😊Challenges and Solutions for Preserving Order in PDF Transparent Text Extraction
Challenges and solutions for preserving order in PDF transparent text extraction
pdfocr
Challenges and solutions for preserving order in PDF transparent text extraction

Creating PDFs from TEI/XML of the Koui Genji Monogatari Text Database

Creating a transparent text PDF from a single page using Google Cloud Vision API
Trying Out File Information Tool Set (FITS)

Creating PDF Files from IIIF Manifest Files

Converting TEI XML to LaTeX Using TEI Critical Apparatus Toolbox
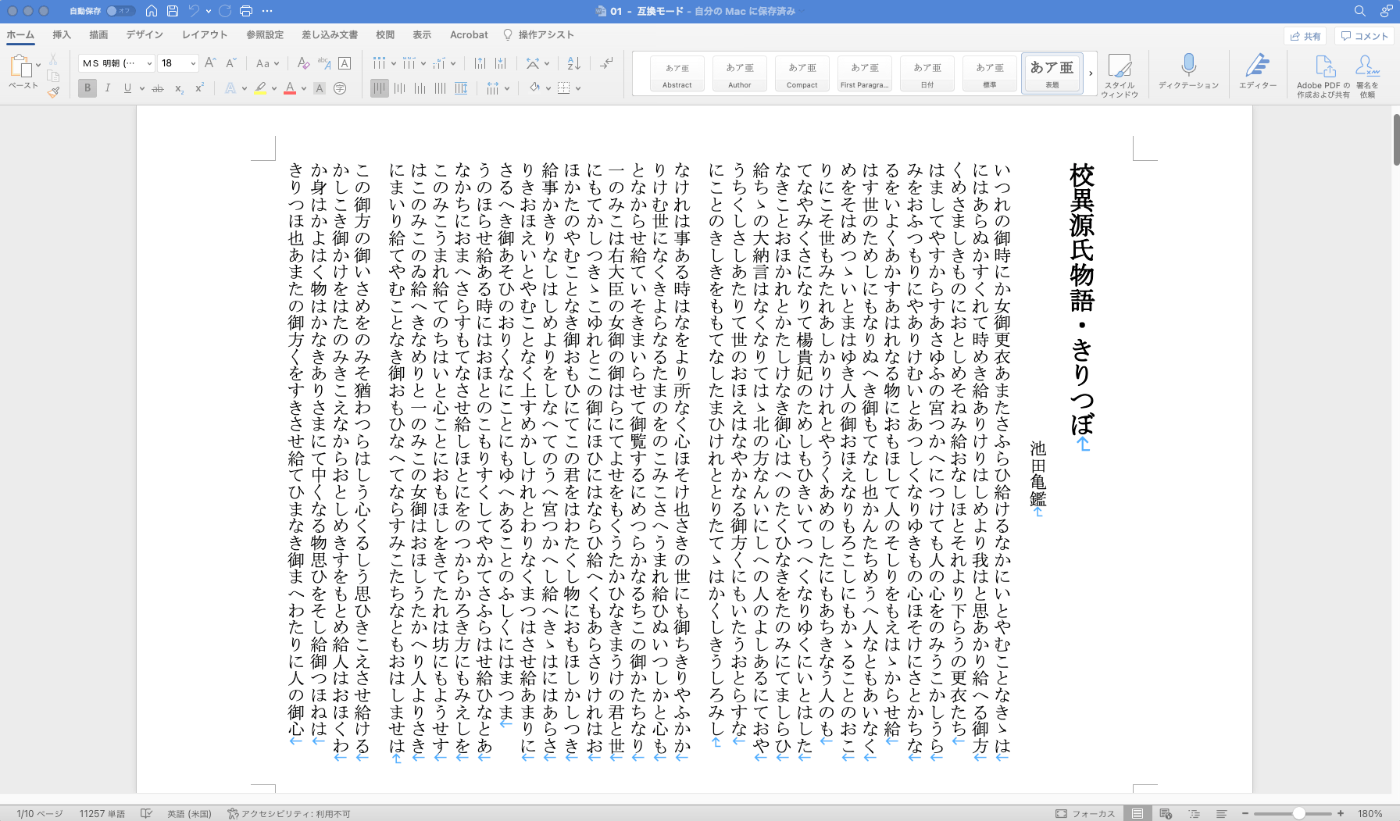
An Example Method for Converting TEI/XML Files to Vertical-Writing PDF