本記事は生成AIと共同で執筆しています。事実関係は可能な範囲で公式ドキュメント等と照合していますが、誤りが含まれている可能性があります。重要な判断を行う前にご自身でも一次情報をご確認ください。
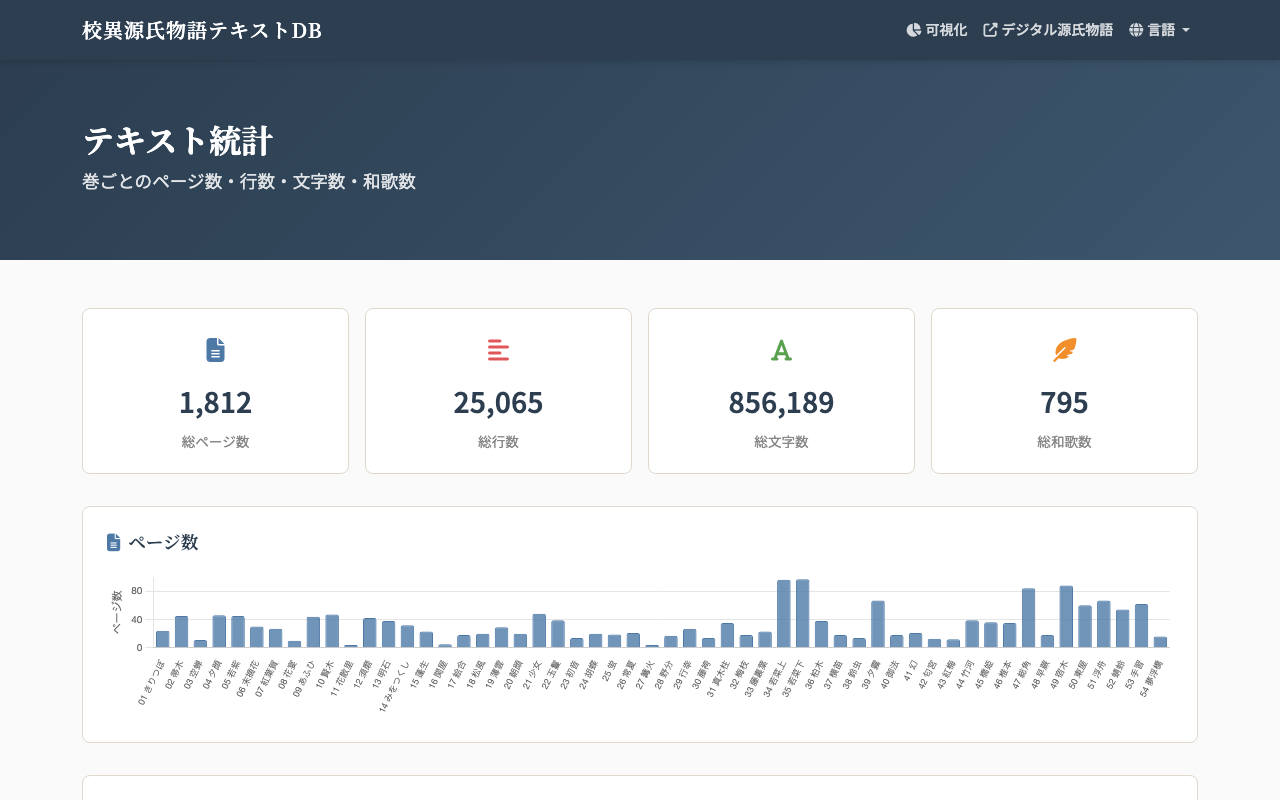
『校異源氏物語』テキストDB は、国立国会図書館デジタルコレクションで保護期間満了として公開されている池田亀鑑編『校異源氏物語』を翻刻し、そのテキストデータを TEI/XML で公開しているデータベースです。このサイトには 統計ページ があり、巻ごとのページ数・行数・文字数・和歌数を可視化しています。
本記事では、TEI/XML で構造化された翻刻テキストから、こうした統計ページを GitHub Actions で自動生成・自動公開している仕組みを記録します。
統計ページで見えるもの
https://kouigenjimonogatari.github.io/stats.html では、以下の情報を確認できます。
- 4つの集計カード:総ページ数・総行数・総文字数・総和歌数
- 巻ごとのページ数・行数・文字数・和歌数の棒グラフ(Chart.js)
執筆時点では54巻すべてが公開済みで、総文字数は856,189字、総ページ数は1,812頁となっています。巻ごとの分量の偏り(例:若菜上下が突出して長く、特に若菜下が最も長いこと)も視覚的に把握できます。
TEI/XMLで翻刻テキストを構造化する
TEI(Text Encoding Initiative)は、人文学資料の電子テキストを構造化するための国際標準ガイドラインです。プレーンテキストでは「どこからどこまでが本文の1ページか」「どの行が和歌か」を機械的に判定するのが難しいですが、TEI に準拠した XML タグで意味を明示しておくと、後段の集計や変換が容易になります。
『校異源氏物語』テキストDB では、各巻のテキストを以下のような構造で記述しています。
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<!-- メタデータ:書誌情報、ライセンス、関与者 など -->
</teiHeader>
<facsimile>
<!-- 国立国会図書館デジタルコレクションの IIIF 画像との紐づけ -->
</facsimile>
<text>
<body>
<p>
<pb n="5" facs="..."/> <!-- ページ区切り:5ページ目 -->
<lb/>
<seg corresp="..."> <!-- 行・節の単位 -->
いつれの御時にか...
</seg>
<lb/>
<seg corresp="..."> <!-- 和歌は seg の中に lg として入れ子 -->
<lg xml:id="waka-001" type="waka" rhyme="tanka">
<l n="1">...</l>
<l n="2">...</l>
<l n="3">...</l>
<l n="4">...</l>
<l n="5">...</l>
</lg>
</seg>
</p>
</body>
</text>
</TEI>
<pb>(ページ区切り)、<seg>(行・節)、<lg type="waka">(和歌のグループ)といった要素で意味を明示しているので、「何ページか」「何行か」「和歌は何首あるか」をプログラムで機械的に数えられます。
集計スクリプト
リポジトリの scripts/prebuild.py の中に、巻ごとの統計を JSON に書き出す関数があります。
def build_chapters_json():
"""巻ごとの ページ数・行数・文字数・和歌数 を集計して chapters.json を生成"""
chapters = []
for ch in CHAPTERS: # ['01', '02', ..., '54']
src_path = os.path.join(XML_LW_DIR, f'{ch}.xml')
if not os.path.exists(src_path):
continue
with open(src_path, 'r', encoding='utf-8') as f:
content = f.read()
# <pb> 要素の数 = ページ数
pages = len(re.findall(r'<pb\s', content))
# <seg> 要素の数 = 行数、その本文文字数の合計 = 文字数
seg_texts = re.findall(r'<seg[^>]*>(.*?)</seg>', content)
lines = len(seg_texts)
chars = sum(
len(re.sub(r'<[^>]+>', '', seg).strip())
for seg in seg_texts
)
# <lg type="waka"> 要素の数 = 和歌数
waka = len(re.findall(r'<lg\s[^>]*type="waka"', content))
chapters.append({
'chapter': ch,
'chapter_name': CHAPTER_NAMES.get(ch, ch), # 例: '01' → 'きりつぼ'
'pages': pages,
'lines': lines,
'chars': chars,
'waka': waka,
})
with open('docs/data/chapters.json', 'w', encoding='utf-8') as f:
json.dump(chapters, f, ensure_ascii=False, indent=2)
正規表現で十分にカウントできるのは、TEI が「タグで意味を明示している」からです。プレーンテキストから同じ集計をしようとすると、章立ての判定や和歌の判別といったヒューリスティックに頼る箇所が増えてしまいます。
静的ページ側でのレンダリング
docs/stats.html は、生成された docs/data/chapters.json を fetch で読み込み、Chart.js で棒グラフを描画する素朴な静的ページです。
fetch('data/chapters.json')
.then(r => r.json())
.then(chapters => {
const totalPages = chapters.reduce((s, c) => s + c.pages, 0);
const totalChars = chapters.reduce((s, c) => s + c.chars, 0);
// 4つの集計カードの値を更新
document.getElementById('totalPages').textContent = totalPages.toLocaleString();
document.getElementById('totalChars').textContent = totalChars.toLocaleString();
// 棒グラフを描画
new Chart(document.getElementById('pagesChart'), {
type: 'bar',
data: {
labels: chapters.map(c => c.chapter_name),
datasets: [{ data: chapters.map(c => c.pages), label: 'ページ数' }],
},
});
// 行数・文字数・和歌数も同様に
});
このページは静的 HTML と JavaScript だけで完結するので、サーバ実装やデータベースは不要です。GitHub Pages のような静的ホスティングだけで動きます。
CI/CD:プッシュ起点で再集計・再公開
サイトは GitHub Pages で公開しており、TEI/XML を更新すると数分で公開ページが更新されます。CI/CD は GitHub Actions(.github/workflows/deploy.yml)で組んでいます。要点を抜粋すると次のようになっています。
on:
push:
branches: [master]
paths:
- 'xml/master/**'
- 'scripts/**'
- 'docs/**'
- 'data/**'
- 'requirements.txt'
- 'package.json'
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with: { python-version: '3.12' }
- run: pip install -r requirements.txt
- uses: actions/setup-java@v4
with: { distribution: 'temurin', java-version: '21' }
# Saxon-HE と xmlresolver をダウンロード(XSLT 3.0 用)
- run: |
curl -sL -o /tmp/saxon-he.jar \
https://repo1.maven.org/maven2/net/sf/saxon/Saxon-HE/12.5/Saxon-HE-12.5.jar
curl -sL -o /tmp/xmlresolver.jar \
https://repo1.maven.org/maven2/org/xmlresolver/xmlresolver/6.0.4/xmlresolver-6.0.4.jar
- name: Run prebuild
env:
SAXON_JAR: /tmp/saxon-he.jar:/tmp/xmlresolver.jar
run: python3 scripts/prebuild.py tei xsl waka stats epub
- uses: actions/upload-pages-artifact@v3
with: { path: docs }
deploy:
needs: build
runs-on: ubuntu-latest
environment:
name: github-pages
steps:
- uses: actions/deploy-pages@v4
主な処理は次の通りです。
xml/master/**・scripts/**・docs/**などが更新されたら走ります。- Python と Java をセットアップし、Saxon-HE(XSLT 3.0 プロセッサ)を配置します。
prebuild.pyで TEI 派生ファイル(表示用 TEI、HTML、和歌一覧、統計、EPUB など)を生成します。docs/を Pages のアーティファクトとしてアップロードし、actions/deploy-pagesでデプロイします。
prebuild.py の stats ステップで docs/data/chapters.json が再生成されるため、TEI/XML の翻刻を更新すると統計ページの数値も自動で追従します。手作業で数値を書き換える運用は発生しません。
TEI/XML で構造化することの利点
統計ページに限らない一般論ですが、TEI/XML で意味を明示しておくと、同じソースから複数の派生物を一気通貫で生成できます。本サイトでは現時点で次のような派生物を出力しています。
- 統計ページ(本記事のテーマ)
- 縦書き表示用の HTML(XSLT 経由)
- 和歌一覧(
<lg type="waka">を抽出して JSON 化) - EPUB(章ごと)
- PDF(XSLT で TeX に変換し、lualatex で組版)
- Linked Data(RDF)と SPARQL エンドポイント(リポジトリに同梱した SNORQL UI で閲覧)
- DTS(Distributed Text Services)API 対応のビューワ(外部サービスの
dts-typescript.vercel.appから本サイトの TEI/XML を参照)
派生物が増えれば増えるほど、初期に TEI で構造化したコストが回収されていく構造になっています。プレーンテキストで提供しただけでは、こうした派生先ごとに別々の前処理を繰り返すことになりがちです。
https://kouigenjimonogatari.github.io/stats.html のような集計ページは、テキストを TEI/XML で構造化し、ビルドステップで集計して JSON に書き出し、静的 HTML と JavaScript で JSON を読んで描画し、CI/CD でプッシュ起点に再ビルド・再公開する、という流れで成り立っています。テキストデータを構造化することで、こうした派生ページの実装コストを抑えられる点が、TEI/XML を採用する一つの実利的な理由になっています。