TEI ODDファイルのカスタマイゼーション:NDL古典籍OCRの事例
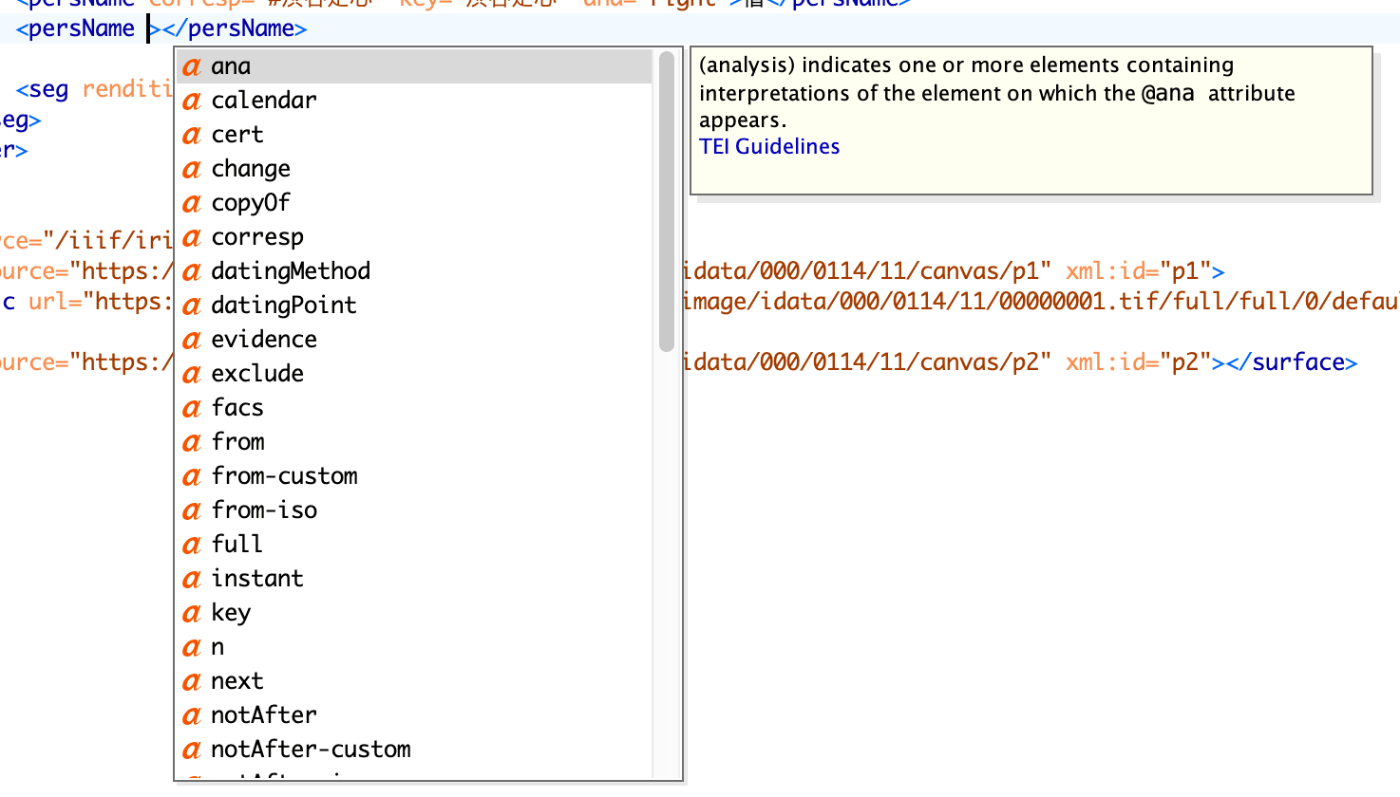
はじめに TEI (Text Encoding Initiative) は、人文学研究におけるテキストのデジタル化と共有のための国際標準です。本記事では、NDL古典籍OCR-Liteアプリケーションの出力形式に合わせてTEI ODDファイルをカスタマイズした過程を紹介します。 ODD (One Document Does it all) は、TEIスキーマをカスタマイズするための仕組みで、必要な要素と属性だけを含む独自のスキーマを定義できます。 背景:NDL古典籍OCR-Liteアプリケーションの開発 NDL古典籍OCR-Liteの出力結果をTEI/XMLで出力するアプリケーションを作成しています。このアプリケーションは、日本の古典籍をOCR処理し、その結果を標準的なTEI形式で出力することを目的としています。 出力されるTEI XMLには以下の情報を含めることにしました: テキスト情報 : OCRで認識した文字列 レイアウト情報 : 各行の座標情報(バウンディングボックス) 画像参照 : IIIF (International Image Interoperability Framework) 対応の画像URL メタデータ : 文書タイトル、処理情報など このアプリケーションで使用するスキーマをODDで記述してみました。以下、そのカスタマイゼーション過程を紹介します。 カスタマイゼーションのアプローチ 1. 初期アプローチ:標準モジュールの利用 最初は、TEIの標準モジュールを利用してODDを作成しました: schemaSpec ident="ndl_koten_ocr" start="TEI" prefix="tei_"> moduleRef key="tei"/> moduleRef key="header" include="teiHeader fileDesc titleStmt publicationStmt sourceDesc"/> moduleRef key="core" include="p title name resp respStmt lb pb graphic"/> moduleRef key="textstructure" include="TEI text body"/> moduleRef key="transcr" include="facsimile surface zone"/> schemaSpec> include属性の重要性 moduleRef要素のinclude属性は、モジュールから特定の要素のみを選択的に含める重要な機能です: ...