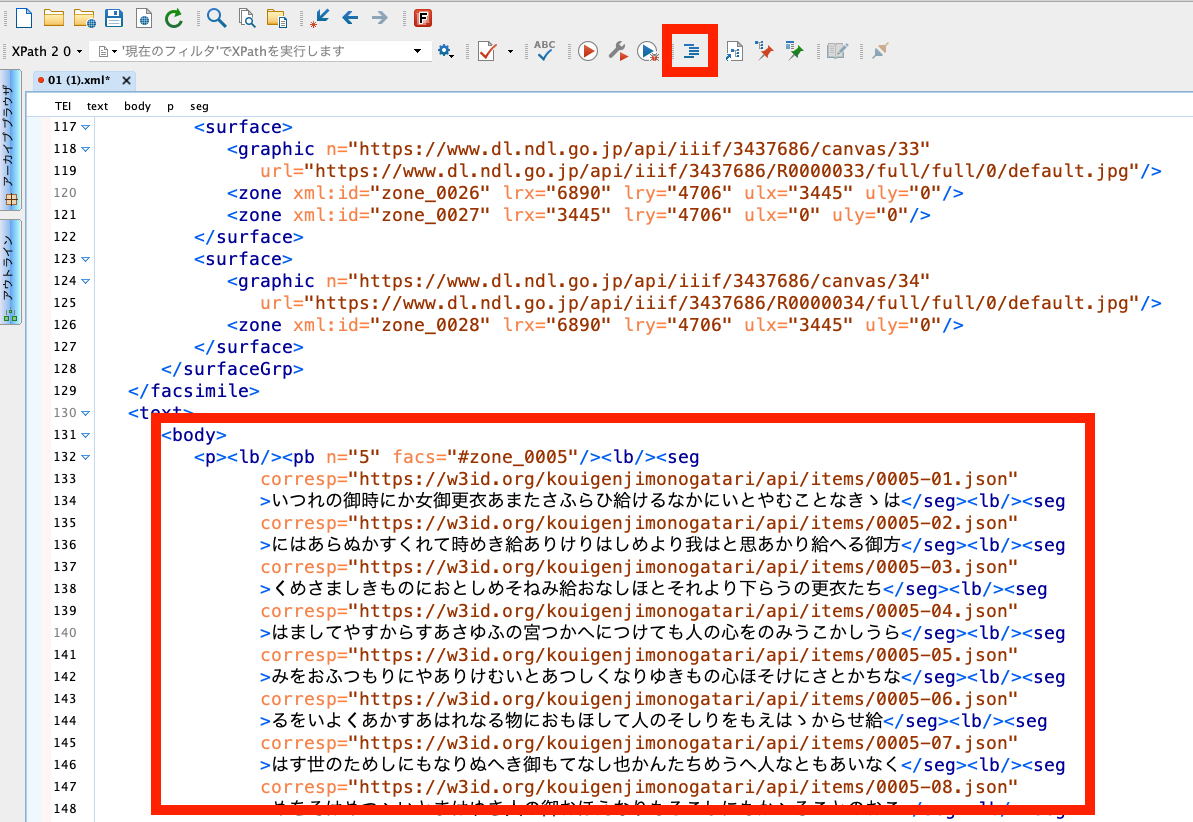
TEIビューアでの利用を想定したCustom OpenSegDragon Viewerを作成しました。
概要 TEIビューアでの利用を想定したCustom OpenSegDragon Viewerを作成しました。 背景 以下のようなTEIとIIIFを対応させたビューア開発において、次に示す機能を持ったビューアが必要でした。 https://www.hi.u-tokyo.ac.jp/collection/digitalgallery/wakozukan/tei/ IIIFのマニフェストファイルを読み込むことができる。 ビューアコンポーネント側でのコマ送りを、コンポーネント外で把握することができる。 画像の部分領域をハイライトすることができる。 上記の要件を全てを満たす既存のIIIF対応ビューアを見つけることができなかったため、独自のビューアの開発を試みました。合わせて、npmパッケージとして公開することも試みました。 開発したビューア ドキュメンテーション等がまだ不十分ですが、以下のページで公開しています。このページで、ソースコードへのリンクも掲載しています。 https://www.npmjs.com/package/@nakamura196/osd-custom-viewer vue3とviteを使ったコンポーネントの開発およびnpmでの公開にあたっては、以下のサイトを参考にしました。 https://blog.egmond.dev/vue-component-to-npm-package 使用例 以下のページで導入例をご確認いただけます。 https://nakamura196.github.io/nuxt3-iiif-viewer/custom-osd コンポーネント内外からのコマ送りが可能です。これにより、例えばIIIF画像とTEIテキストの並列表示を行った際、TEIテキスト側からのコマ送りや、画像のコマ送りによる当該テキストへのスクロールなどを行うことができます。 またハイライト機能用いることで、あるテキスト行に対応した画像の部分領域をハイライトさせる、といったことが可能です。 使用例のソースコードは以下です。 https://github.com/nakamura196/nuxt3-iiif-viewer/blob/main/pages/custom-osd/index.vue ssrでの公開にあたり、pluginsフォルダに以下を追加しています。 https://github.com/nakamura196/nuxt3-iiif-viewer/blob/main/plugins/custom-osd.client.js まとめ ドキュメンテーションの充実や、IIIF v3への対応など、多くのTODOが残っていますが、参考になりましたら幸いです。




![[TEI x JavaScript] Nuxt3で意図しないWhitespaceを削除する](https://storage.googleapis.com/zenn-user-upload/196b3ec8465c-20221025.png)