はじめに
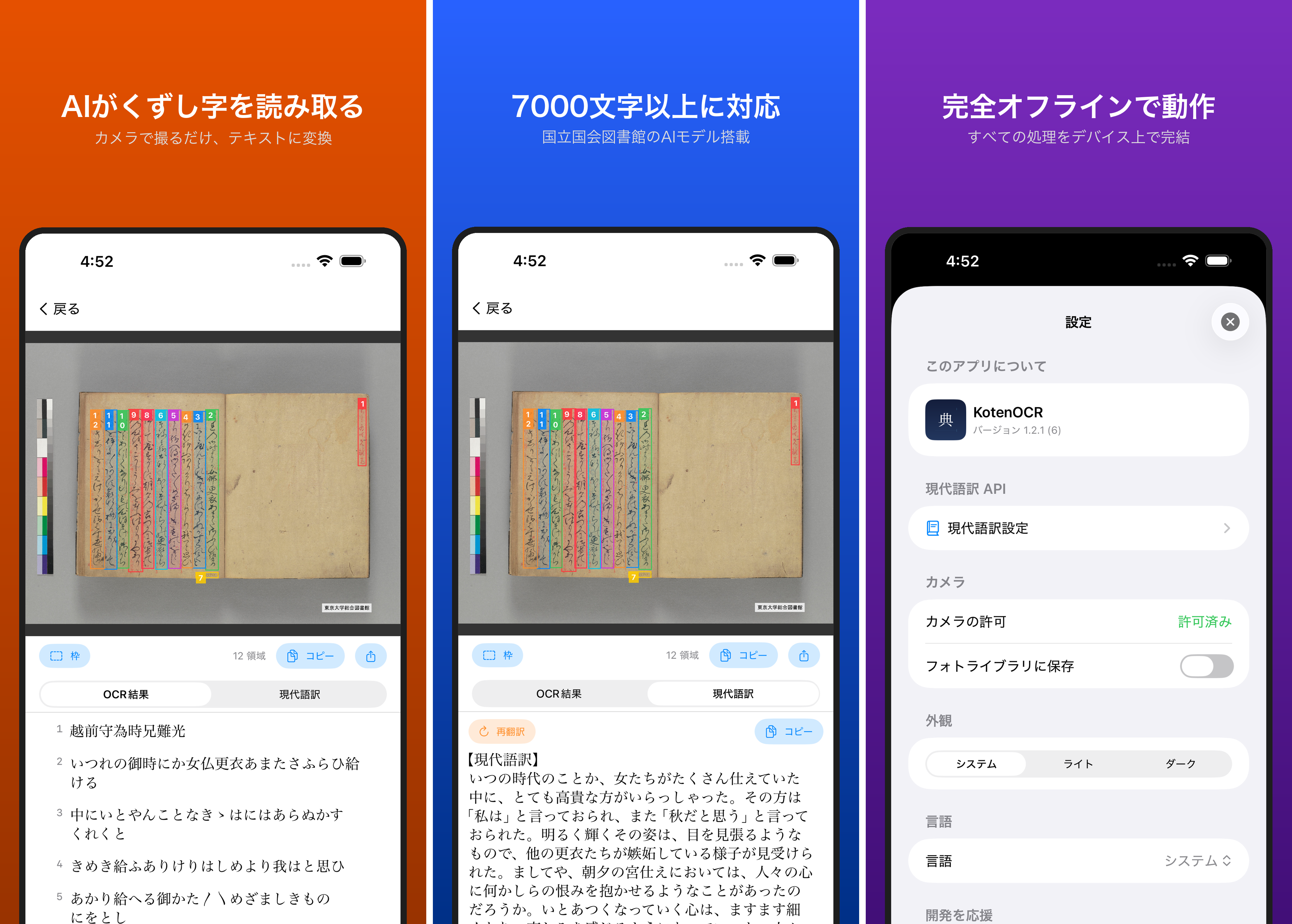
古典籍に書かれたくずし字(変体仮名・草書体の漢字)を読むのは、専門家でも容易ではありません。近年はAI-OCRによって機械的な認識が可能になってきましたが、調査した限り、スマートフォンでオフライン利用できるツールは見当たりませんでした。
KotenOCRは、国立国会図書館(NDL)が公開した軽量くずし字OCRモデル「NDL古典籍OCR-Lite」をiOS上で動作させ、写真を撮るだけでくずし字を認識できるアプリです。
App Store(無料): https://apps.apple.com/jp/app/kotenocr/id6760045646
背景:既存ツールの状況
NDLが「NDL古典籍OCR-Lite」を公開したことで、くずし字OCRの敷居は下がりました。既存ツールを見渡すと以下のような状況でした。
| ツール | 形態 | インターネット接続 |
|---|---|---|
| NDL古典籍OCR-Lite | デスクトップ / Web / CLI | 不要(デスクトップ版) |
| miwo(CODH) | モバイルアプリ | 必要 |
| 古文書カメラ(TOPPAN) | モバイルアプリ | 必要 |
モバイルアプリは存在するものの、いずれもクラウド通信が必要です。一方、NDL古典籍OCR-LiteはPC環境でしか動作しません。
そこで、NDL古典籍OCR-Liteのモデルをスマートフォンに載せて、オフラインで動くiOSアプリを作ることにしました。
KotenOCRの特徴
- 完全オフライン — すべての処理がデバイス上で完結。通信不要
- iPhone / iPad対応 — iOS 16.0以上
- 無料 — App Storeから無料でダウンロード可能
- スキャン履歴 — 認識結果を保存・管理
- TXT / PDFエクスポート — 認識テキストをファイルとして出力
- 範囲トリミング — 認識する領域を指定可能
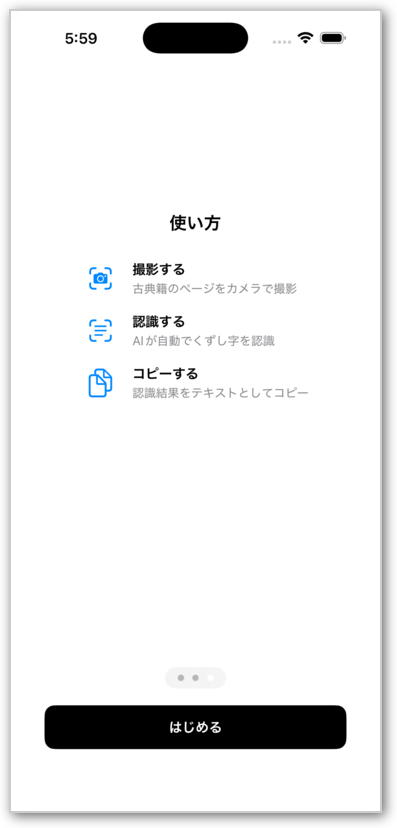
使い方
- 古典籍の写真を撮影する(またはライブラリから選択)
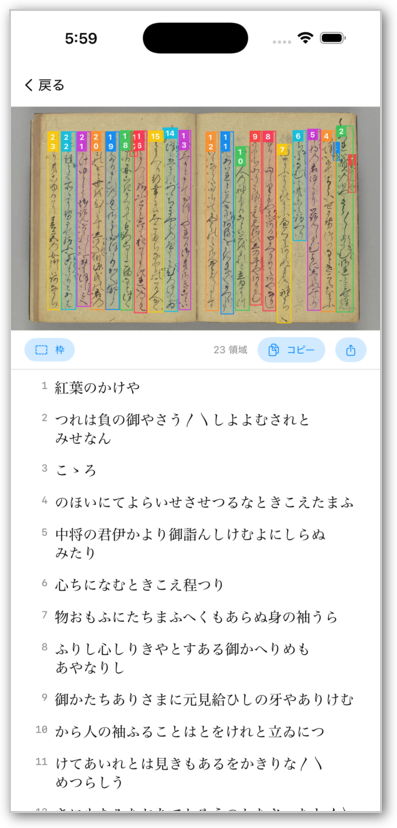
- AIがくずし字を自動認識
- 認識されたテキストをコピー・エクスポート
OCRパイプライン
写真からテキストが認識されるまでの処理フローは以下の通りです。
写真 → トリミング → テキスト領域検出 → 文字認識 → 読み順決定 → 表示
- テキスト領域検出: RTMDetモデルにより、画像内の文字領域を検出
- 文字認識: PARSeqモデルにより、検出領域内の文字を認識(7,141文字、NDLmojiの文字集合に対応)
- 読み順: 日本語の縦書き・右から左への読み順を考慮して並べ替え
技術構成
ONNX Runtimeによる推論
モデルはONNX形式で提供されており、iOSアプリではONNX Runtimeを使って直接推論を実行しています。Core MLへの変換は不要で、ONNXファイルをそのまま利用できます。
モデルの合計サイズは約80MBで、アプリにバンドルして配布しています。
現代語訳機能
認識した古文を現代日本語に翻訳する機能も備えています。
- ローカルAI(Apple Foundation Models): iOS 26以降でオフライン利用可能
- クラウドAPI(OpenAI互換): APIキー設定が必要。3段階の詳細レベルを選択可能

AI駆動の開発
本アプリの開発にはClaude CodeをはじめとするAIコーディングツールを活用しました。
App Store自動化
App Store Connect APIを用いて、審査提出プロセスを自動化しています。
今後の展望
現在、Flutter版を開発中です。これにより、Android端末でもKotenOCRが利用できるようになる予定です。
リンク
- App Store: KotenOCR
- NDL古典籍OCR-Lite(GitHub): https://github.com/ndl-lab/ndlkotenocr-lite
- デモ動画: Google Drive