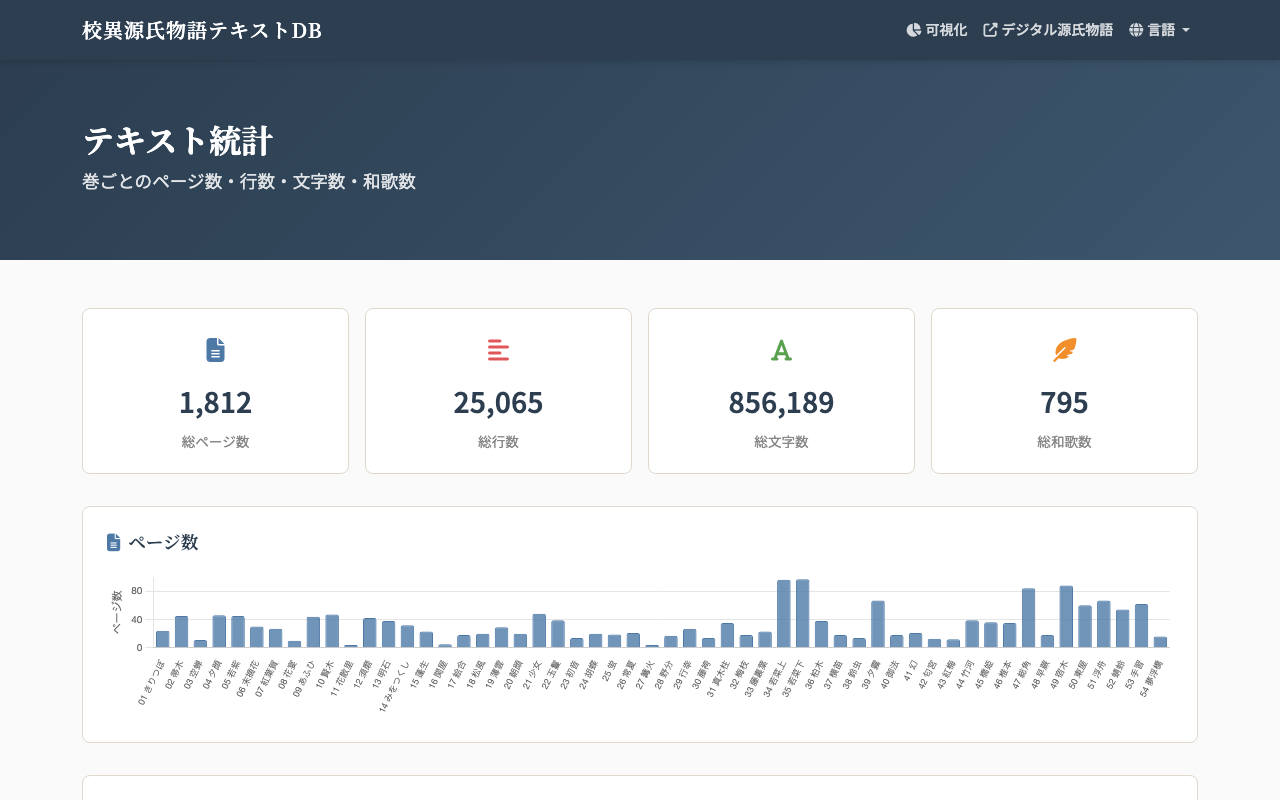
TEI/XMLの翻刻データから統計ページをCI/CDで自動更新する — 『校異源氏物語』テキストDBの事例
TEI/XMLで構造化された翻刻テキストから、巻ごとのページ数・行数・文字数・和歌数を集計する統計ページを生成し、GitHub Actionsで再ビルド・再公開まで自動化する仕組みを紹介します。
teixmldhgithub-actions
TEI/XMLで構造化された翻刻テキストから、巻ごとのページ数・行数・文字数・和歌数を集計する統計ページを生成し、GitHub Actionsで再ビルド・再公開まで自動化する仕組みを紹介します。
OpenITI mARkdownからTEI XMLへの自動変換ツール「oitei」を試す
DHConvalidatorにおける'ref'に関する不具合への対応

tropy-plugin-iiifを試す