TEIGarageを試す
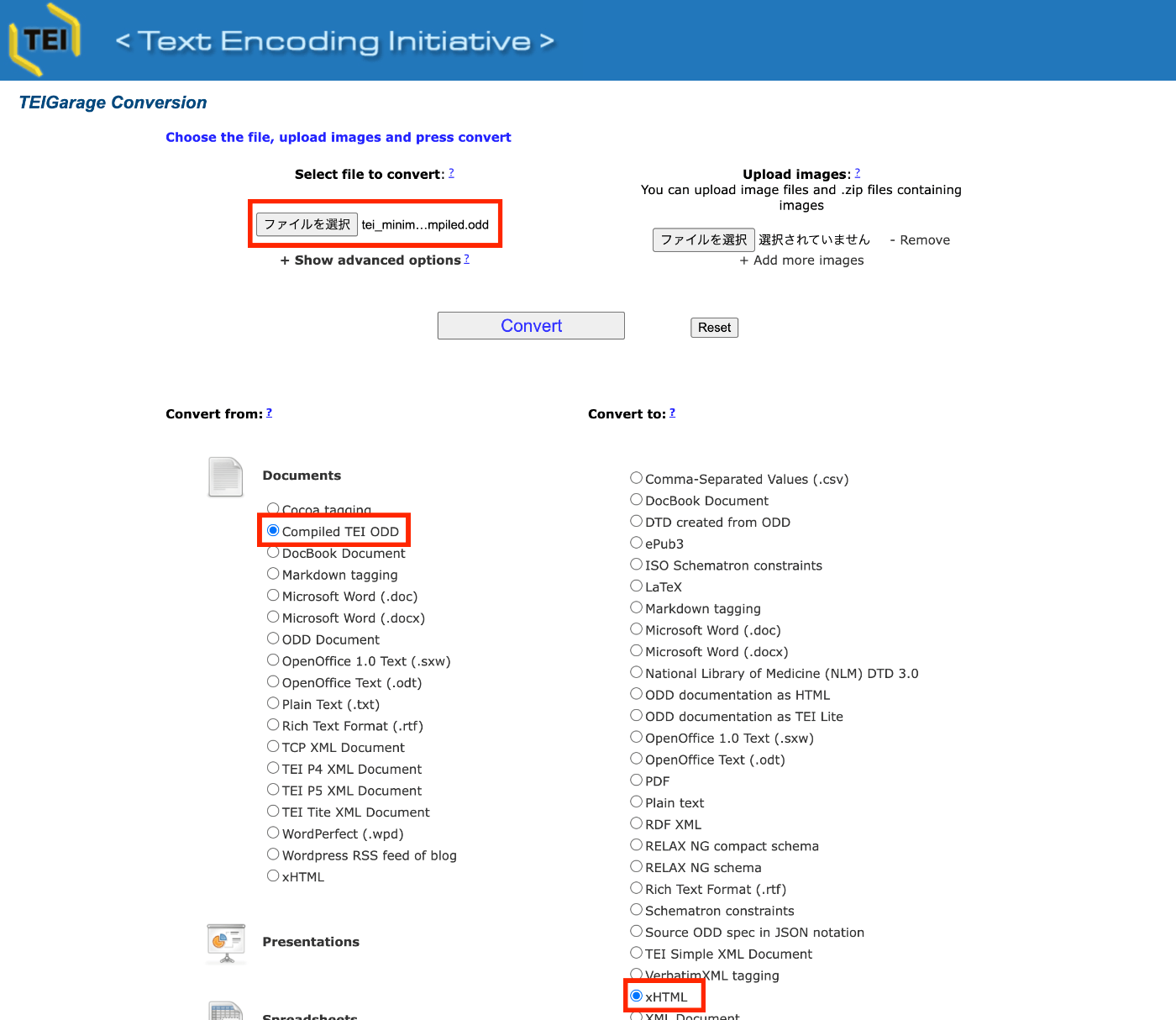
概要 TEIGarageは、以下のように説明されています。 https://github.com/TEIC/TEIGarage/ TEIGarage is a webservice and RESTful service to transform, convert and validate various formats, focussing on the TEI format. TEIGarage is based on the proven OxGarage. (機械翻訳)TEIGarageは、TEIフォーマットを中心にさまざまなフォーマットの変換、変換、検証を行うウェブサービスおよびRESTfulサービスです。TEIGarageは、実績のあるOxGarageに基づいています。 試す 以下のページで試すことができます。 https://teigarage.tei-c.org/ 以下で公開されている「TEI Minimal」のoddファイルを対象にします。このファイルは、Romaのプリセットの一つとしても使用されています。 https://tei-c.org/Vault/P5/current/xml/tei/Exemplars/tei_minimal.odd 上記のファイルをダウンロードします。 そして、TEIGarageのサイトにおいて、「Convert from」に「Compiled TEI ODD」、「Convert to」に「xHTML」を選択して、「ファイルを選択」にダウンロードしたoddファイルをアップロードします。 ダウンロードされたHTMLファイルはブラウザ等で確認することができます。 ちなみに、「Show advanced options」をクリックすると、パラメータのほか、変換に使用するURLが表示されます。 URLはエンコードされているため、デコードすると、以下になります。 https://teigarage.tei-c.org/ege-webservice/Conversions/ODDC:text:xml/TEI:text:xml/xhtml:application:xhtml+xml/conversion?properties=truetrueenfalsedefaulttruetrueenfalsedefault propertiesパラメータの中に、以下のxml記述を確認することができます。 <conversions> <conversion index="0"> <property id="oxgarage.getImages">true</property> <property id="oxgarage.getOnlineImages">true</property> <property id="oxgarage.lang">en</property> <property id="oxgarage.textOnly">false</property> <property id="pl.psnc.dl.ege.tei.profileNames">default</property> </conversion> <conversion index="1"> <property id="oxgarage.getImages">true</property> <property id="oxgarage.getOnlineImages">true</property> <property id="oxgarage.lang">en</property> <property id="oxgarage.textOnly">false</property> <property id="pl.psnc.dl.ege.tei.profileNames">default</property> </conversion> </conversions> Open API 以下にアクセスすると、Open APIに基づき、利用可能なオプション等を確認することができます。 ...