Snorql for Japan Searchのカスタマイズ方法の調査
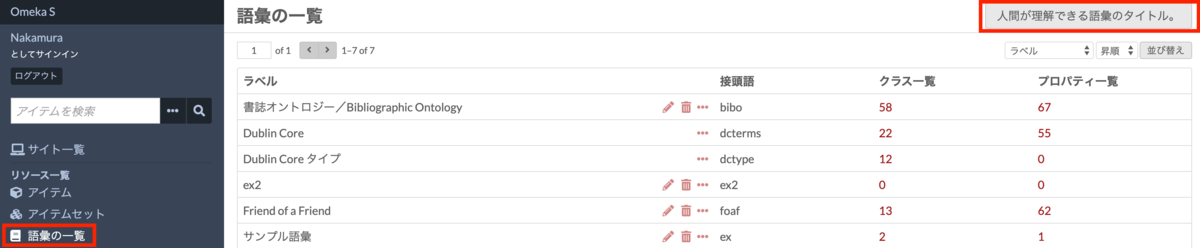
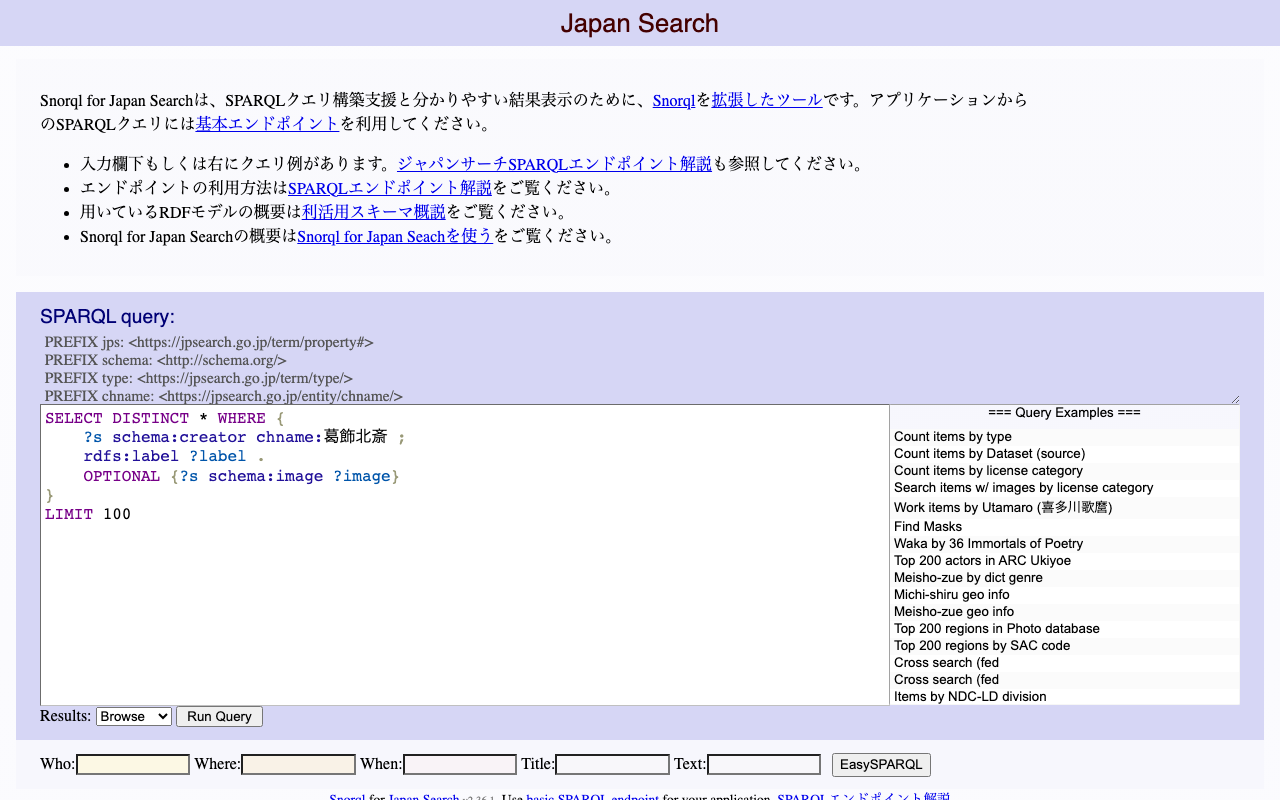
概要 ジャパンサーチで使用されている「Snorql for Japan Search」のカスタマイズ方法について、その調査結果です。随時更新予定です。また誤りも含まれている可能性が高いので、ご注意ください。 メニュー ページのタイトルを変更する snorql_def.js _poweredByLabel: "Cultural Japan", // "Japan Search", 問い合わせ先のエンドポイントを変更する snorql_def.js _endpoint: "https://ld.cultural.jp/sparql/", //"https://jpsearch.go.jp/rdf/sparql/", poweredByLinkのURLを変更する snorql_def.js _poweredByLink: "https://cultural.jp/", // "https://jpsearch.go.jp/", その他のフッター部分を編集する index.html footer> a href="./">Snorqla> for a id="poweredby" href="#">Japan Searcha>. Use a href="https://ld.cultural.jp/sparql">basic SPARQL endpointa> basic SPARQL endpoint --> for your application. >SPARQLエンドポイント解説 > --> footer> バージョンを変更する snorql_def.js var _sldb_version = "v0.0.1"; //"v2.20.1"; トップページの説明 ...



![[備忘録]Virtuosoの使い方](https://storage.googleapis.com/zenn-user-upload/a3b1702b65fc-20220819.png)
![[RDF] URIにアクセスしたらSnorqlの画面にリダイレクトさせる設定](/images/articles/3243962c5e57d0.png)