🐈ODD編集Tips:その1
ODD編集Tips:その1
xmlrngteiodd
ODD編集Tips:その1
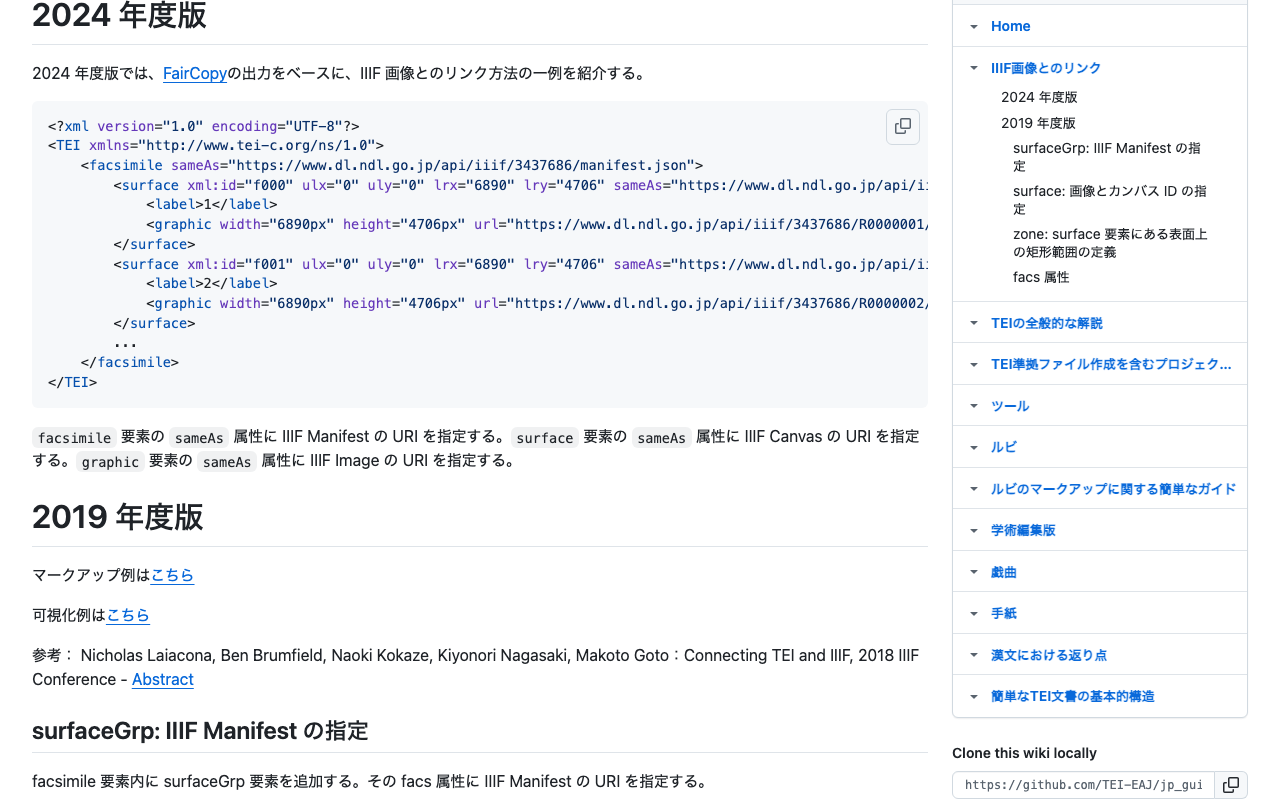
TEI ODDによるIIIF対応ファクシミリ記述の制約設計

TEI ODDファイルのカスタマイゼーション:NDL古典籍OCRの事例
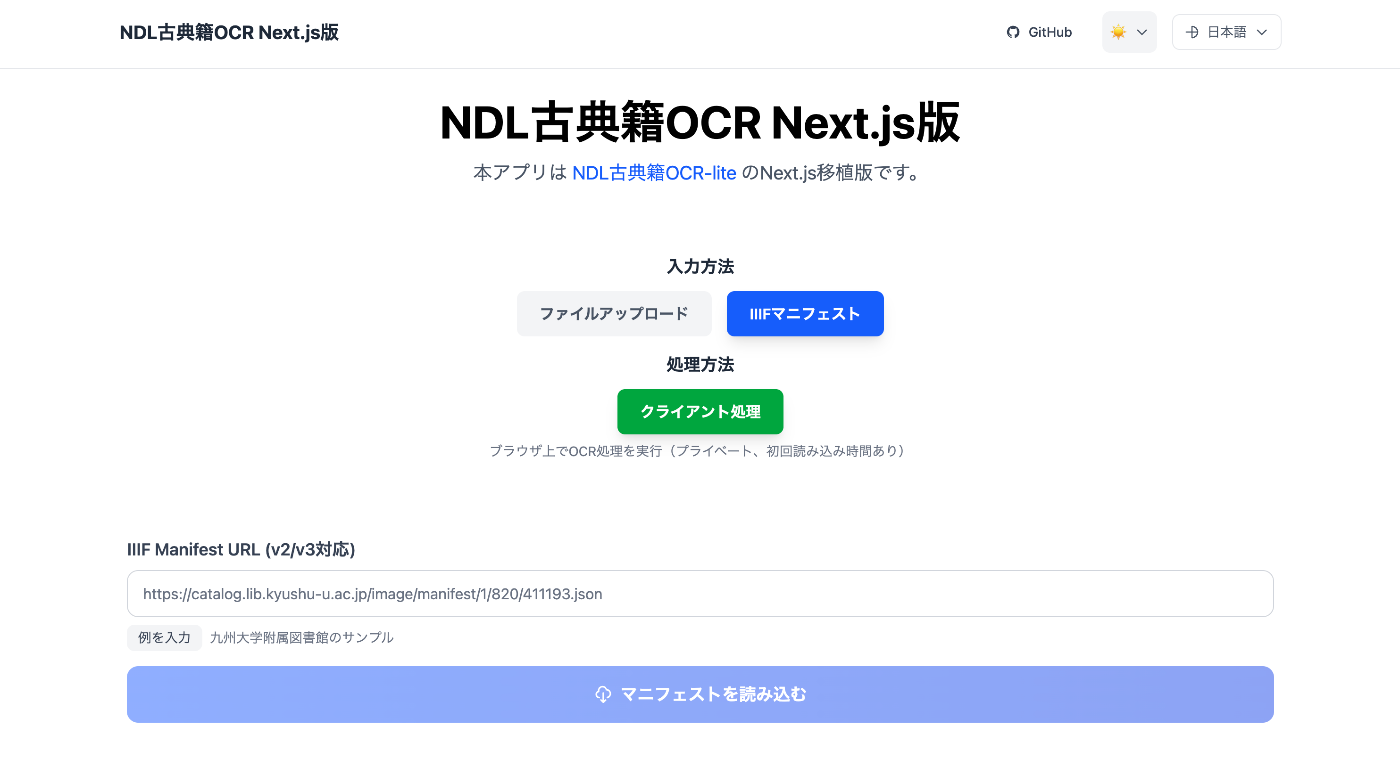
NDL古典籍OCR-lite Next.js版の開発

RELAX NGとSchematronを組み合わせたTEI XMLスキーマの実装ガイド

生成AIを用いてプロジェクトに特化したrngファイルを作成する

Romaを使ってタグの属性に使用可能な値を限定する
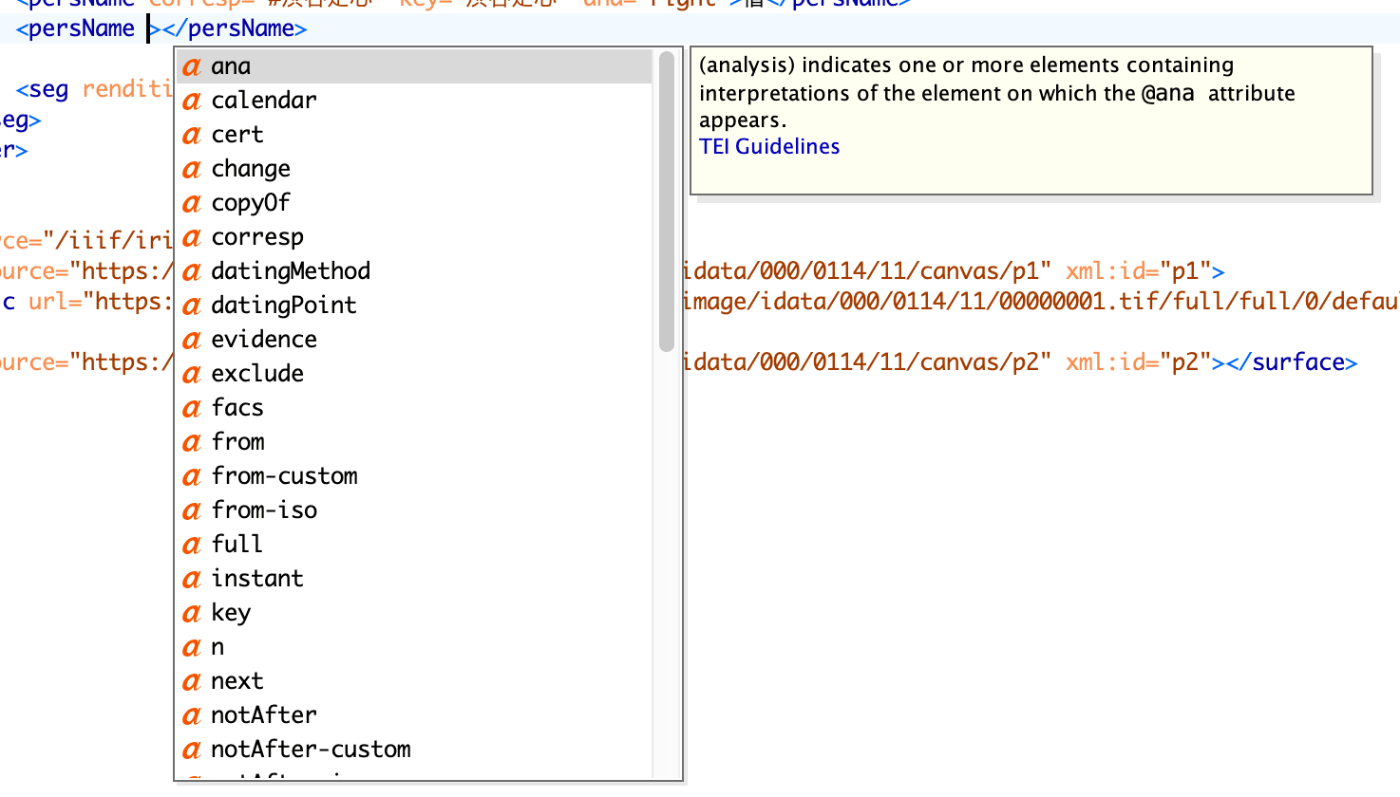
Romaを使ってプロジェクトに応じたタグに使用する属性を限定する

RELAX NGとSchematron

Romaを使ってプロジェクトに応じたタグを限定し、解説を作成する
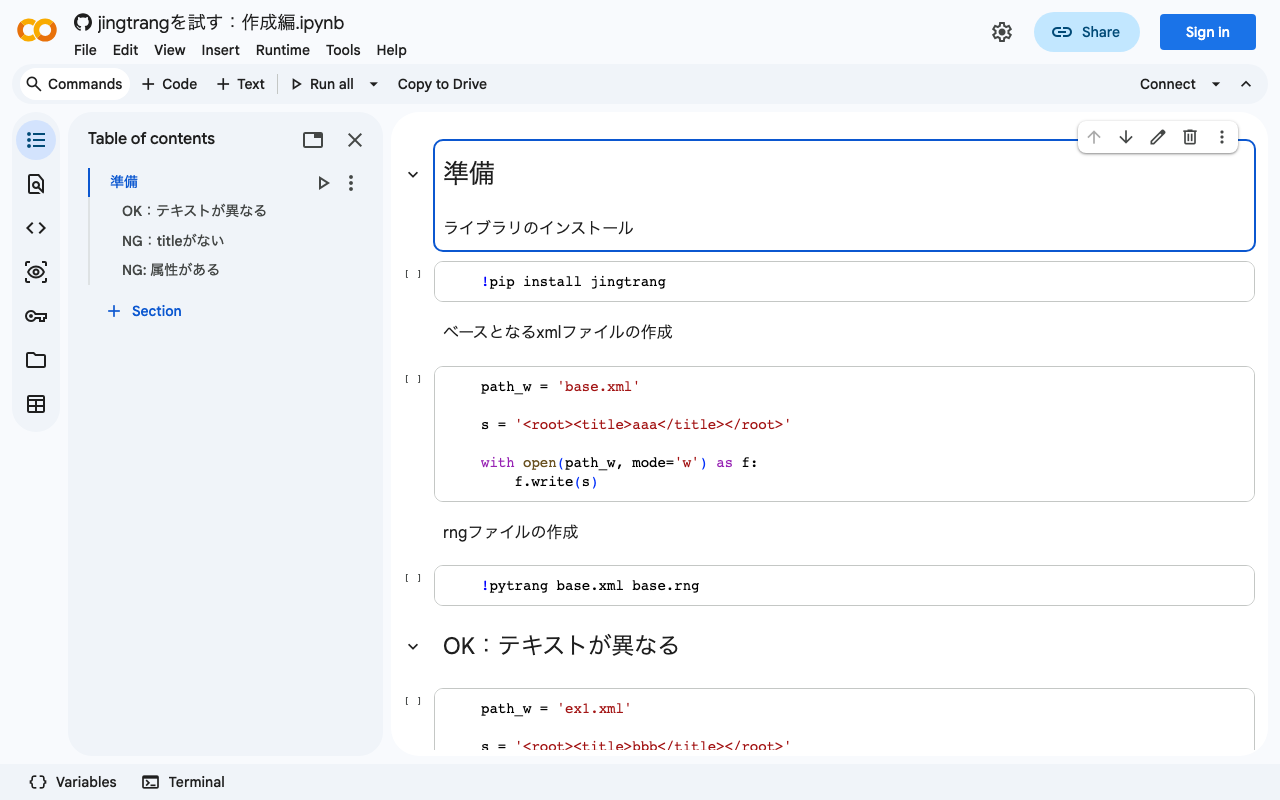
RELAX NGスキーマを操作するライブラリjingtrangを試す:rngファイルの作成編
RELAX NGスキーマを操作するライブラリjingtrangを試す:検証編