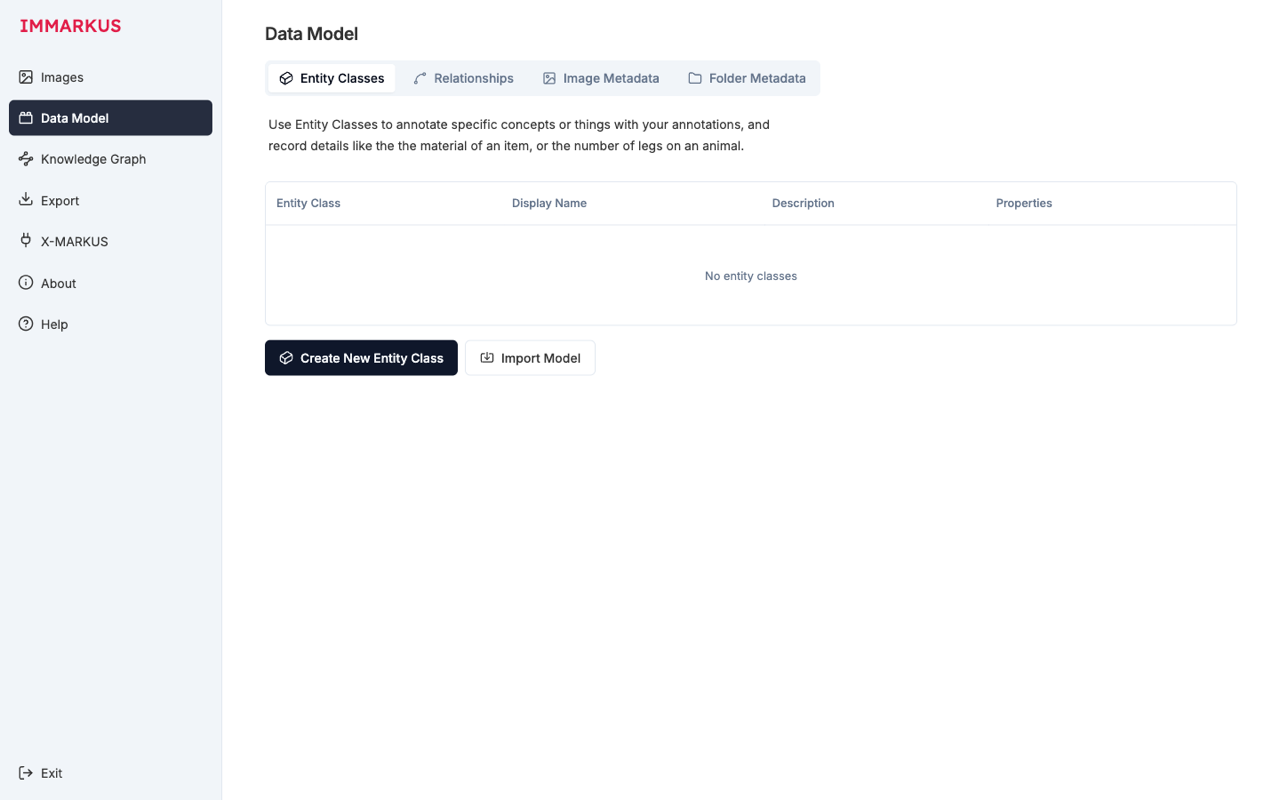
| サブタブ | 役割 |
|---|---|
| Entity Classes | 「人物」「妖怪」など概念のクラス階層 |
| Relationships | エンティティ間の関係型(方向あり/なし) |
| Image Metadata | 画像レベルのメタデータスキーマ(題名・所蔵・撮影日など) |
| Folder Metadata | フォルダレベルのメタデータスキーマ(資料群単位) |
対象そのもの(Entity)だけでなく、画像のメタデータや、フォルダ=資料群のメタデータまで構造化できます。図書館目録的な情報も取り回せます。
4.1 エンティティクラス
エンティティクラスは、画像の中で識別したい概念を表すクラスです。「Create New Entity Class」を押すと、エントリプレビュー付きのフォームが立ち上がります。
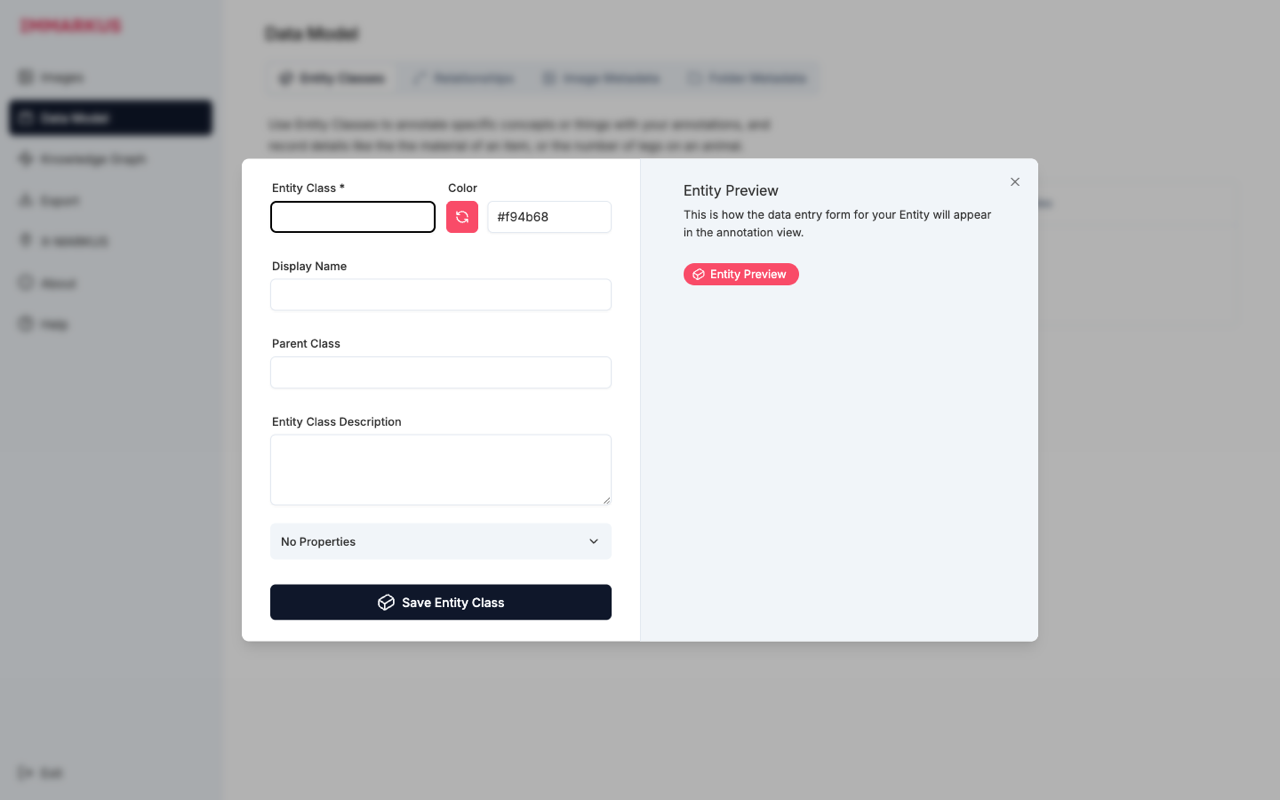
右側の Entity Preview には、注釈時にこのクラスがどう見えるかが表示されます。色とラベルを決めながら見た目を確認できます。
今回の百鬼夜行図なら、たとえば次のように設計できます。
Being(生き物)
├─ Person(人物)
└─ Yokai(妖怪)
├─ Tsukumogami(付喪神)
└─ Oni(鬼)
Object(物体)
├─ Container(容器)
└─ Tool(道具)
階層は、親クラスのプロパティを子クラスが継承します。Being に gender プロパティを置けば、Person も Yokai も自動でそれを持ちます。
4.2 プロパティの型
IMMARKUS が用意するプロパティ型は次のとおりです。
| 型 | 用途例 |
|---|---|
| Text | 自由記述、注記 |
| Number | 個体数、年齢推定 |
| Options | 既定の選択肢からひとつ選ぶ(性別、季節など) |
| Number Range | 推定値の幅(推定年代など) |
| URI | 外部リンク |
| Geo-coordinates | 地理情報 |
| Measurement | 単位付き計測値 |
| Color | カラーピッカー |
| External Authority | Getty AAT、VIAF、Wikidata など権威ファイルへの参照 |
研究データを後から相互参照したい場合は、自由記述の Text より、Options や External Authority を使っておくと扱いやすくなります。
4.3 関係型(Relationship Type)
「A は B を持っている」「A は B の背後にいる」など、エンティティ間の関係を方向あり/なしで定義できます。これは後で Knowledge Graph として可視化されます。
Tip:データモデルは一つのプロジェクトに 1 つだけ持てます。複数の研究で使い分けるときは、別フォルダで別プロジェクトを起こします。モデル JSON を Import Model で読み込めば、後から再利用できます。
5. 画像をインポートする:百鬼夜行図
今回はローカル画像ではなく、東京大学デジタルアーカイブの IIIF マニフェストを使います。
-
メニューの Import IIIF をクリックします。次のダイアログが開きます。
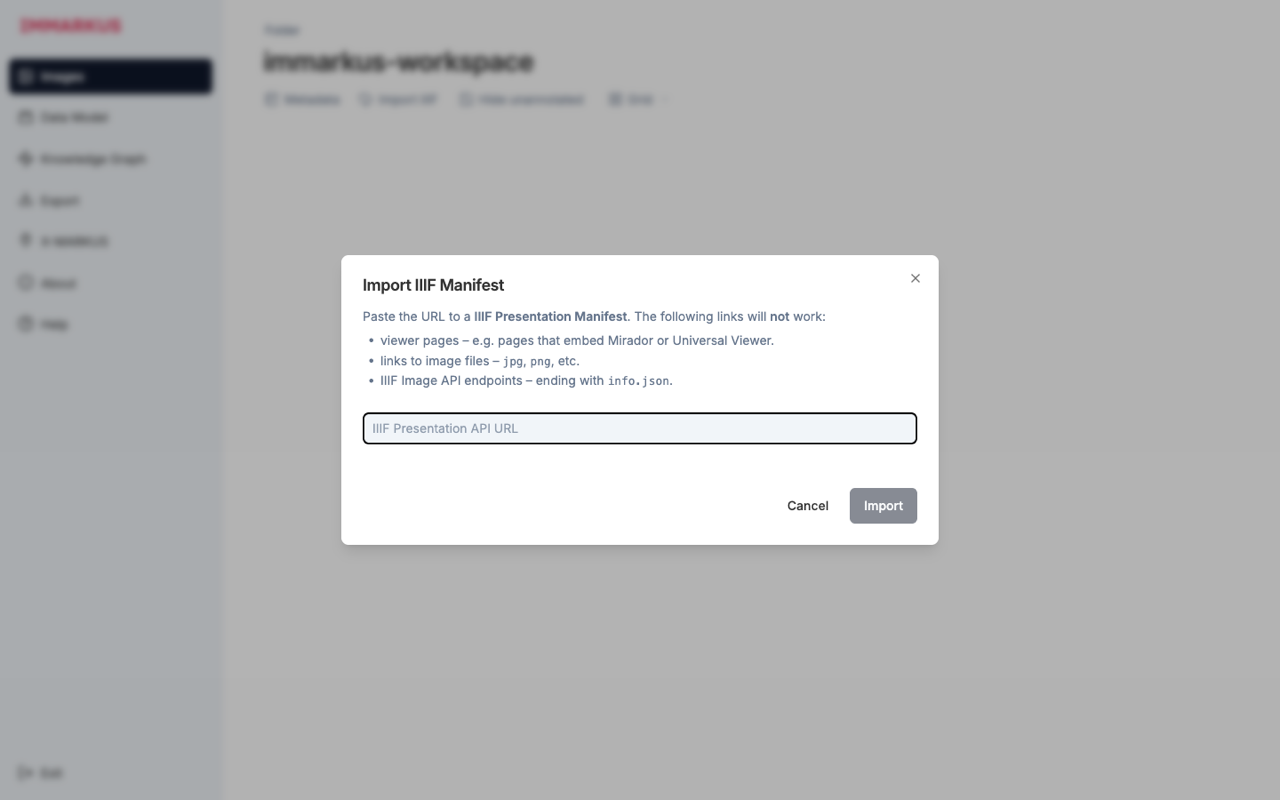
-
次の URL を貼り付けます。
https://da.dl.itc.u-tokyo.ac.jp/portal/repo/iiif/fbd0479b-dbb4-4eaa-95b8-f27e1c423e4b/manifest -
Import を押します。インポート完了後、サムネイルに IIIF アイコンが付けば成功です。
サイズ表記に注目してください。79,508 × 3,082 ピクセルという大きな画像で、これがエマキ(絵巻物)です。タイル化に対応しない画像注釈ツールでは開けなかったり動作が重くなったりすることがありますが、IMMARKUS は IIIF Image API のタイル配信を使うため、この大きさでも軽快に扱えます。
このとき書き出される _iiif.<id>.json は、IMMARKUS が内部で扱うために正規化したものです。中身は次のようになっています。
{
"id": "a9dfe98422a0aac0",
"name": "百鬼夜行図",
"uri": "https://da.dl.itc.u-tokyo.ac.jp/portal/repo/iiif/fbd0479b-dbb4-4eaa-95b8-f27e1c423e4b/manifest",
"importedAt": "2026-05-06T23:06:42.328Z",
"type": "PRESENTATION_MANIFEST",
"majorVersion": 2,
"canvases": [
{ "id": "3318151926", "uri": "...canvas/p1", "name": "[1]", "manifestId": "a9dfe98422a0aac0" }
]
}
majorVersion: 2 は IIIF Presentation API のバージョンです。IMMARKUS は v2 / v3 のどちらも読み込めます。
6. アノテーションを描く
サムネイルをクリックすると、エマキ全体がブラウザいっぱいに広がります。マウスホイールでズーム、ドラッグでパンします。
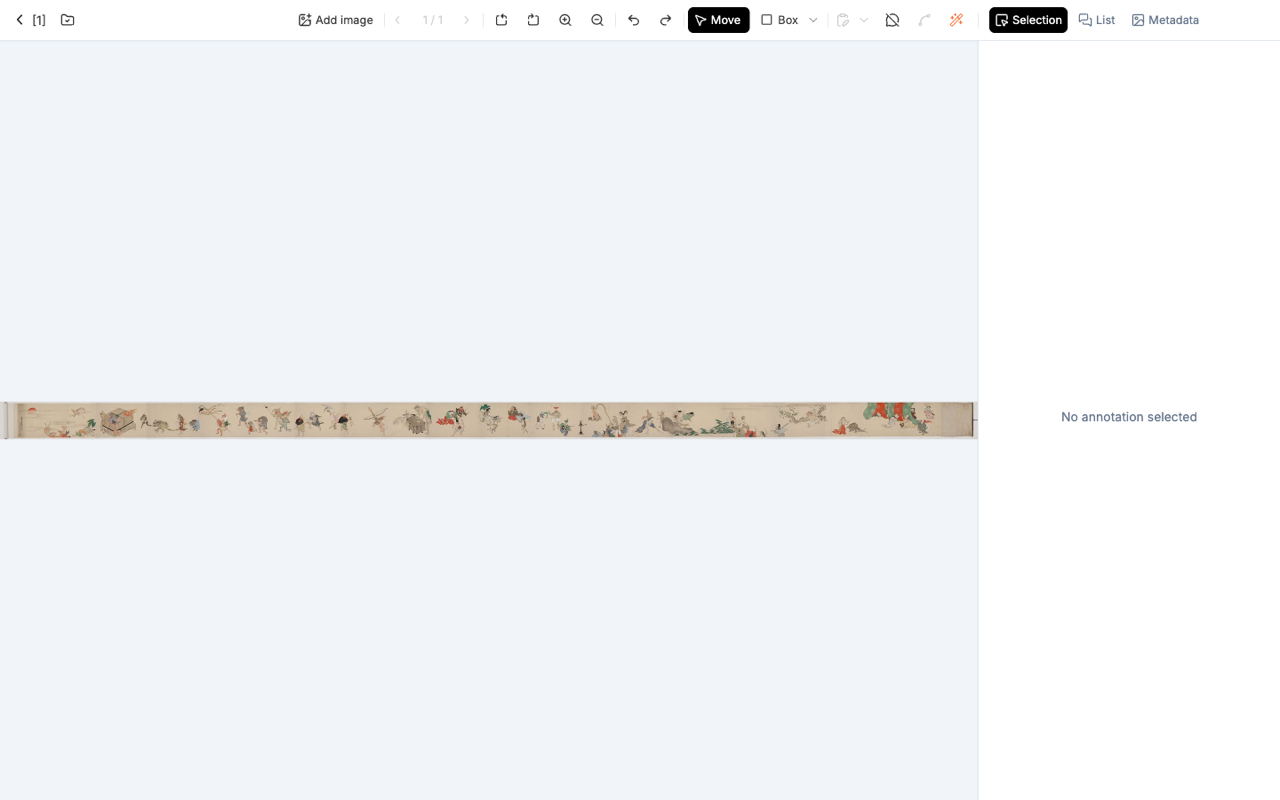
上部のツールバーは、左から Move(移動)、Box(形状ドロップダウン:矩形・楕円・ポリゴン・パスを切り替え)、矢印、魔法の杖(スマートツール)、右側に Selection / List / Metadata という構成です。

6.1 4 つの図形
UI 上の名称は Box / Ellipse / Polygon / Path の 4 種です。
| 図形 | 操作 | 適する対象 |
|---|---|---|
| Box | 1 クリックで開始 → マウス移動 → 2 クリック目で確定(ドラッグではない) | 矩形が自然な対象、書誌の貼り紙など |
| Ellipse | Box と同じく click → move → click | 顔・印章・円形装飾 |
| Polygon | クリックで点を追加、ダブルクリックで閉じる | 妖怪・人物のシルエットなど不定形 |
| Path | ダブルクリックで閉じない線として残す | 行列や視線の方向を示すとき |
6.2 スマートツール
魔法の杖アイコンから、次の 4 つのツールが使えます。
- Smart Scissors:輪郭に沿って自動追従します。墨線がはっきりしているエマキに向きます。
- Edge Snap:直線エッジに吸着します。建築物に向きます。
- Auto Select(SAM):Segment Anything Model で対象を自動セグメンテーションします。
- Auto Transcribe:複数の OCR / VLM サービスから選んで文字起こしします。崩し字には限界があるため、結果は校正が必要です。
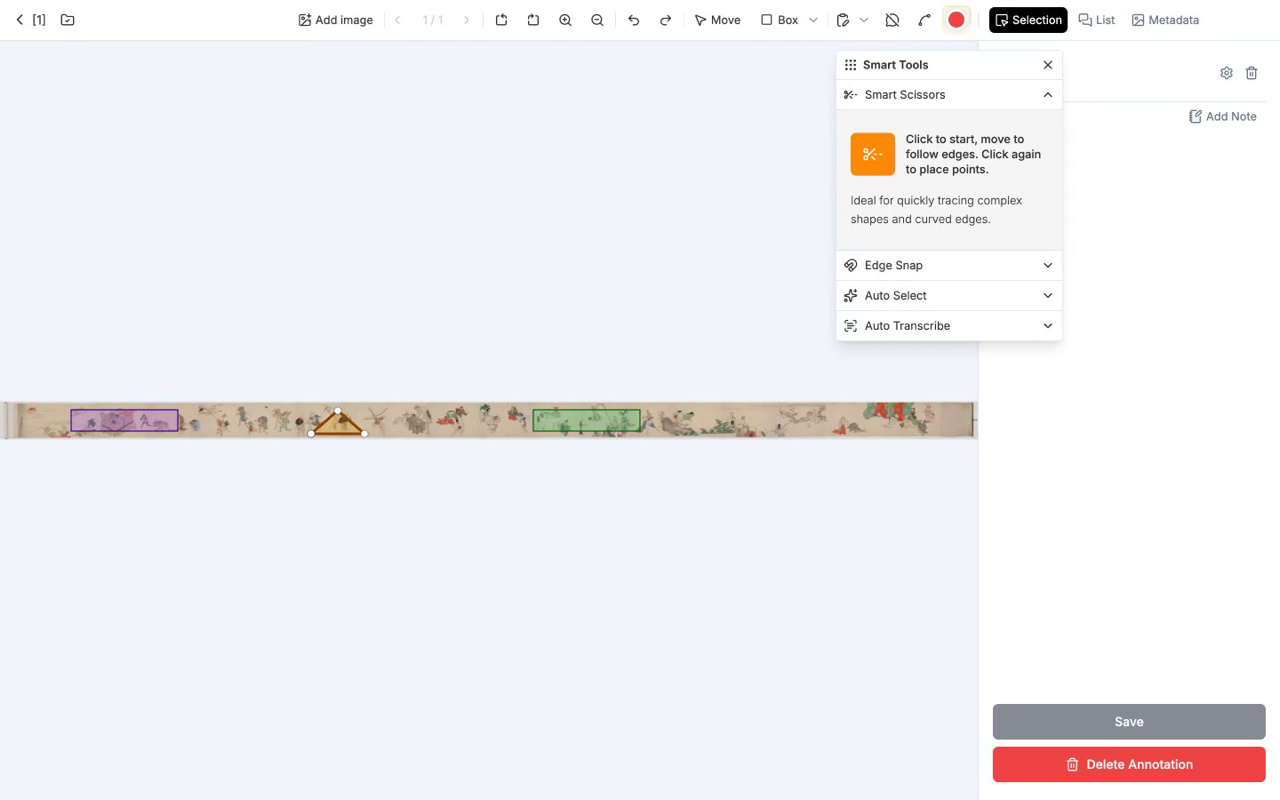
Auto Select と Auto Transcribe は AI サービスとの連携機能で、利用には API キーの設定が必要です。
6.3 タグ付け
形が確定すると、右パネルにフォームが出ます。
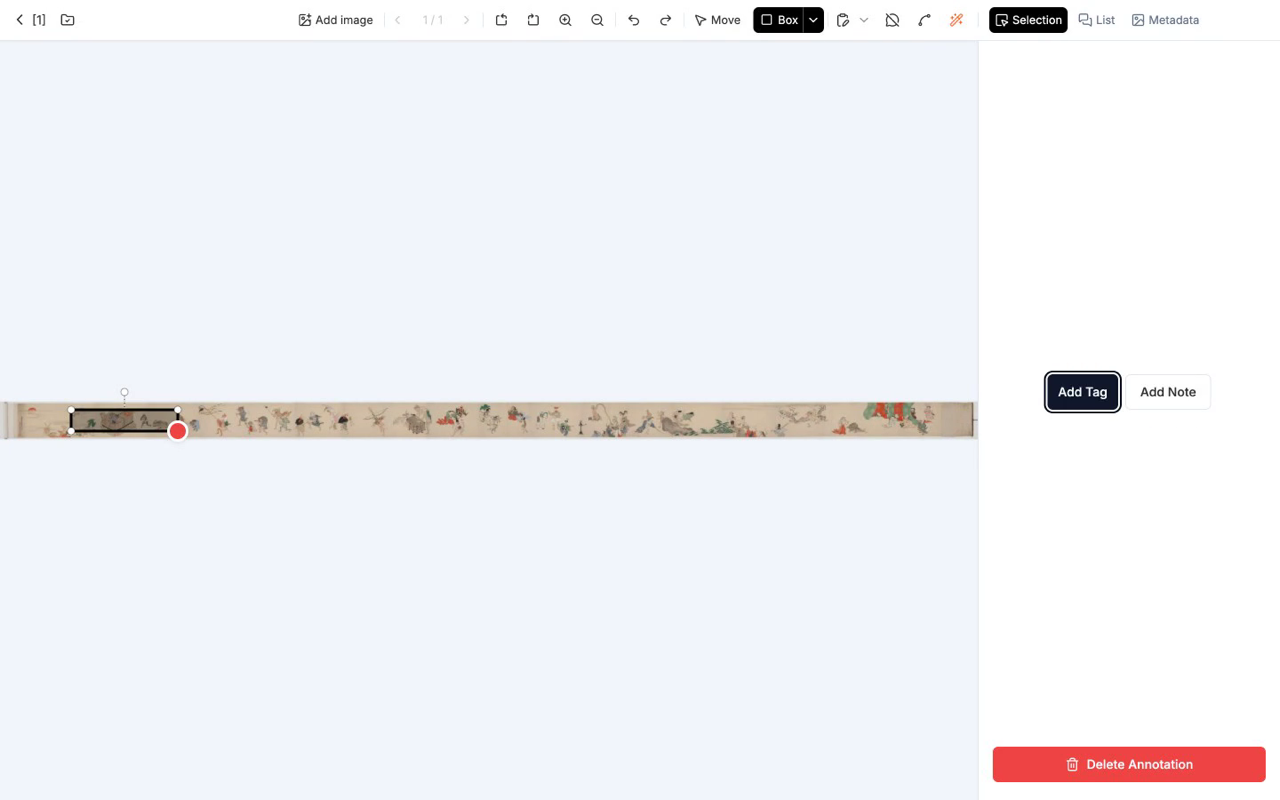
ここで、先ほど設計した Entity Class から該当するものを選び、プロパティに値を入れます。たとえば最初の妖怪を Yokai > Oni、性別不明、推定体長 1.8 m と入れる、といった具合です。
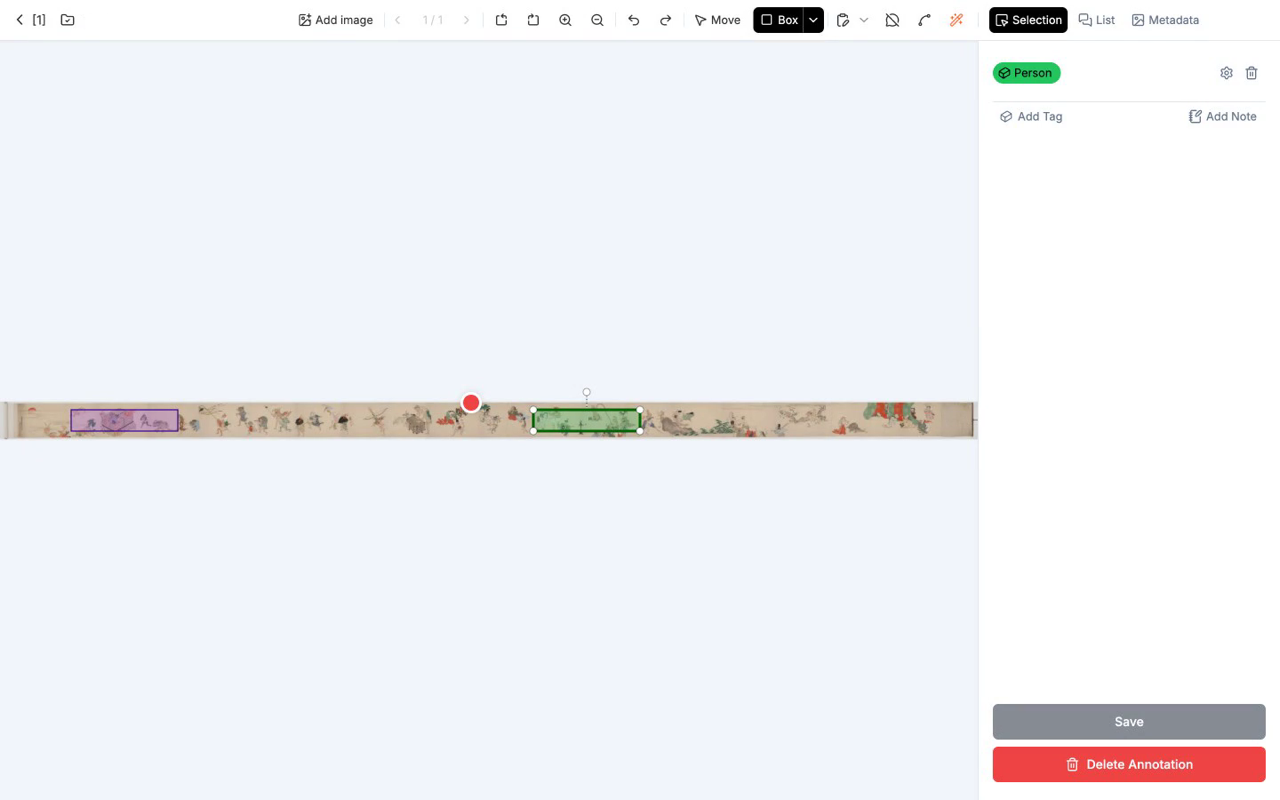
6.4 出力 JSON を読む
注釈を 1 つ作ると、_iiif.<id>.annotations.json に次のような JSON が追記されます(実出力例)。
[
{
"id": "886bae64-8929-4c61-b9f3-a1a38e099e89",
"target": {
"source": "iiif:a9dfe98422a0aac0:3318151926",
"type": "SpecificResource",
"selector": {
"type": "FragmentSelector",
"conformsTo": "http://www.w3.org/TR/media-frags/",
"value": "xywh=pixel:30652.79,1230.49,496.33,526.99"
}
},
"@context": "http://www.w3.org/ns/anno.jsonld",
"type": "Annotation",
"body": [
{ "id": "...", "type": "Dataset", "purpose": "classifying", "source": "Person",
"created": "2026-05-06T23:07:14.531Z" }
],
"created": "2026-05-06T23:07:10.286Z",
"creator": { "isGuest": true, "id": "X3_WHIhjPtfp8Iu1lGMe" }
}
]
この JSON には、研究上のポイントが 3 つ含まれています。
target.sourceに IIIF Canvas の参照が入るため、元資料へのリンクが切れません。selector.valueが W3C Media Fragments に準拠しているため、別ツールでも同じ領域を再現できます。body[].purpose: "classifying"により、「分類目的の注釈である」というセマンティクスが明示されます。
この 1 件の JSON は、IIIF 互換のビュアー(Mirador、Universal Viewer、Annona など)でも再現できる研究データになっています。
7. エンティティ間に関係を引く
人物 A と妖怪 B が向き合っている、付喪神 C は道具 D から派生している——こうした関係は Relations タブで描けます。
- ソースとなるエンティティを選択します。
- 「Relation」ボタンを押し、ターゲットとなる別のエンティティをクリックします。
- 既存の関係型を選ぶか、新しい関係型を作ります(例:
faces、derives_from)。
書き出された _immarkus.relations.json も、同じく W3C Web Annotation 形式で記録されます。
8. Knowledge Graph で俯瞰する
注釈が増えてきたら Knowledge Graph タブへ移ります。
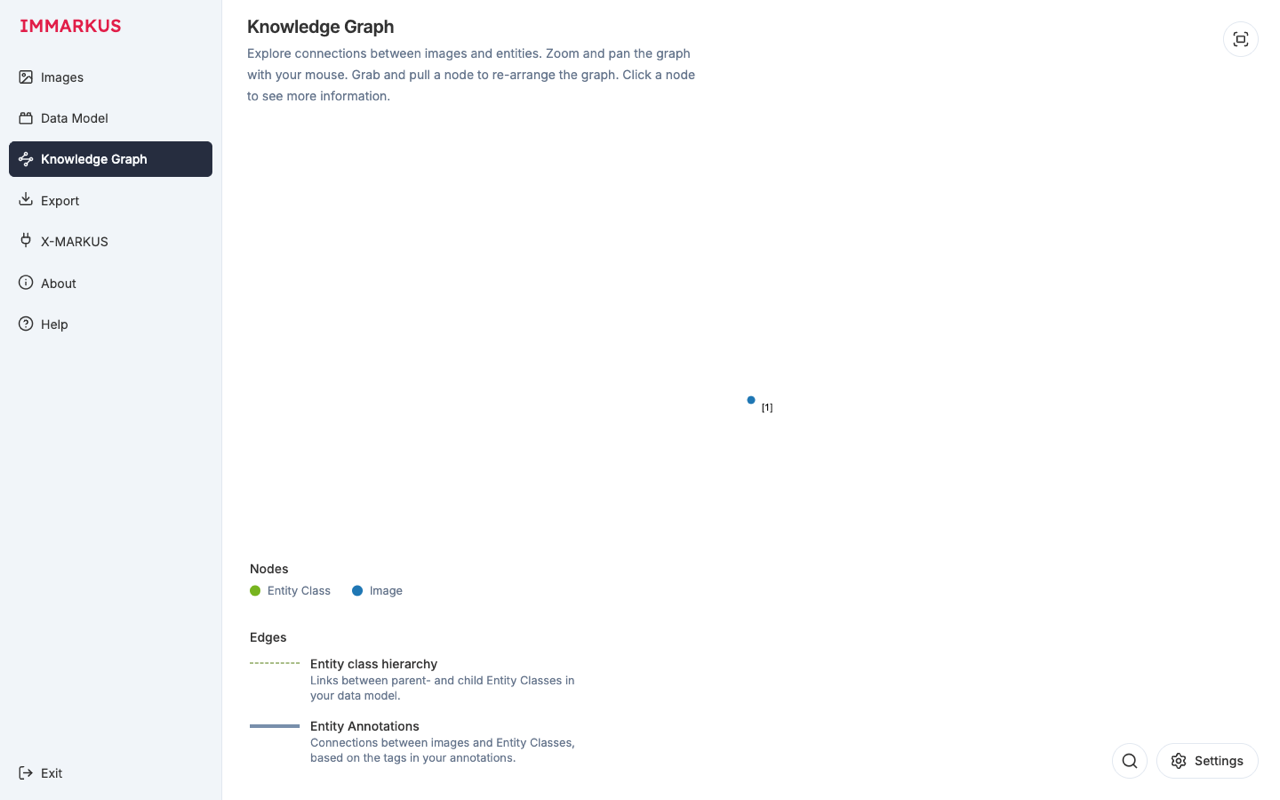
- 青ノードが画像、緑ノードがエンティティクラスです。
- 線の太さは接続数を表します。
- Hierarchy & Annotations モード:データモデル構造と分類注釈を表示します。
- Relations モード:エンティティ間の関係注釈だけに絞って表示します。
検索パネルでは AND / OR 条件を組み合わせられます。たとえば「Yokai のうち、era プロパティが江戸期で、faces 関係でつながっている Person がある画像」のような複合クエリを書けます。結果は XLSX としてエクスポートできるため、論文や報告書向けの集計に使えます。
9. エクスポート:成果を持ち出す
Export 画面は Annotations / Relationships / Data Model / Metadata の 4 サブタブに分かれています。
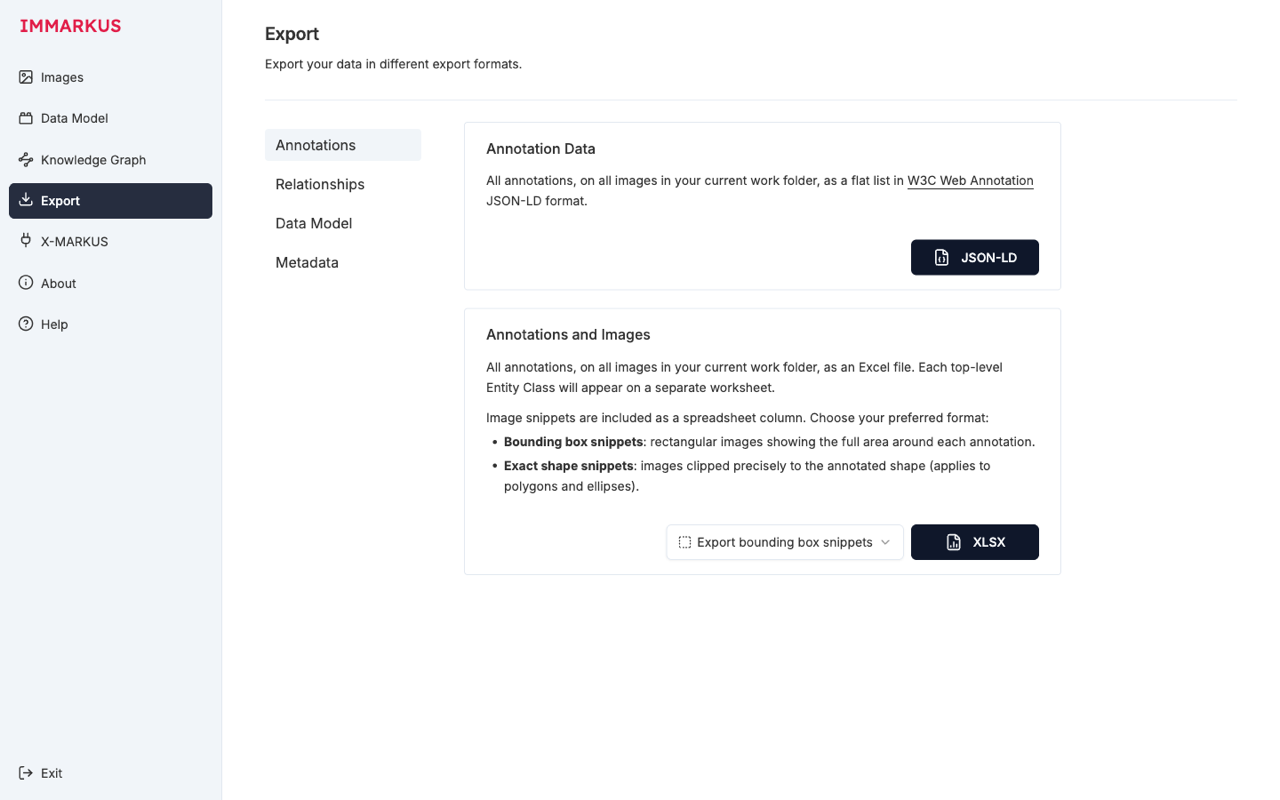
| 対象 | 形式 | 用途 |
|---|---|---|
| 注釈 | W3C Web Annotation JSON-LD | 別ツール(Mirador など)への持ち込み、Linked Data 公開 |
| 注釈 | XLSX(画像スニペット付き) | 共著者へのレビュー依頼、紙資料化 |
| 関係 | W3C Web Annotation JSON-LD / XLSX | ネットワーク分析(Gephi など) |
| データモデル | JSON | 別プロジェクトへの再利用、論文付録 |
| メタデータ | CSV | データ管理、目録作成 |
書き出されるファイル名は annotations.json / annotations.xlsx / relationships.json / relationships.xlsx / entity-classes.json / image_metadata.csv です。image_metadata.csv には、IIIF Manifest 由来のタイトル・所蔵機関・Manifest URI などが取り込まれます。
XLSX 形式ではエンティティクラスごとにシートが分かれ、プロパティが列に展開され、行頭に注釈領域を切り出した画像スニペットが埋め込まれます。スニペットの切り取り方は、次の 2 形式から選べます。
- Bounding box snippets:注釈周囲を含む矩形でクリップします。形を問わず一律に揃います。
- Exact shape snippets:ポリゴンや楕円など、図形の形に沿ってクリップします。
共同研究者が IMMARKUS を導入していなくても、Excel があれば内容を確認できます。
10. 引用とライセンス
IMMARKUS のリポジトリには CITATION.cff が含まれており、論文や報告書での引用方法が示されています。研究で利用した場合は、プラットフォーム・コード・Wiki のいずれかを引用します。研究助成は ERC(grant agreement No. 101019509)です。
11. トラブルシューティング
- 画像が読み込めない:ローカル画像は 10 MB 以下にします。容量を超えると、エラー表示なく失敗することがあります。
- IIIF マニフェストが弾かれる:CORS が許可されていない配信元があります。Wiki の Troubleshooting IIIF Manifest Imports に既知の機関リストがあります。
- フォルダ権限が外れる:ブラウザのセッションが切れると、再度 Edit files を求められます。データは保持されます。
12. 次のステップ:MARKUS ファミリーへ
サイドバーの X-MARKUS をクリックすると、IMMARKUS が MARKUS ファミリーと呼ばれる一連のデジタル人文学プラットフォームの一員であることが分かります。
| ツール | 対象 |
|---|---|
| MARKUS | テキスト史料へのマークアップ(特に漢文) |
| COMARKUS | 共同マークアップ |
| X-MARKUS | 異種コンテキスト統合環境 |
| MUNDa | マルチメディア(画像・地図・文書)統合環境 |
| COMPARATIVUS | テキスト同士の比較分析 |
| PARALLELS | テキスト間の対応関係抽出 |
IMMARKUS が画像分析を担い、MARKUS が同じ史料のテキスト面を担当する、というように、史料の側面ごとにツールを使い分けて統合できる構成です。中国史を主眼に開発されていますが、エマキや写本など東アジアの史料一般にも応用できます。
このほか、より技術的な拡張として次の選択肢があります。
- Mirador と組み合わせる:エクスポートした W3C Web Annotation を Mirador のアノテーションエンドポイントに渡すと、ビューア中心の閲覧フローに移行できます。
- 自前ホスティング:
git clone && npm install && npm run buildでdist/を任意の静的サーバに置けます。研究室内で運用を完結させたい場合に向きます。 - AI 連携の拡張:内部的に OpenAI / Google GenAI / Hugging Face / Azure CV / Gradio を呼べる作りなので、組織のキーを設定して Auto Transcribe の精度を上げられます。
まとめ
IMMARKUS で作った注釈は、最初から W3C Web Annotation 形式の Linked Data として保存されます。ブラウザでフォルダを開き、データモデルを設計し、画像に図形を描いてクラスを割り当てる——この一連の操作だけで、注釈は他のツールでも再利用できる形式のデータになります。研究データ向けに後から変換する工程を挟まずに済む点が、IMMARKUS を使う主な利点です。
参考リンク
- IMMARKUS リポジトリ:https://github.com/rsimon/immarkus
- IMMARKUS Wiki:https://github.com/rsimon/immarkus/wiki
- W3C Web Annotation Data Model:https://www.w3.org/TR/annotation-model/
- IIIF Presentation API 3.0:https://iiif.io/api/presentation/3.0/
- 東京大学デジタルアーカイブ:https://da.dl.itc.u-tokyo.ac.jp/



コメント
…