LoRAによる書名からのNDC(日本十進分類法)自動分類の試み
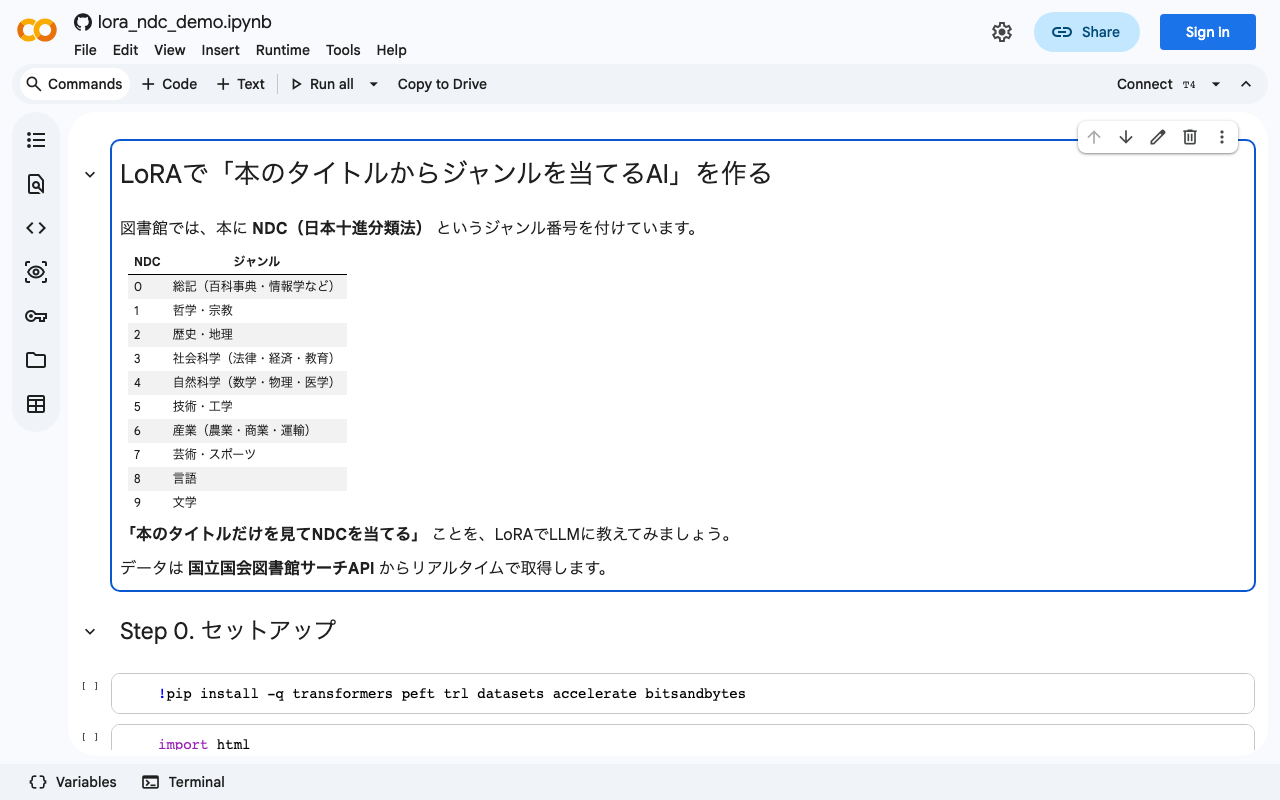
ノートブック: Google Colab で開く / GitHub TL;DR 国立国会図書館サーチAPI(SRU)を用いて617件の書誌データを収集 llm-jp-3-1.8b に LoRA(全パラメータの0.67%)を適用し、書名からNDC第1次区分への分類を学習 学習前 22.0% → 学習後 78.0%(+56ポイント) LoRAはドメイン知識の注入ではなく、タスク遂行のための振る舞いを獲得させる手法 NDC(日本十進分類法)とは 日本の図書館で広く使われている書籍の分類体系です。すべての本に0〜9の第1次区分(類目)が割り当てられます。 NDC ジャンル 0 総記(百科事典・情報学など) 1 哲学・宗教 2 歴史・地理 3 社会科学(法律・経済・教育) 4 自然科学(数学・物理・医学) 5 技術・工学 6 産業(農業・商業・運輸) 7 芸術・スポーツ 8 言語 9 文学 図書館において資料の整理(目録作成)時にNDCコードを付与する作業は、主題分析の専門的知識を要する業務です。書名のみから大まかな分類を自動推定できるモデルがあれば、分類作業の初期スクリーニングとして有用です。 LoRAとは何か LoRA(Low-Rank Adaptation)は、大規模言語モデルを効率的にファインチューニングするための手法です。 通常のファインチューニングではモデルの全パラメータ(18億個など)を更新しますが、LoRAでは元のモデルを凍結し、Attention層に小さな「アダプター」行列を挿入してそこだけを学習させます。 モデル本体 (18億パラメータ) → 凍結(更新対象外) ↓ LoRAアダプター (数百万パラメータ) → 学習対象 今回の設定では全パラメータの約0.67%(12,582,912 / 1,880,197,120)だけを学習対象にしています。これにより、GPUメモリの消費を抑えつつ、タスク特化の性能を得ることができます。 Step 1. 国立国会図書館サーチAPIからデータ取得 国立国会図書館サーチのSRU APIは誰でも無料で利用可能です。各NDCカテゴリから最大80件ずつ取得し、タイトル文字数(3〜80文字)によるフィルタリング後に合計617件の書誌データを収集しました。カテゴリごとの取得件数は以下の通りで、均等ではありません。 NDC カテゴリ 取得件数 0 総記 65件 1 哲学 67件 2 歴史 73件 3 社会科学 59件 4 自然科学 52件 5 技術・工学 63件 6 産業 65件 7 芸術・スポーツ 57件 8 言語 67件 9 文学 49件 なお、APIの特性上、取得される書誌には書名が極めて短いものや内容が判別しにくいものも含まれるため、学習データの品質には一定のノイズが存在します。 ...
