
📝Azure OpenAI GPT-4 vs Document Intelligence: 日本語縦書きOCRの比較検証
Azure OpenAI GPT-4 vs Document Intelligence: 日本語縦書きOCRの比較検証
azureocrllm
Azure OpenAI GPT-4 vs Document Intelligence: 日本語縦書きOCRの比較検証
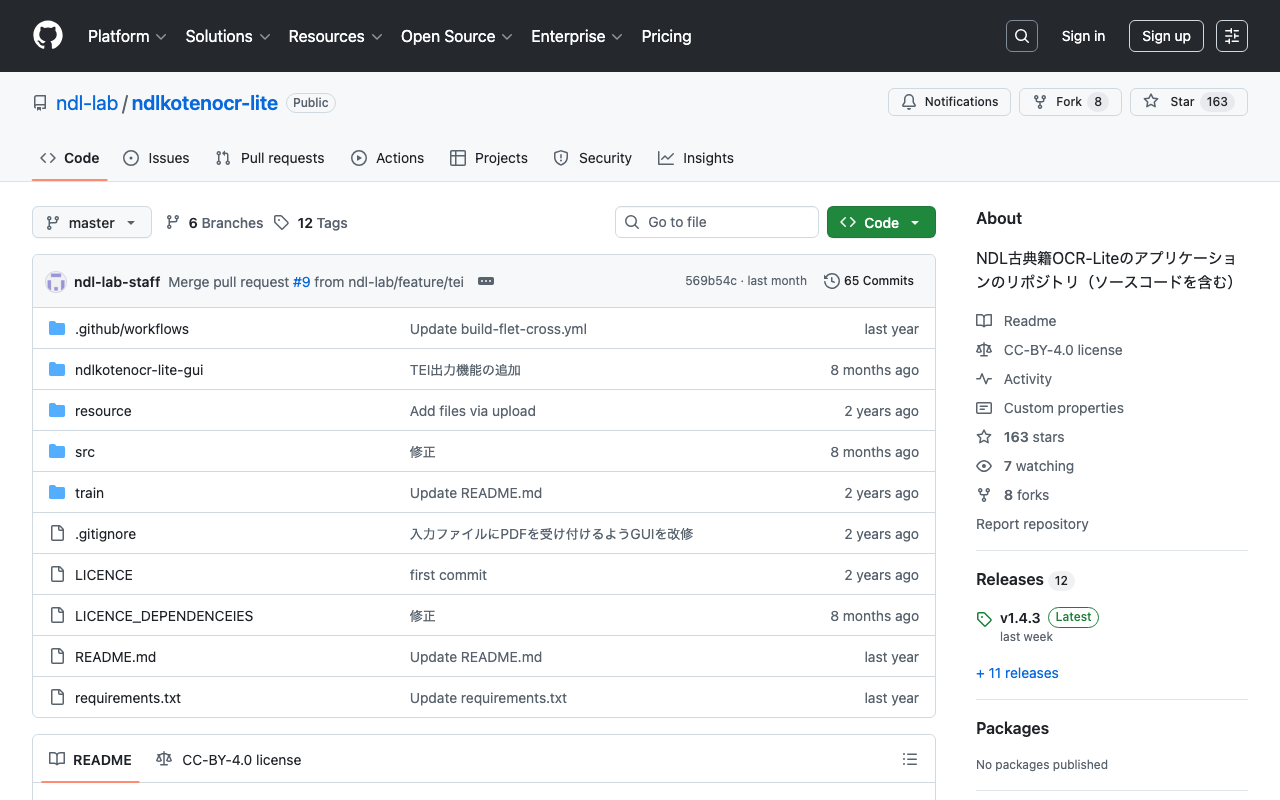
Azure Container AppsでNDL古典籍OCR Liteを用いたスケーラブルOCR処理システム
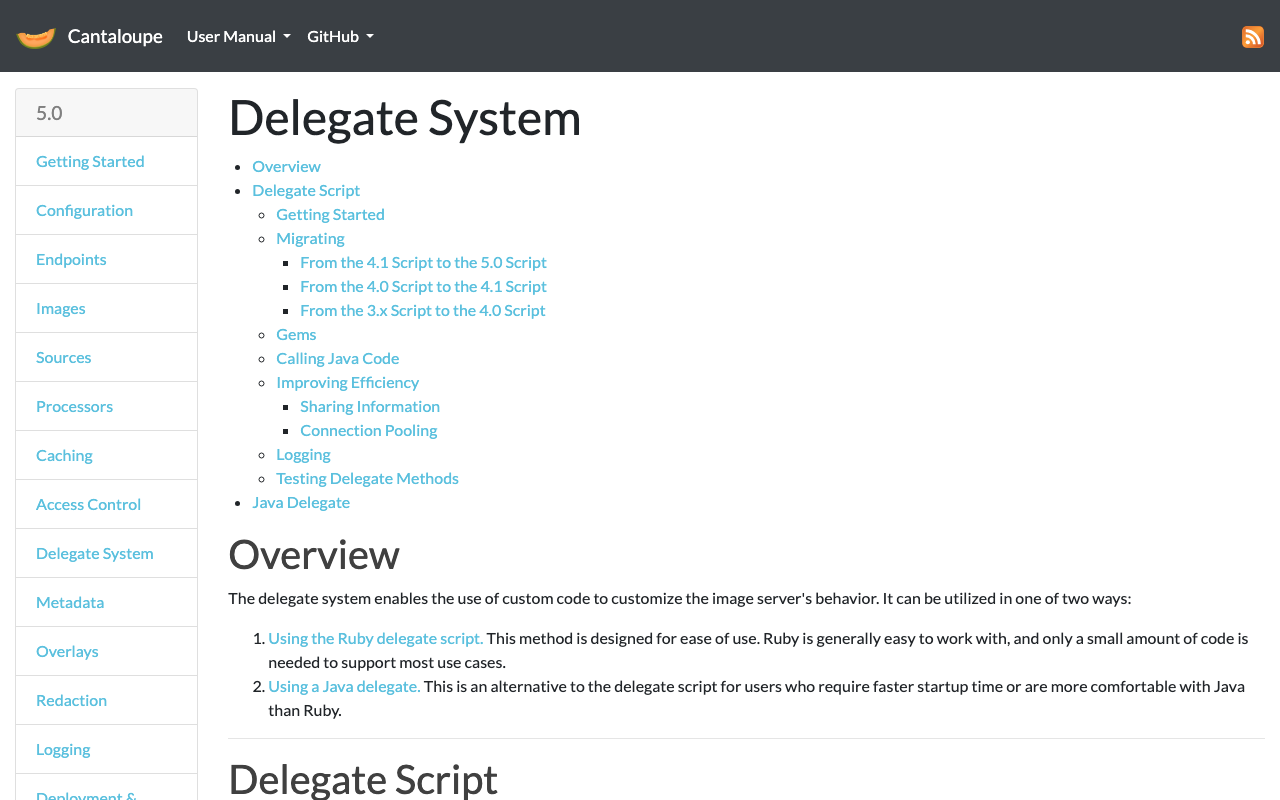
Cantaloupeでdelegate scriptを使ってAzure Storage上のファイルパスを動的に変換する方法
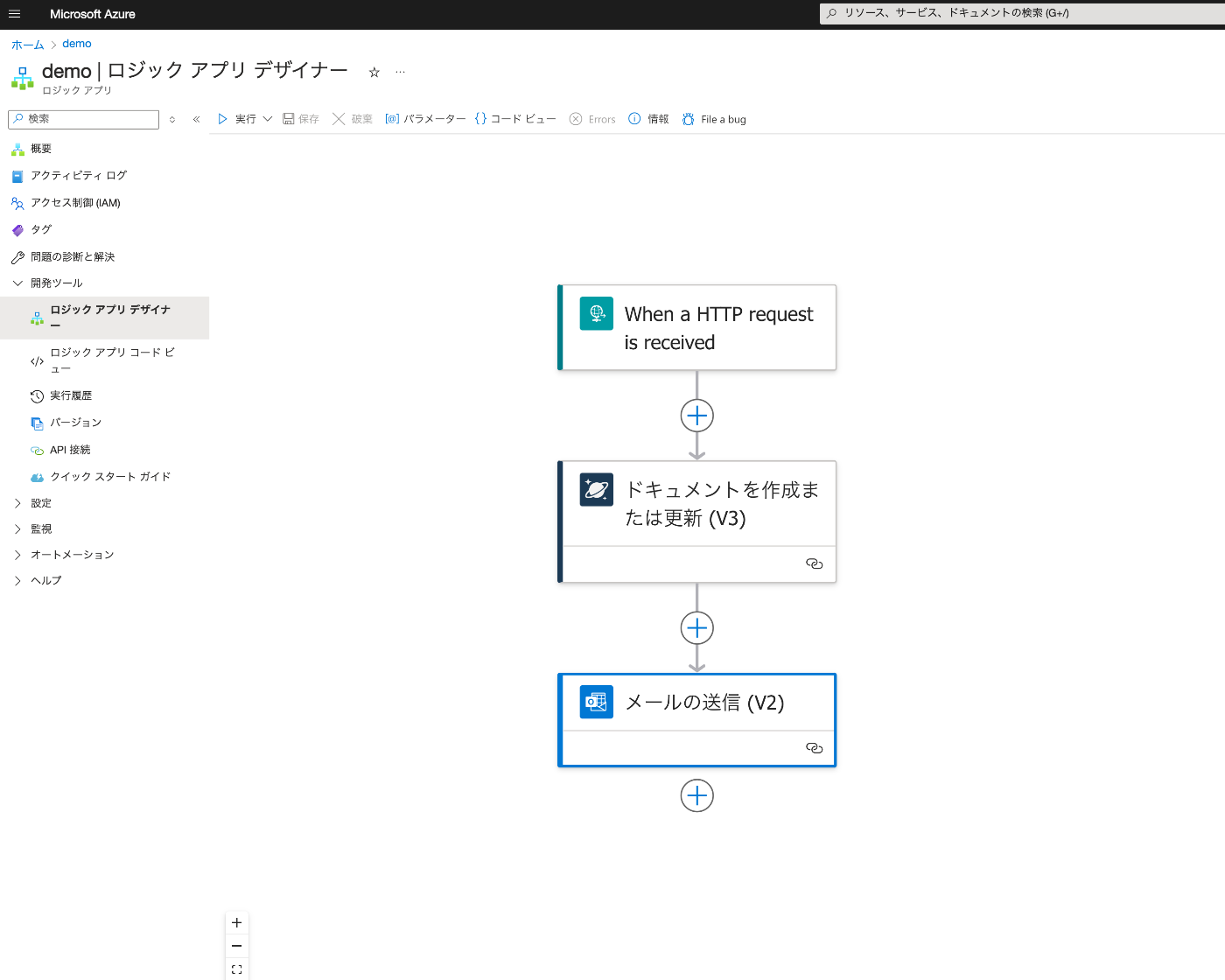
Azure Logic Appsを試す
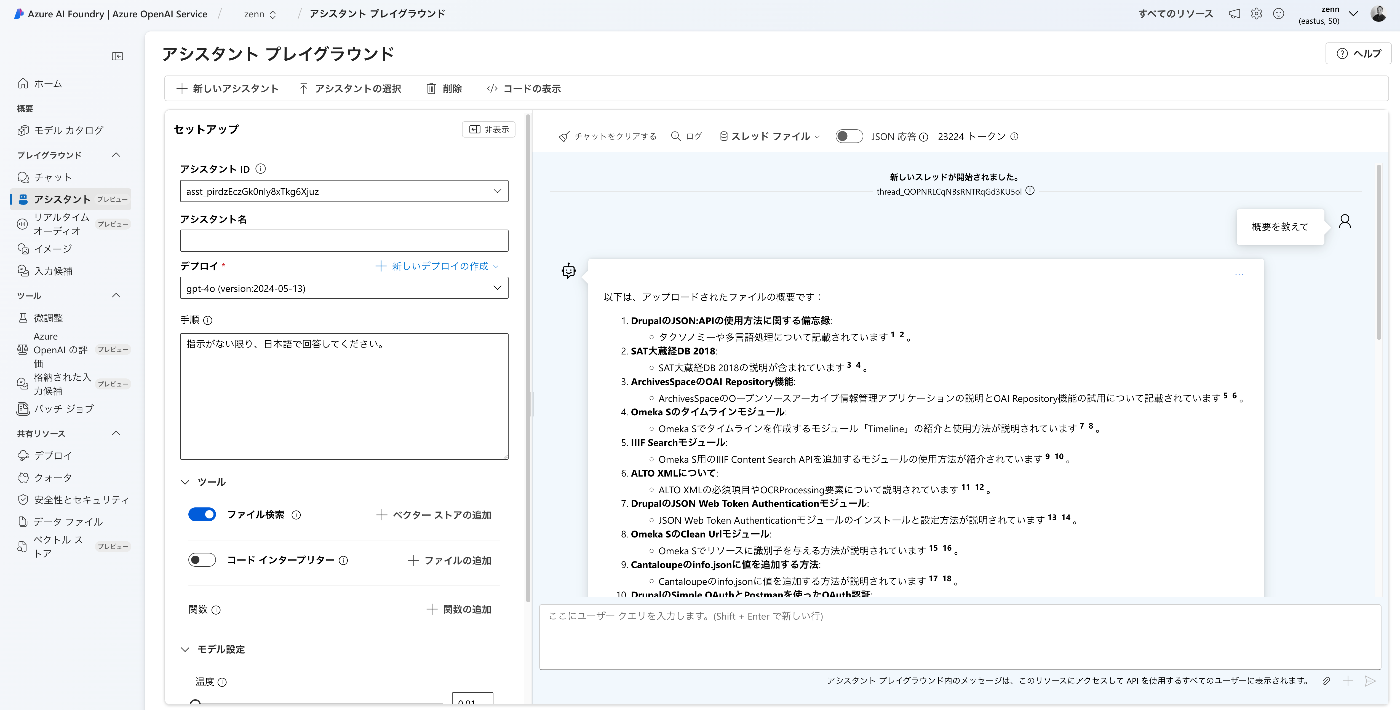
Azure OpenAI Assistants APIを用いたアプリをGradioとNext.jsで作成する
Cantaloupe: Microsoft Azure Blob Storageに格納した画像を配信する
Azureの仮想マシンを用いたNDLOCRのGradioアプリ構築

ndlocr_cli(NDLOCR(ver.2.1)アプリケーションを試すことができるGradioアプリを作成しました。

Azure OpenAIとLlamaIndexとGradioを用いたRAG型チャットの作成