🤗YOLOv5モデルをHugging Face Hub & Spacesにデプロイする手順
YOLOv5の学習済みモデル(best.pt)をHugging Face HubにアップロードしてModel Cardを設定し、Gradio製のデモをSpacesにデプロイするまでの手順と、発生したトラブルの解決策をまとめます。
yolov5huggingfacegradiopytorch
YOLOv5の学習済みモデル(best.pt)をHugging Face HubにアップロードしてModel Cardを設定し、Gradio製のデモをSpacesにデプロイするまでの手順と、発生したトラブルの解決策をまとめます。

NDL古典籍OCR-Liteを用いて、IIIFマニフェストファイルからTEI/XMLファイルを作成する
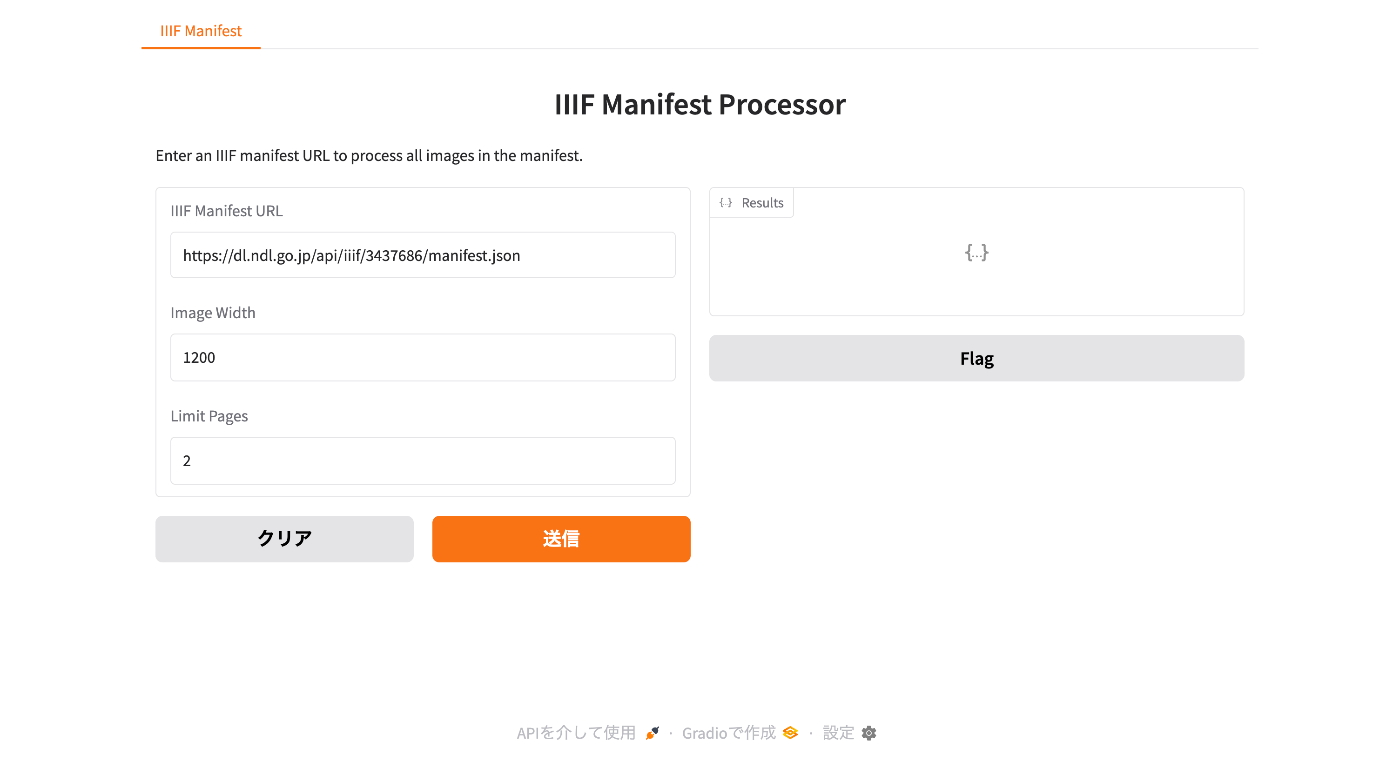
NDL古典籍OCR-Liteを用いたアノテーション付きIIIFマニフェストファイルとTEI/XMLファイルの作成
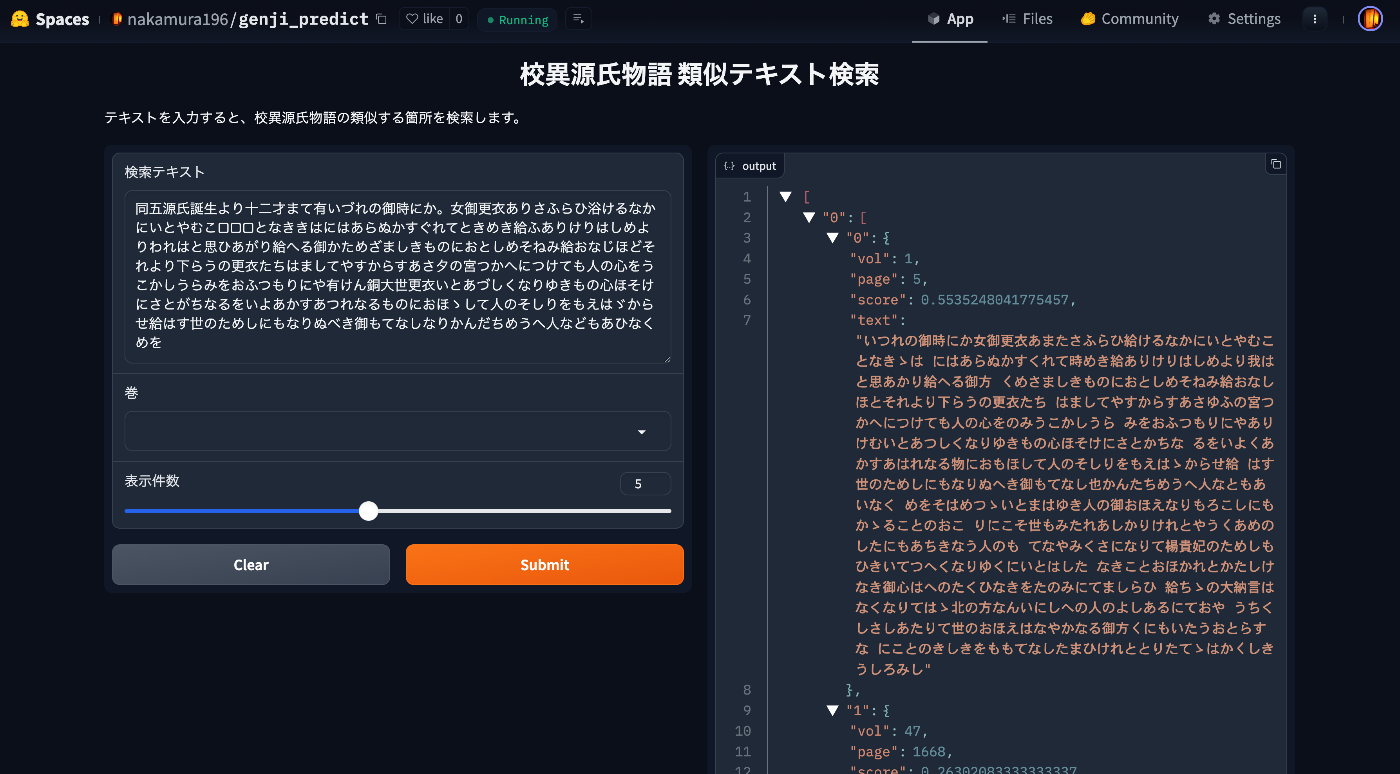
校異源氏物語に対する類似テキスト検索アプリを作成しました。
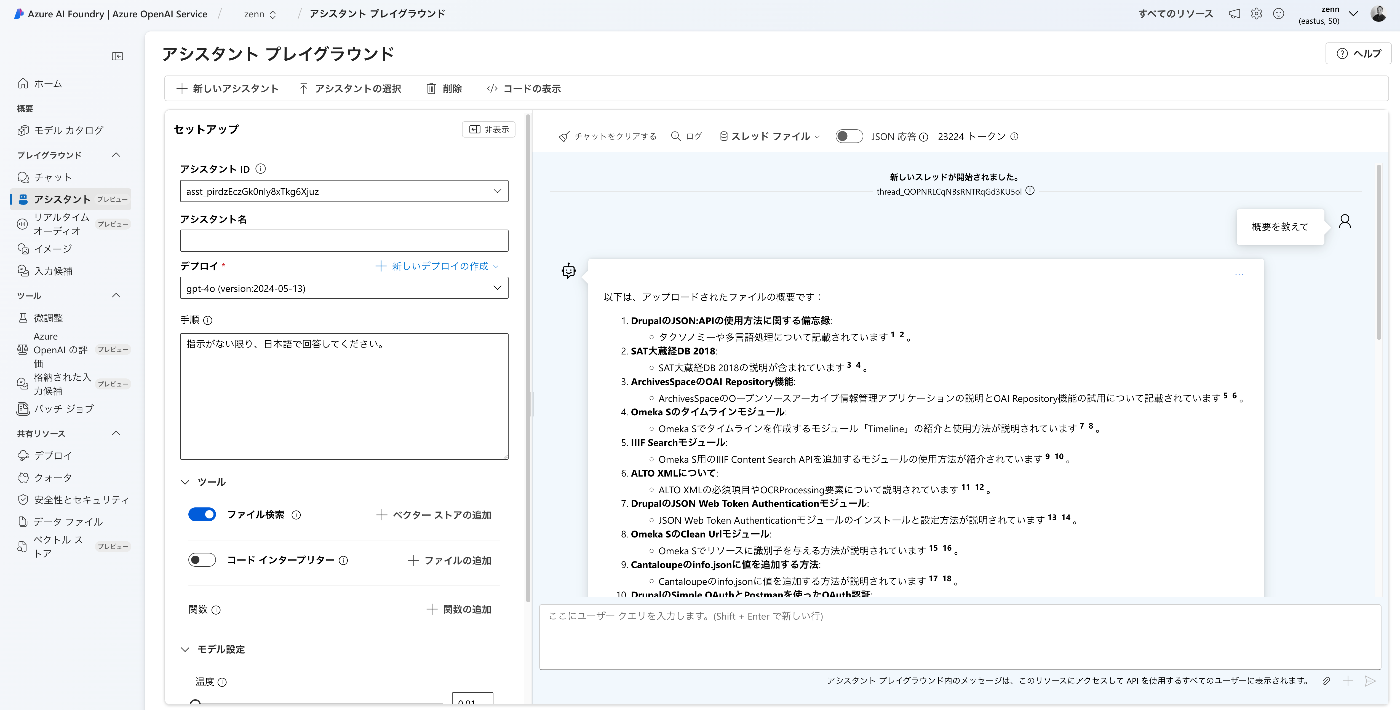
Azure OpenAI Assistants APIを用いたアプリをGradioとNext.jsで作成する
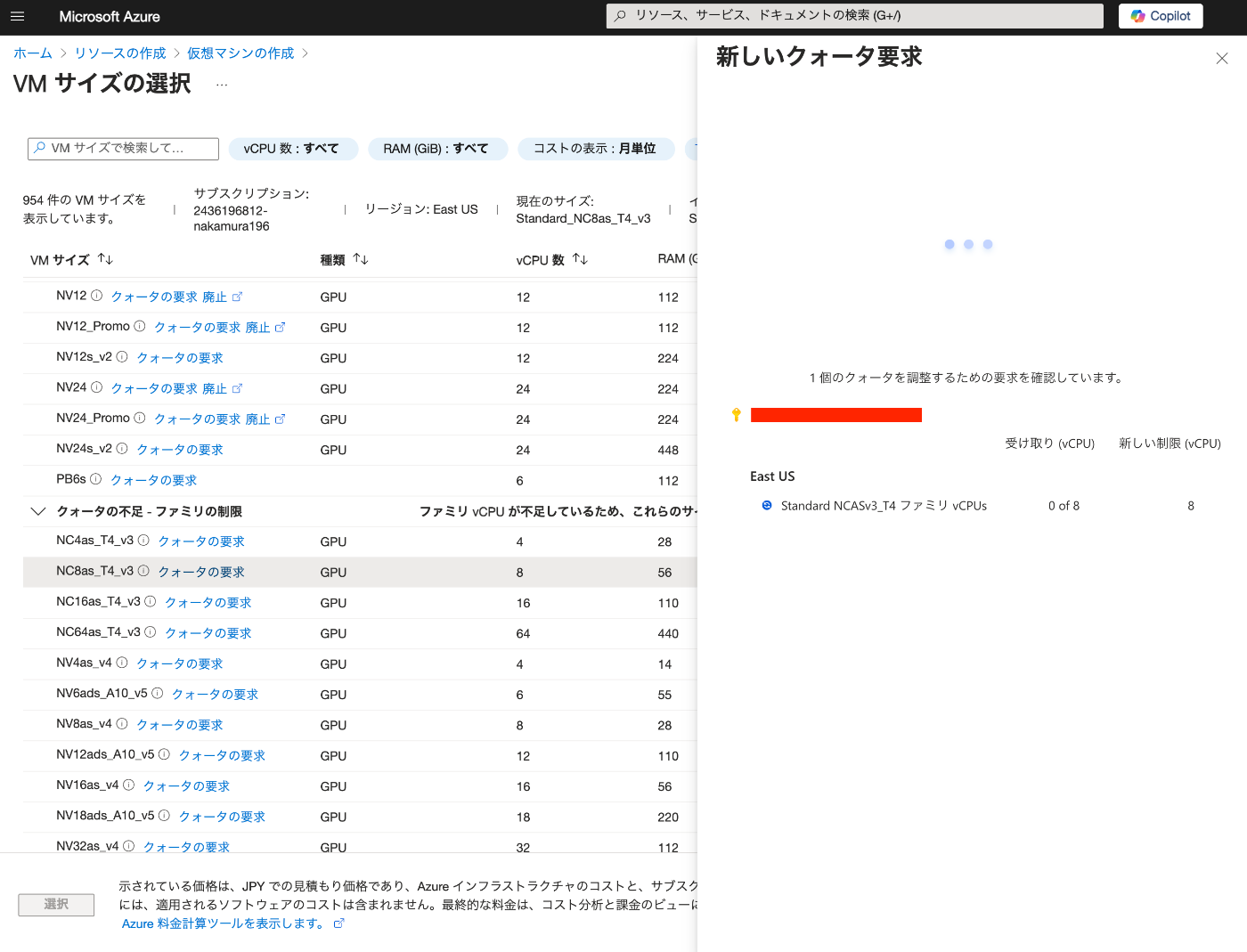
Azureの仮想マシンを用いたNDLOCRのGradioアプリ構築

ndlocr_cli(NDLOCR(ver.2.1)アプリケーションを試すことができるGradioアプリを作成しました。

Azure OpenAIとLlamaIndexとGradioを用いたRAG型チャットの作成

NDL古典籍OCR-Liteを用いたGradio Appを作成しました。

YOLOv5モデル(文字領域検出)を使った推論アプリ
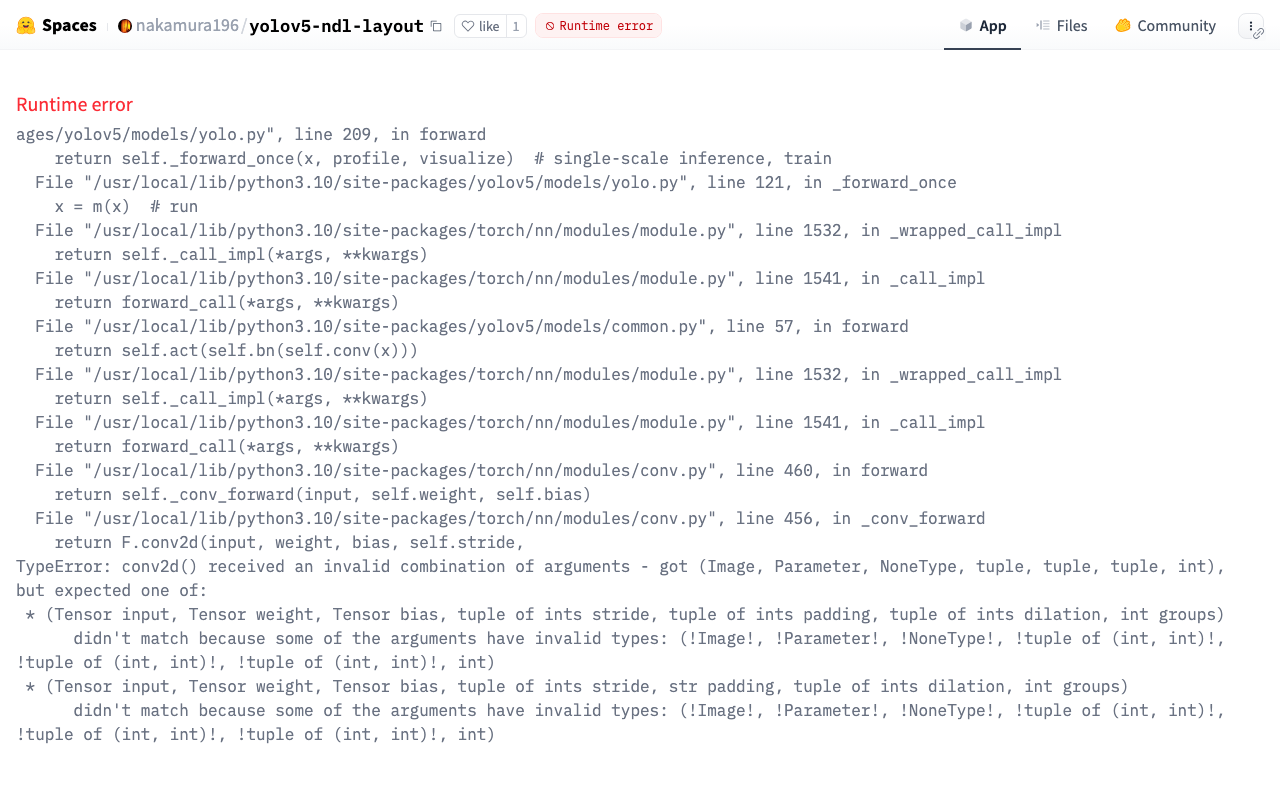
Hugging Face SpacesとYOLOv5モデル(NDL-DocLデータセットで学習済み)を使った推論アプリの修正
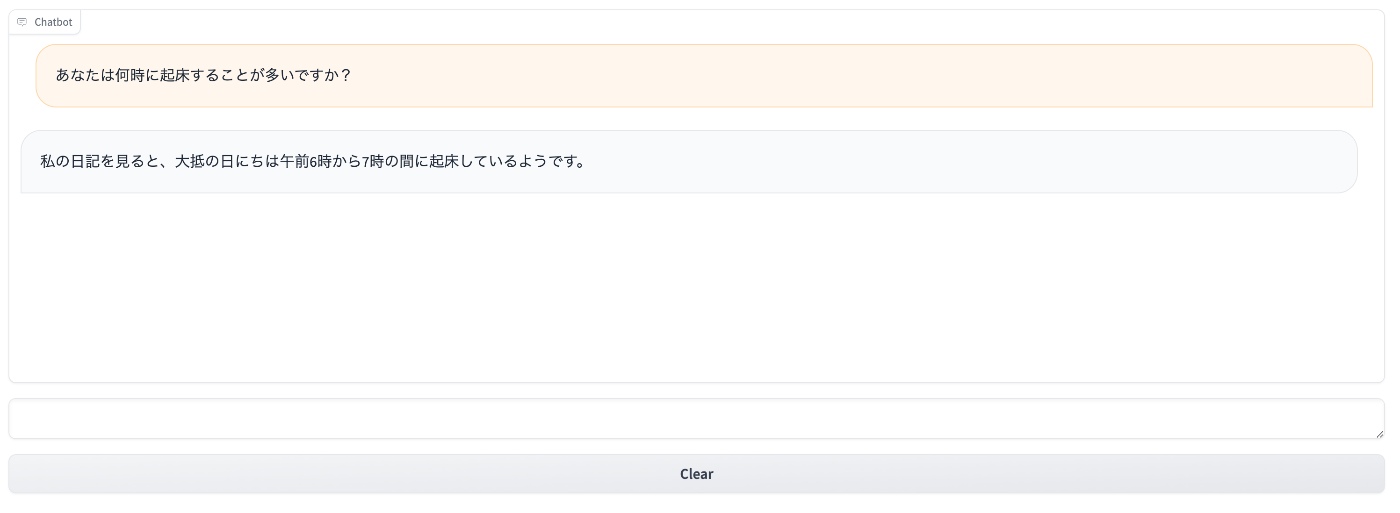
LlamaIndex+GPT4+gradio
学習指導要領コード推薦アプリのAPIを使用する
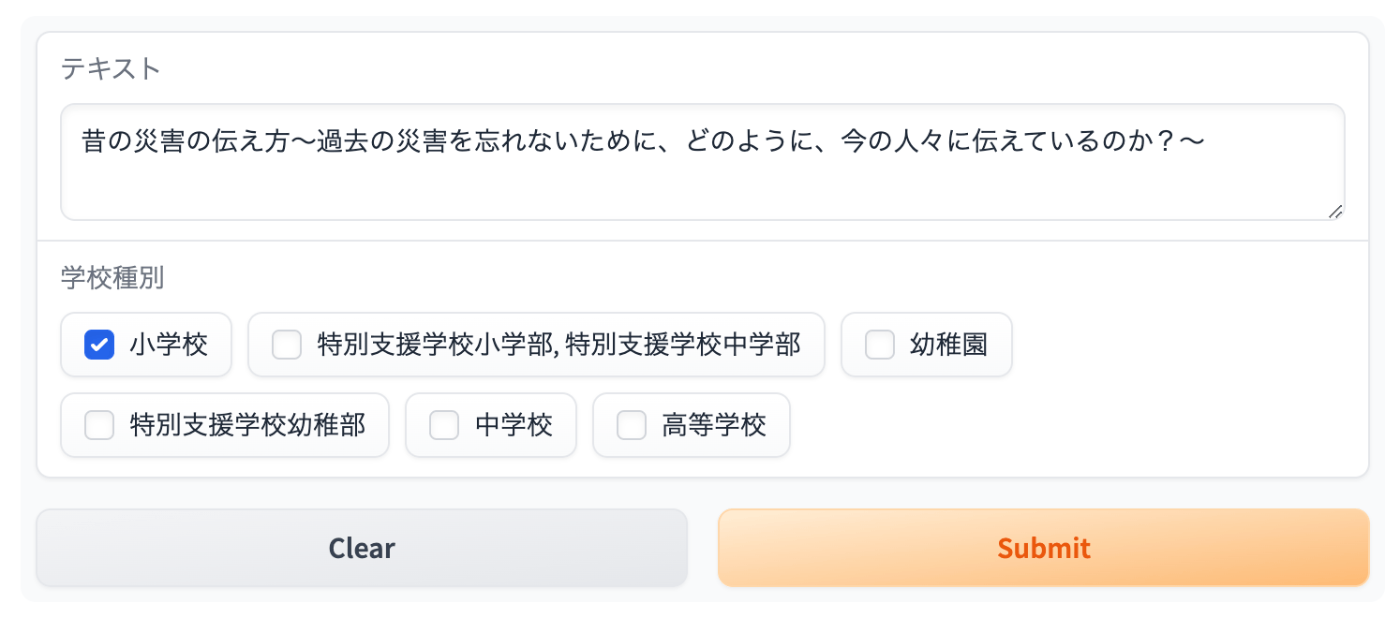
学習指導要領コードの推薦アプリの試作