Google Colabを用いたNDLOCRの実行にかかる時間について
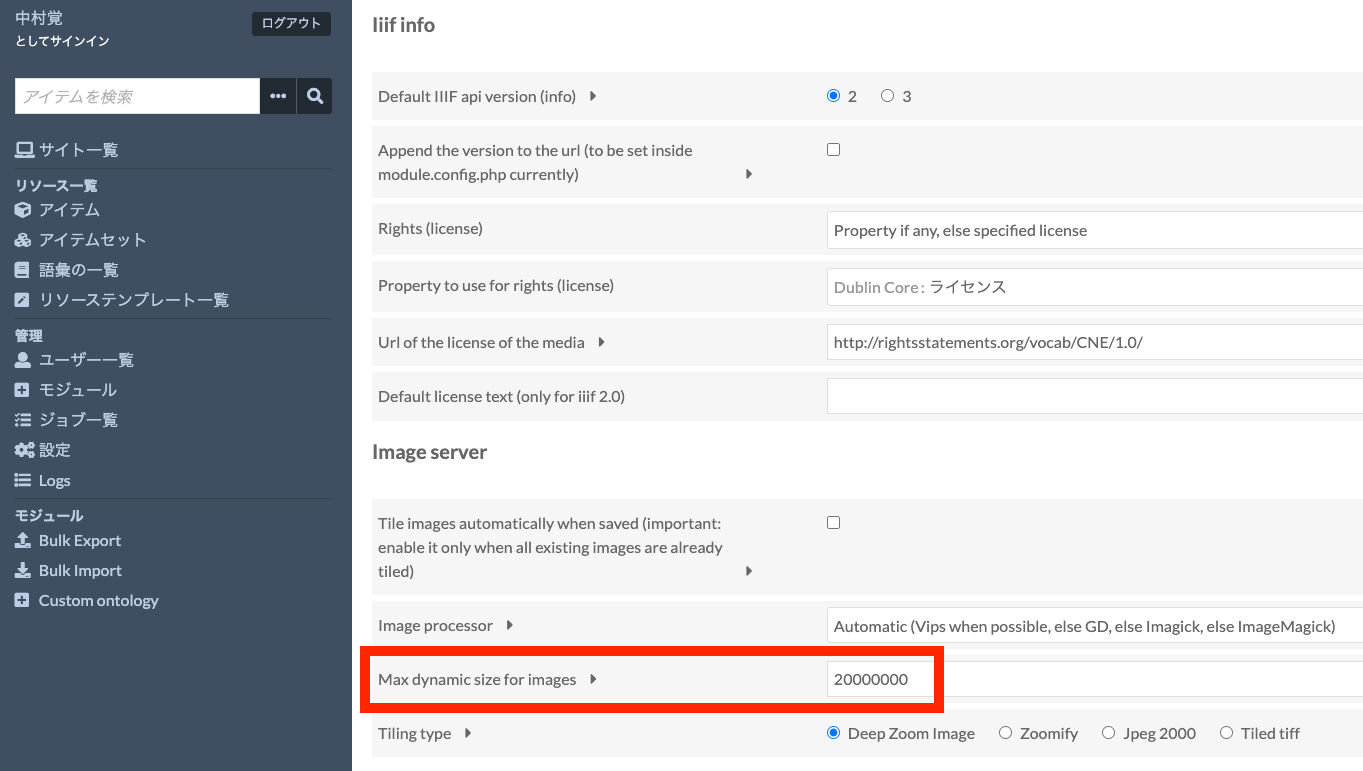
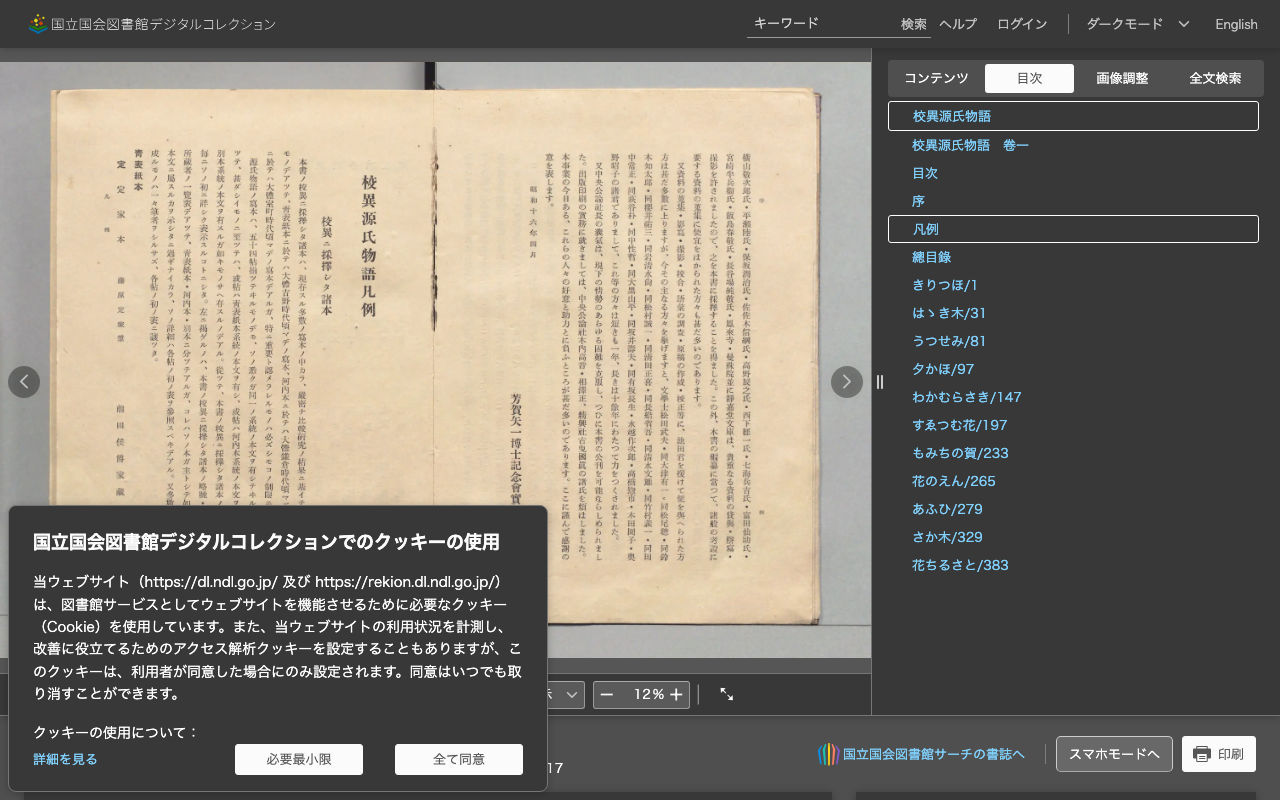
先日、以下の記事を執筆しました。 今回は、Google Colabを用いたNDLOCRの実行にかかる時間について、かんたんな調査を行なったので、その結果をまとめます。 設定 GPUは以下です。 Fri Apr 29 06:26:29 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... Off | 00000000:00:04.0 Off | 0 | | N/A 35C P0 23W / 300W | 0MiB / 16160MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ 以下の画像を用いました。サイズは5000 x 3415 px で、 1.1 MB でした。 ...