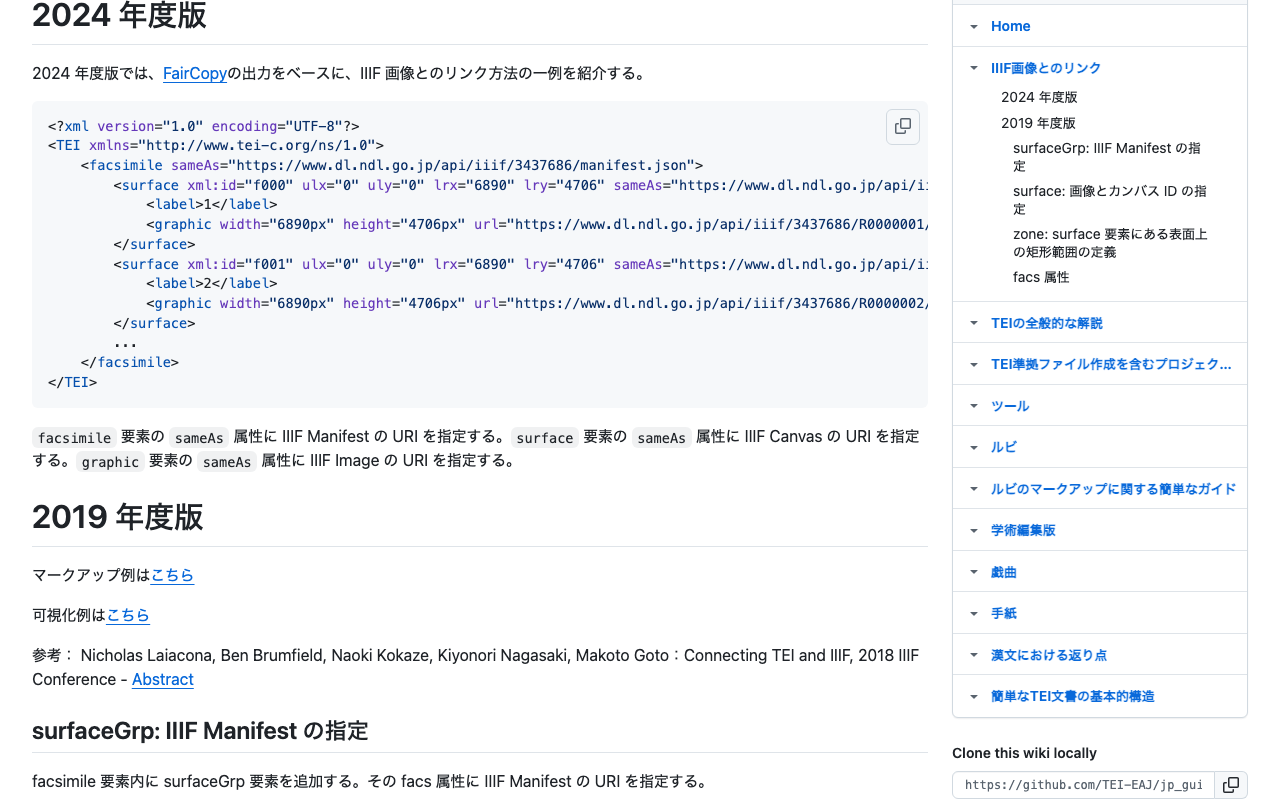
ODD編集Tips:その1
要素の属性を特定のものだけに制限する TEIのデフォルトでは、要素は多くの属性クラス(att.global、att.datableなど)を継承しており、多数の属性が使用可能です。特定の属性のみを許可したい場合は、以下のように設定します。 例: persNameでxml:idとcorrespのみを許可 <elementSpec ident="persName" mode="change"> <classes mode="change"> <!-- 属性クラスを削除(モデルクラスは維持) --> <memberOf key="att.global" mode="delete"/> <memberOf key="att.cmc" mode="delete"/> <memberOf key="att.datable" mode="delete"/> <memberOf key="att.editLike" mode="delete"/> <memberOf key="att.personal" mode="delete"/> <memberOf key="att.typed" mode="delete"/> </classes> <attList> <attDef ident="xml:id" mode="add" usage="opt"> <desc>要素の一意な識別子</desc> <datatype> <dataRef name="ID"/> </datatype> </attDef> <attDef ident="corresp" mode="add" usage="opt"> <desc>関連する人物情報へのリンク</desc> <datatype> <dataRef key="teidata.pointer"/> </datatype> </attDef> </attList> </elementSpec> ポイント <classes mode="change">を使用: mode="replace"で空にすると、モデルクラスも削除され要素自体が使えなくなる 属性クラスを個別に削除 : <memberOf key="att.xxx" mode="delete"/>で不要な属性クラスを削除 必要な属性を追加 : <attDef ident="xxx" mode="add">で許可したい属性を定義 注意点 要素がどの属性クラスに属しているかは、TEI Guidelinesで確認できる att.globalを削除するとxml:id、xml:langなども使えなくなるため、必要に応じて個別に追加する 要素に属性を追加する 既存の属性クラスを維持したまま、新しい属性を追加する場合: <elementSpec ident="pb" mode="change"> <attList> <attDef ident="facs" mode="add" usage="opt"> <desc>原本画像へのリンク</desc> <datatype> <dataRef key="teidata.pointer"/> </datatype> </attDef> </attList> </elementSpec> この場合、既存の属性クラスはそのまま維持され、facs属性が追加されます。