TEI/XMLから検索システムを構築する際のDTS(Distributed Text Services)のdts:wrapperの応用例
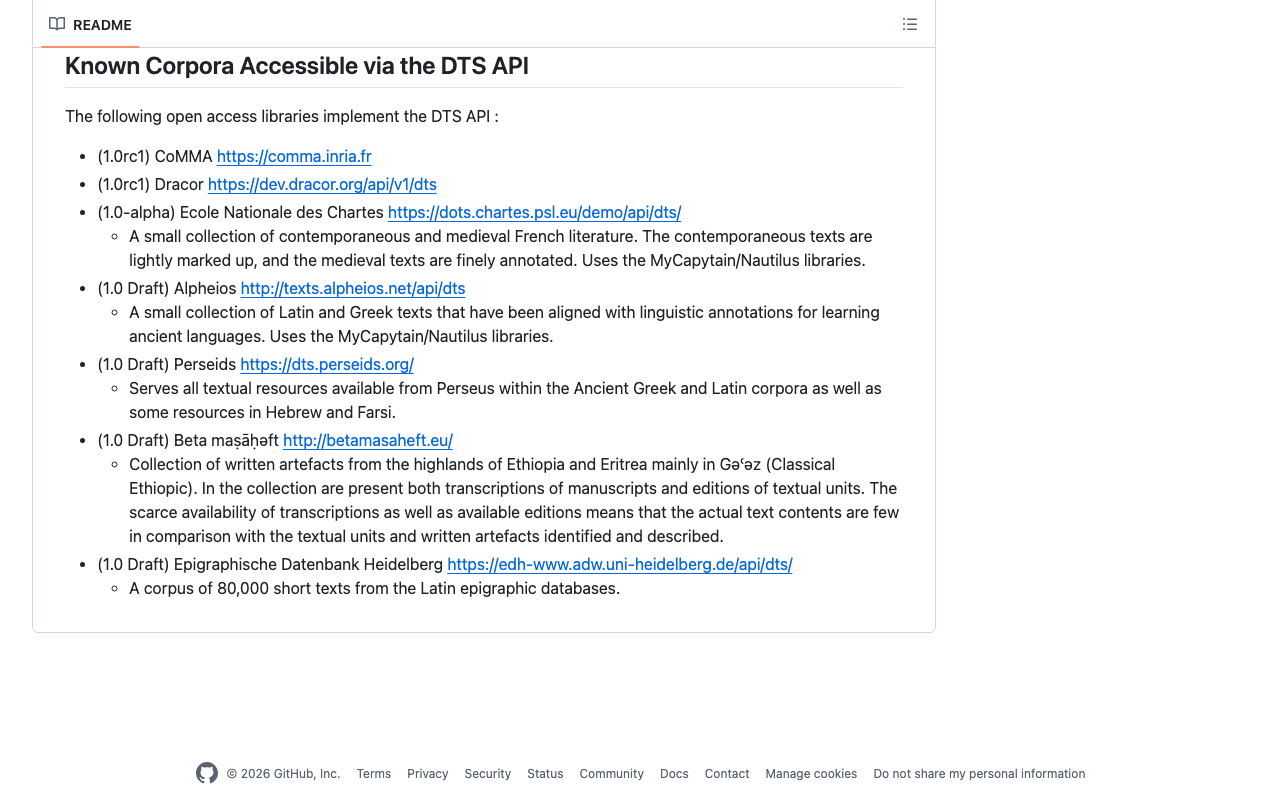
概要 TEI/XMLから検索システムを構築する際のDTS(Distributed Text Services)のdts:wrapperタグの応用例に関するメモです。 DTS(Distributed Text Services)は以下です。 Cayless, H., Clérice, T., Jonathan, R., Scott, I., & Almas, B. Distributed Text Services Specifications (Version 1-alpha) [Computer software]. https://github.com/distributed-text-services/specifications` 参考 DTSの構築例として、以下なども参考になりましたら幸いです。 例 以下の「デジタル延喜式」を例とします。 https://khirin-t.rekihaku.ac.jp/engishiki/ 本システムでは、TEIを用いて作成したXMLデータから、検索時の単位となる部分を抽出し、それをJSON形式のデータに変換した上で検索を行っています。JSONデータの例は以下です。JSON:APIに準拠した記述を採用しています。 http://khirin-t.rekihaku.ac.jp/engishiki/jsonapi/item/39100101.json { "jsonapi": { "version": "1.0", "meta": { "links": { "self": { "href": "http://jsonapi.org/format/1.0/" } } } }, "data": { "type": "item", "id": "39100101", "attributes": { "label": "正親 1 諸王年満条 項1", "jyo": [ "39-1-001 諸王年満" ], "shiki": [ "39-1 正親" ], "vol": [ "39" ], "updated": "2025-03-15", "category": [ "式" ], "manifest": "https://khirin-a.rekihaku.ac.jp/iiif/rekihaku/H-743-74-39/manifest.json", "member": "https://khirin-a.rekihaku.ac.jp/iiif/2/engishiki%2FH-743-74-39/page5069", "thumbnail": "https://khirin-a.rekihaku.ac.jp/iiif/2/engishiki%2FH-743-74-39%2F00002.tif/full/200,/0/default.jpg", "xml": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<TEI xmlns=\"http://www.tei-c.org/ns/1.0\">\n <dts:wrapper xmlns:dts=\"https://w3id.org/api/dts#\">\n <div type=\"original\"><p ana=\"項\" corresp=\"#page5069\" xml:id=\"o-item39100101\">\n 凡諸王年満十二、毎年十二月、\n<orgName sameAs=\"#京職\">京職</orgName>\n移\n<orgName sameAs=\"#宮内省\">宮内省</orgName>\n、\n<orgName sameAs=\"#宮内省\">省</orgName>\n以\n<orgName sameAs=\"#京職\">京職</orgName>\n移、即付\n<orgName sameAs=\"#正親司\">司</orgName>\n令勘会名簿、訖更送\n<orgName sameAs=\"#宮内省\">省</orgName>\n、明年正月待\n<orgName sameAs=\"#太政官\">官</orgName>\n符到、始預賜時服之例、</p></div><div type=\"japanese\"><note type=\"summary\">\n 衣替え手当ての受給年齢に達する皇族への支給開始手続きに関する規定\n </note><p ana=\"項\" corresp=\"engishiki_v39.xml#item39100101 engishiki_v39_en.xml#item39100101\" xml:id=\"ja-item39100101\">\n 皇族の年齢が数えで十二歳に達したら、十二月に\n<ruby>\n<rb>\n 京職\n </rb>\n<rt place=\"right\">\n きょうしき\n </rt>\n</ruby>\n が\n<ruby>\n<rb>\n 宮内省\n </rb>\n<rt place=\"right\">\n くないしょう\n </rt>\n</ruby>\n に通知し、宮内省は京職の通知書類を\n<ruby>\n<rb>\n 正親司\n </rb>\n<rt place=\"right\">\n せいしんし\n </rt>\n</ruby>\n に下して正親司が保管する皇族の台帳と照合させよ。正親司はこの作業が終わったら通知書類を宮内省に送れ。翌年正月に\n<ruby>\n<rb>\n 太政官\n </rb>\n<rt>\n だいじょうかん\n </rt>\n</ruby>\n の通達を受領してから、衣替え手当ての支給を開始せよ。\n</p></div><div type=\"english\"><note type=\"summary\">\n Age of Royal Recipients for Seasonal Clothing\n </note><p ana=\"項\" corresp=\"engishiki_v39.xml#item39100101 engishiki_v39_ja.xml#item39100101\" xml:id=\"en-item39100101\">\n Every year if\n<seg xml:id=\"footnote3910010101\">\n a\n prince or princess\n </seg>\n reaches\n<seg xml:id=\"footnote3910010102\">\n twelve years old\n </seg>\n , the Capital Office should report that\n information via\n<seg xml:id=\"footnote3910010103\">\n a parallel memorandum\n (\n<seg rend=\"italic\">\n i\n </seg>\n )\n</seg>\n to the Ministry of the Royal\n Household in the twelfth month. Then the Ministry should send the\n memorandum to the Royal Family Register Office to check the list against\n their existing roster. After finishing all of these procedures, the\n Royal Family Register Office should return the memorandum to the\n Ministry. The prince or princess in question will receive seasonal\n clothing after the Council of State's order is issued in the following\n New Year.\n</p></div>\n </dts:wrapper>\n</TEI>" } } } 検索結果は以下のように表示されます。校訂文(@type=“original”)、現代語訳(@type=“japanese”)、および英訳(@type=“english”)を表示しています。 ...