ReplayWeb.page:ブラウザで動作するWebアーカイブ再生ツール
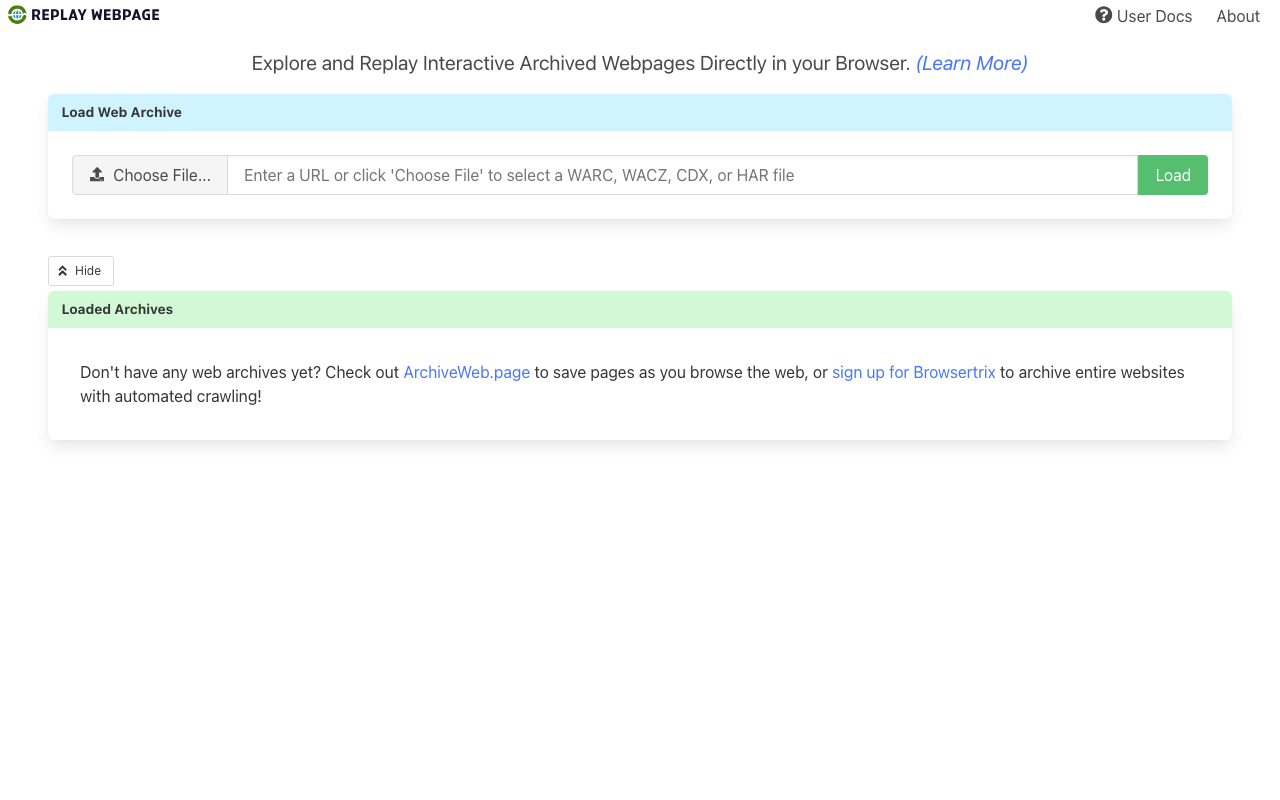
はじめに デジタルヒューマニティーズにおいて、Webコンテンツの保存と再現は重要な課題です。Webサイトは日々更新・消滅しており、研究対象としてのWebページを長期的に保存する仕組みが必要です。 ReplayWeb.page は、Webrecorderプロジェクトが開発したブラウザベースのWebアーカイブ再生ツールです。WARC(Web ARChive)やWACZ(Web Archive Collection Zipped)形式のアーカイブファイルを、ブラウザ上でそのまま閲覧できます。 ReplayWeb.pageの主な特徴 クライアントサイド処理 最大の特徴は、Service Workerを活用したクライアントサイド処理です。従来のWebアーカイブ再生ツール(Wayback Machineなど)はサーバーサイドでの処理が必要でしたが、ReplayWeb.pageではブラウザ内ですべての処理が完結します。これにより、サーバーの構築・運用が不要になります。 WARC/WACZ形式のサポート 国際標準であるWARC形式と、Webrecorderが提案するWACZ形式の両方に対応しています。WACZ形式はWARCファイルをZIP圧縮し、インデックスやメタデータを含めたパッケージ形式で、効率的なランダムアクセスが可能です。 多様なデータソースからの読み込み ローカルファイル、URL、Google Drive、Dropbox、S3など、さまざまなソースからアーカイブファイルを読み込めます。HTTPレンジリクエストに対応しているため、大きなアーカイブファイルでも全体をダウンロードせずに部分的にアクセスできます。 埋め込み対応 <replay-web-page> カスタムエレメントを使って、任意のWebページにアーカイブの再生ウィジェットを埋め込めます。研究成果の公開やデジタル展示に活用できます。 DH研究での活用例 Webサイトの長期保存 研究対象のWebサイトをWARC/WACZ形式で保存し、将来にわたって参照可能な状態を維持できます。リンク切れや改変を心配することなく、特定時点のWebコンテンツを正確に再現できます。 デジタル展示の構築 博物館や図書館のデジタル展示において、過去のWebサイトをそのまま再現する展示を構築できます。ReplayWeb.pageの埋め込み機能を使えば、展示用Webサイト内にアーカイブされたコンテンツをシームレスに組み込めます。 ソーシャルメディアの保存 ソーシャルメディア上の投稿やスレッドなど、消滅しやすいコンテンツを保存・再現するのに適しています。Webrecorderのキャプチャツール(ArchiveWeb.page)と組み合わせることで、キャプチャから再生までの一連のワークフローを構築できます。 基本的な使い方 アーカイブの準備: ArchiveWeb.pageやwget、Browsertrixなどでページをキャプチャし、WARC/WACZファイルを作成します ReplayWeb.pageにアクセス: replayweb.page をブラウザで開きます ファイルの読み込み: ローカルファイルを選択するか、URLを指定してアーカイブを読み込みます ブラウジング: 保存されたWebページをオリジナルと同様にブラウジングできます 関連ツール Webrecorderプロジェクトは、ReplayWeb.page以外にも以下のツールを提供しています。 ArchiveWeb.page: ブラウザ拡張機能でWebページをキャプチャ Browsertrix: 大規模なWebクローリングとアーカイブの自動化 py-wacz: PythonでWACZファイルを操作するライブラリ 技術的な仕組み ReplayWeb.pageはService Workerを使って、アーカイブされたHTTPレスポンスをインターセプトし、ブラウザに提供します。ユーザーがアーカイブ内のURLにアクセスすると、Service WorkerがWARC/WACZファイルから該当するレスポンスを取得し、元のサーバーにリクエストを送ることなく、保存されたコンテンツを返します。 この仕組みにより、JavaScriptやCSSを含む動的なWebページも、保存時の状態のまま正確に再現できます。 まとめ ReplayWeb.pageは、Webアーカイブの再生をブラウザだけで完結させる革新的なツールです。サーバー不要で動作する手軽さと、標準的なWARC/WACZ形式への対応により、DH研究におけるWebコンテンツの保存・再現・共有の課題を解決します。デジタル保存に関心のある研究者にとって、必須のツールといえるでしょう。 参考リンク ReplayWeb.page Webrecorder プロジェクト WACZ 仕様