GakuNin RDM(OSF)のAPIで、フィルタを使う
概要 GakuNin RDM(OSF)のAPIで、フィルタを使う方法の備忘録です。
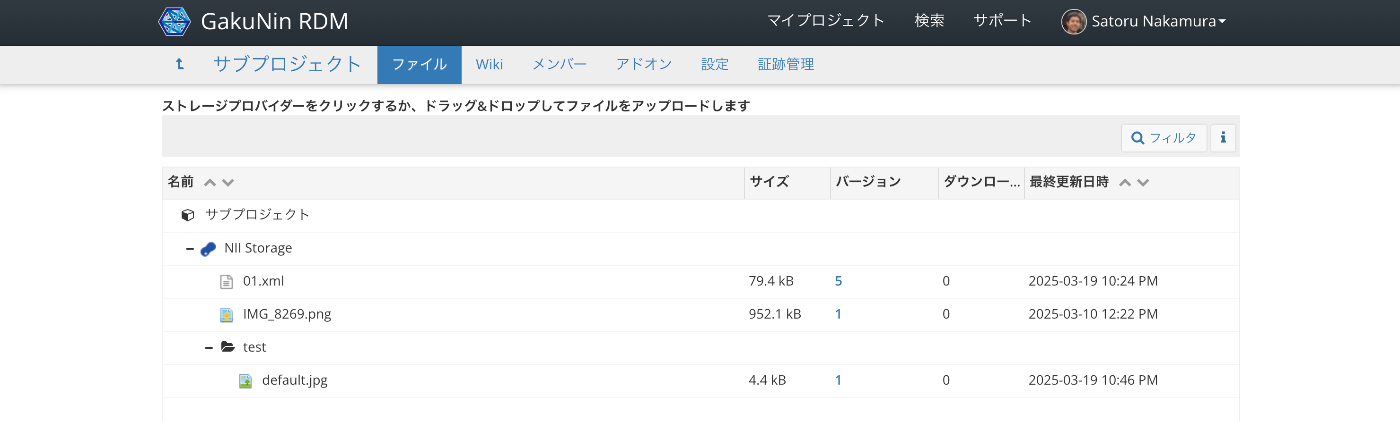
対象データ 以下のようなファイル構造を持つ「NII Storage」を対象にします。
APIでは、以下のようなURLでアクセスできるものを対象にします。
https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/files/osfstorage/
JSONデータの例は以下です。
{ "data": [ { "id": "67ce5b0b2fe4740010f753c0", "type": "files", "attributes": { "guid": "ungd3", "checkout": null, "name": "IMG_8269.png", "kind": "file", "path": "/67ce5b0b2fe4740010f753c0", "size": 952107, "provider": "osfstorage", "materialized_path": "/IMG_8269.png", "last_touched": null, "date_modified": "2025-03-10T03:22:51.750550Z", "date_created": "2025-03-10T03:22:51.750550Z", "extra": { "hashes": { "md5": "e57192b30103a7e995597ceaea39cbbf", "sha256": "5e282187067a53aaab0f1f00daaefb9519d60b064831403e671662cfbcf6f41f" }, "downloads": 0 }, "tags": [], "current_user_can_comment": true, "current_version": 1 }, "relationships": { "parent_folder": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/files/674034a483bdc200108b8a95/?format=json", "meta": {} } }, "data": { "id": "674034a483bdc200108b8a95", "type": "files" } }, "versions": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/files/67ce5b0b2fe4740010f753c0/versions/?format=json", "meta": {} } } }, "comments": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/comments/?format=json&filter%5Btarget%5D=ungd3", "meta": {} } } }, "metadata_records": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/files/67ce5b0b2fe4740010f753c0/metadata_records/?format=json", "meta": {} } } }, "node": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/?format=json", "meta": {} } }, "data": { "id": "wzv9g", "type": "nodes" } }, "target": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/", "meta": { "type": "node" } } }, "data": { "type": "node", "id": "wzv9g" } } }, "links": { "info": "https://api.rdm.nii.ac.jp/v2/files/67ce5b0b2fe4740010f753c0/", "move": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67ce5b0b2fe4740010f753c0", "upload": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67ce5b0b2fe4740010f753c0", "delete": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67ce5b0b2fe4740010f753c0", "download": "https://rdm.nii.ac.jp/download/ungd3/", "render": "https://mfr.rdm.nii.ac.jp/render?url=https://rdm.nii.ac.jp/download/ungd3/?direct%26mode=render", "html": "https://rdm.nii.ac.jp/wzv9g/files/osfstorage/67ce5b0b2fe4740010f753c0", "self": "https://api.rdm.nii.ac.jp/v2/files/67ce5b0b2fe4740010f753c0/" } }, { "id": "67da847416000900109e0454", "type": "files", "attributes": { "guid": "b45mp", "checkout": null, "name": "01.xml", "kind": "file", "path": "/67da847416000900109e0454", "size": 79397, "provider": "osfstorage", "materialized_path": "/01.xml", "last_touched": null, "date_modified": "2025-03-19T13:24:27.868078Z", "date_created": "2025-03-19T08:46:44.636107Z", "extra": { "hashes": { "md5": "a3824b2f49471842d1046a2abe623284", "sha256": "83d18a6e52a52597ebac6fa1eb8a137ed6e1e64b9c0e2c1a0b49cf746a777d0a" }, "downloads": 0 }, "tags": [], "current_user_can_comment": true, "current_version": 5 }, "relationships": { "parent_folder": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/files/674034a483bdc200108b8a95/?format=json", "meta": {} } }, "data": { "id": "674034a483bdc200108b8a95", "type": "files" } }, "versions": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/files/67da847416000900109e0454/versions/?format=json", "meta": {} } } }, "comments": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/comments/?format=json&filter%5Btarget%5D=b45mp", "meta": {} } } }, "metadata_records": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/files/67da847416000900109e0454/metadata_records/?format=json", "meta": {} } } }, "node": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/?format=json", "meta": {} } }, "data": { "id": "wzv9g", "type": "nodes" } }, "target": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/", "meta": { "type": "node" } } }, "data": { "type": "node", "id": "wzv9g" } } }, "links": { "info": "https://api.rdm.nii.ac.jp/v2/files/67da847416000900109e0454/", "move": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67da847416000900109e0454", "upload": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67da847416000900109e0454", "delete": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67da847416000900109e0454", "download": "https://rdm.nii.ac.jp/download/b45mp/", "render": "https://mfr.rdm.nii.ac.jp/render?url=https://rdm.nii.ac.jp/download/b45mp/?direct%26mode=render", "html": "https://rdm.nii.ac.jp/wzv9g/files/osfstorage/67da847416000900109e0454", "self": "https://api.rdm.nii.ac.jp/v2/files/67da847416000900109e0454/" } }, { "id": "67daca9916000900109e1d98", "type": "files", "attributes": { "guid": null, "checkout": null, "name": "test", "kind": "folder", "path": "/67daca9916000900109e1d98/", "size": null, "provider": "osfstorage", "materialized_path": "/test/", "last_touched": null, "date_modified": null, "date_created": null, "extra": { "hashes": { "md5": null, "sha256": null } }, "tags": [], "current_user_can_comment": true, "current_version": 1 }, "relationships": { "parent_folder": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/files/674034a483bdc200108b8a95/?format=json", "meta": {} } }, "data": { "id": "674034a483bdc200108b8a95", "type": "files" } }, "files": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/files/osfstorage/67daca9916000900109e1d98/?format=json", "meta": {} } } }, "node": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/?format=json", "meta": {} } }, "data": { "id": "wzv9g", "type": "nodes" } }, "target": { "links": { "related": { "href": "https://api.rdm.nii.ac.jp/v2/nodes/wzv9g/", "meta": { "type": "node" } } }, "data": { "type": "node", "id": "wzv9g" } } }, "links": { "info": "https://api.rdm.nii.ac.jp/v2/files/67daca9916000900109e1d98/", "move": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67daca9916000900109e1d98/", "upload": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67daca9916000900109e1d98/", "delete": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67daca9916000900109e1d98/", "new_folder": "https://files.rdm.nii.ac.jp/v1/resources/wzv9g/providers/osfstorage/67daca9916000900109e1d98/?kind=folder", "self": "https://api.rdm.nii.ac.jp/v2/files/67daca9916000900109e1d98/" } } ], "links": { "first": null, "last": null, "prev": null, "next": null, "meta": { "total": 3, "per_page": 10 } } } 検索例 JSON:APIに準拠しているので、filterパラメータを使用します。
...
2025年3月19日 · 更新: 2025年3月19日 · 4 分 · Nakamura