概要
Azure OpenAI Assistants APIを用いたアプリをGradioとNext.jsで作成したので、備忘録です。
対象データ
Zennで公開している記事を対象にしました。まず以下により、一括ダウンロードしました。
import requests
from bs4 import BeautifulSoup
import os
from tqdm import tqdm
page = 1
urls = []
while 1:
url = f"https://zenn.dev/api/articles?username=nakamura196&page={page}"
response = requests.get(url)
data = response.json()
articles = data['articles']
if len(articles) == 0:
break
for article in articles:
urls.append("https://zenn.dev" + article['path'])
page += 1
for url in tqdm(urls):
text_opath = f"data/text/{url.split('/')[-1]}.txt"
if os.path.exists(text_opath):
continue
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
html = soup.find(class_="znc")
txt = html.get_text()
os.makedirs(os.path.dirname(text_opath), exist_ok=True)
with open(text_opath, "w") as f:
f.write(txt)
ベクトルストアへの登録
以下のようなコードにより、データファイルをアップロードします。
import os
from dotenv import load_dotenv
from openai import AzureOpenAI
from glob import glob
from tqdm import tqdm
load_dotenv(override=True)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT_ZENN"),
api_key=os.getenv("AZURE_OPENAI_API_KEY_ZENN"),
api_version="2024-05-01-preview"
)
# ベクトルストアの作成または取得
is_create_vector_store = True
vector_store_name = "Vector Store"
if is_create_vector_store:
vector_store = client.beta.vector_stores.create(name=vector_store_name) # Create a vector store caled "Financial Statements"
vector_stores = client.beta.vector_stores.list()
for vector_store in vector_stores:
if vector_store.name == vector_store_name:
vector_store_id = vector_store.id
break
# 登録済みデータファイルの取得
response = client.files.list(purpose="assistants")
items = response.data
filenames = []
for item in items:
filename = item.filename
filenames.append(filename)
filenames.sort()
# アップロード
## 定数設定
BATCH_SIZE = 100
vector_store_id = "vs_UELnIBkcROD3o4XKX2CcpVjo"
## ファイル一覧取得とソート
files = glob("./data/text/*.txt")
files.sort()
## アップロード済みファイルを確認済みと仮定
file_streams = []
for file in tqdm(files):
filename = os.path.basename(file)
if filename in filenames: # アップロード済みのファイルをスキップ
continue
## ファイルをストリームとして開く
file_streams.append(open(file, "rb"))
## バッチサイズに達したらアップロード処理
if len(file_streams) == BATCH_SIZE:
try:
client.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store_id, files=file_streams
)
except Exception as e:
print(f"Error processing batch: {e}")
finally:
file_streams = [] # ストリームリセット
## 残りのファイルを処理
if file_streams:
try:
client.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store_id, files=file_streams
)
except Exception as e:
print(f"Error processing remaining files: {e}")
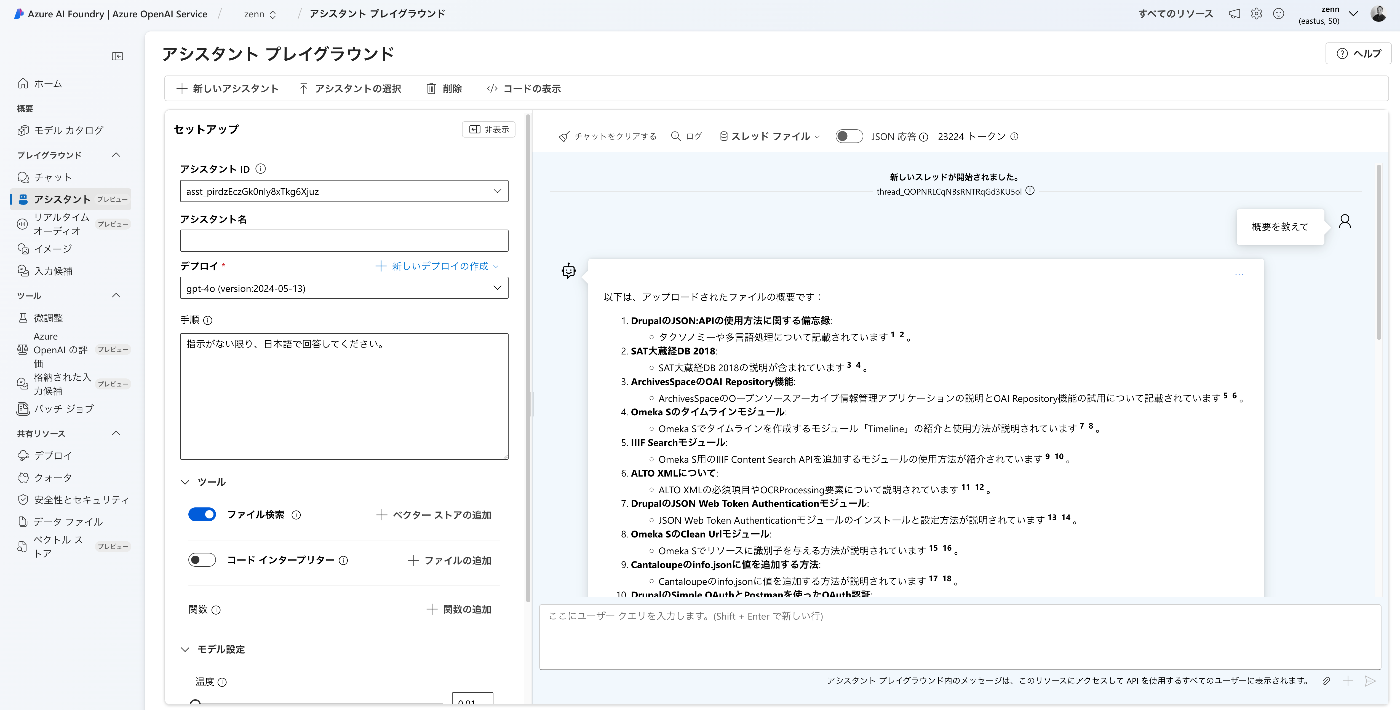
アシスタント プレイグラウンド
「アシスタント プレイグラウンド」を用いて、挙動を確認します。
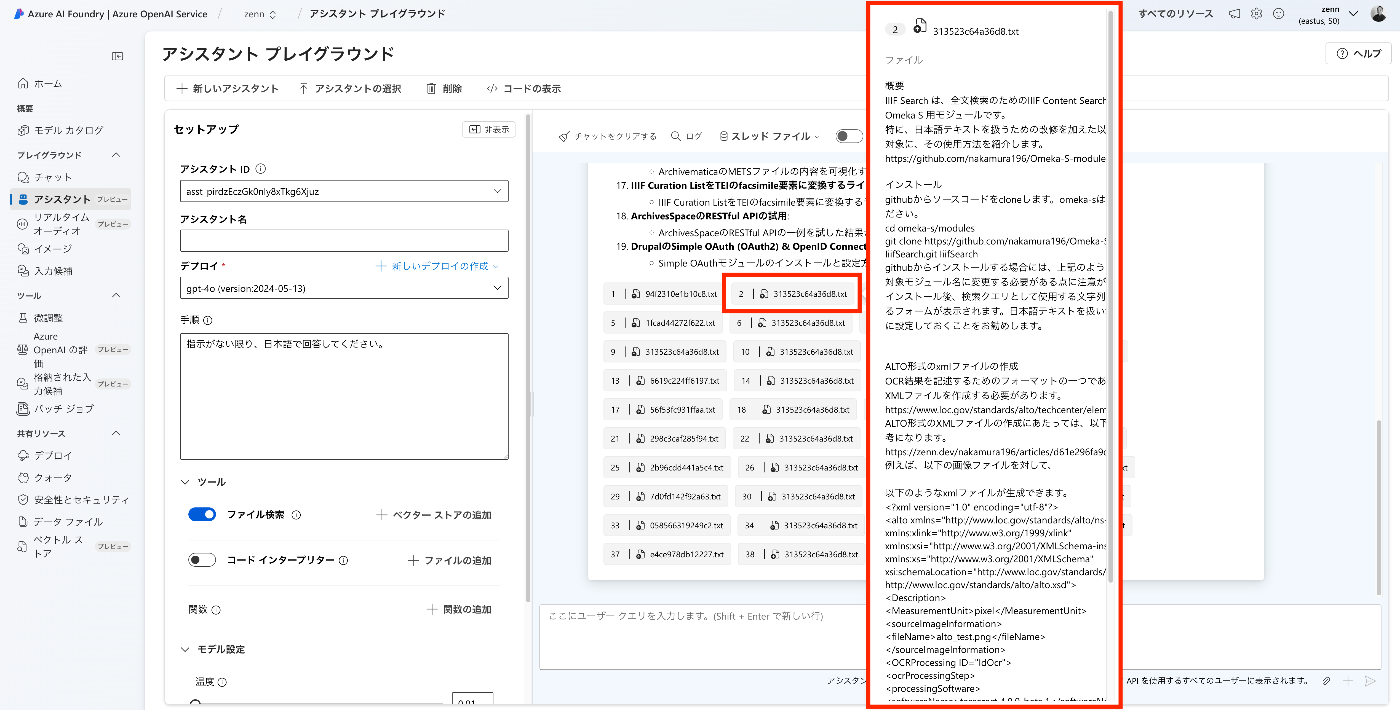
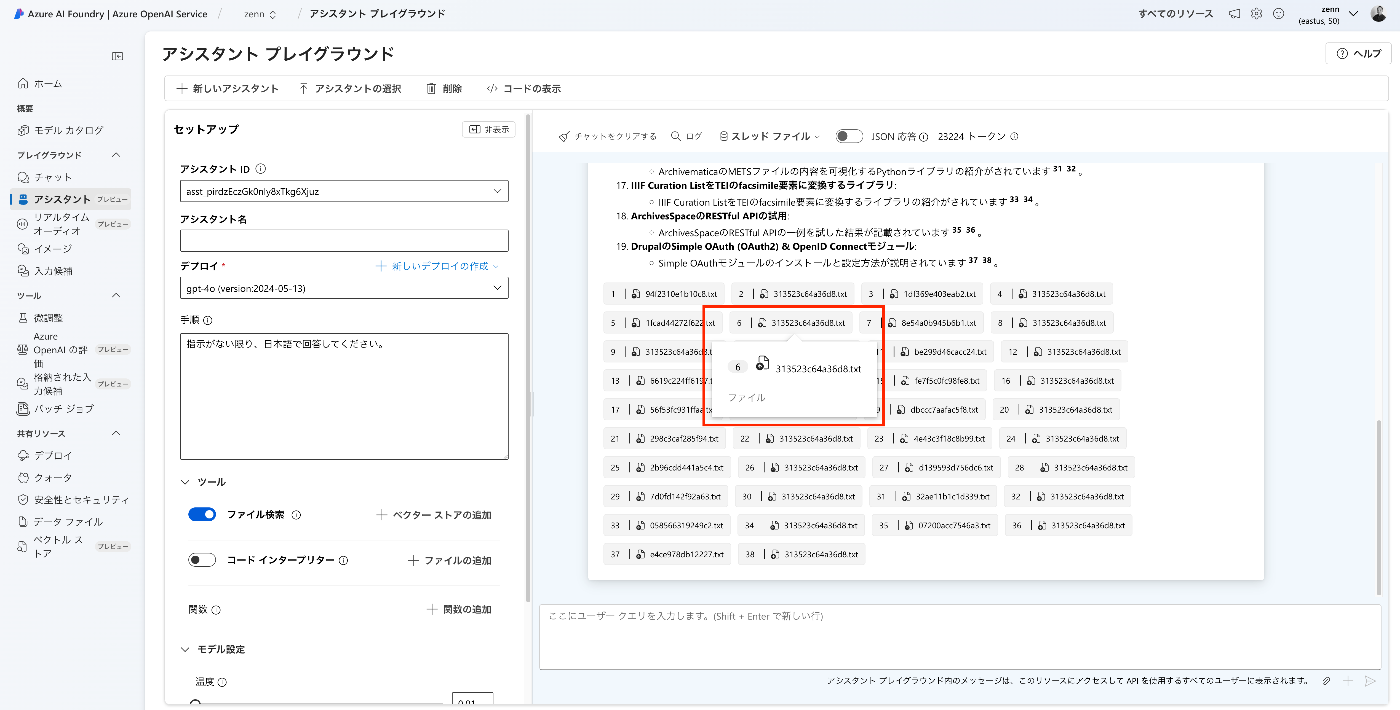
少し気になった挙動として、同じファイルが複数回Citationされた場合、2つ目以降はコンテンツが空の形で表示されるようでした。
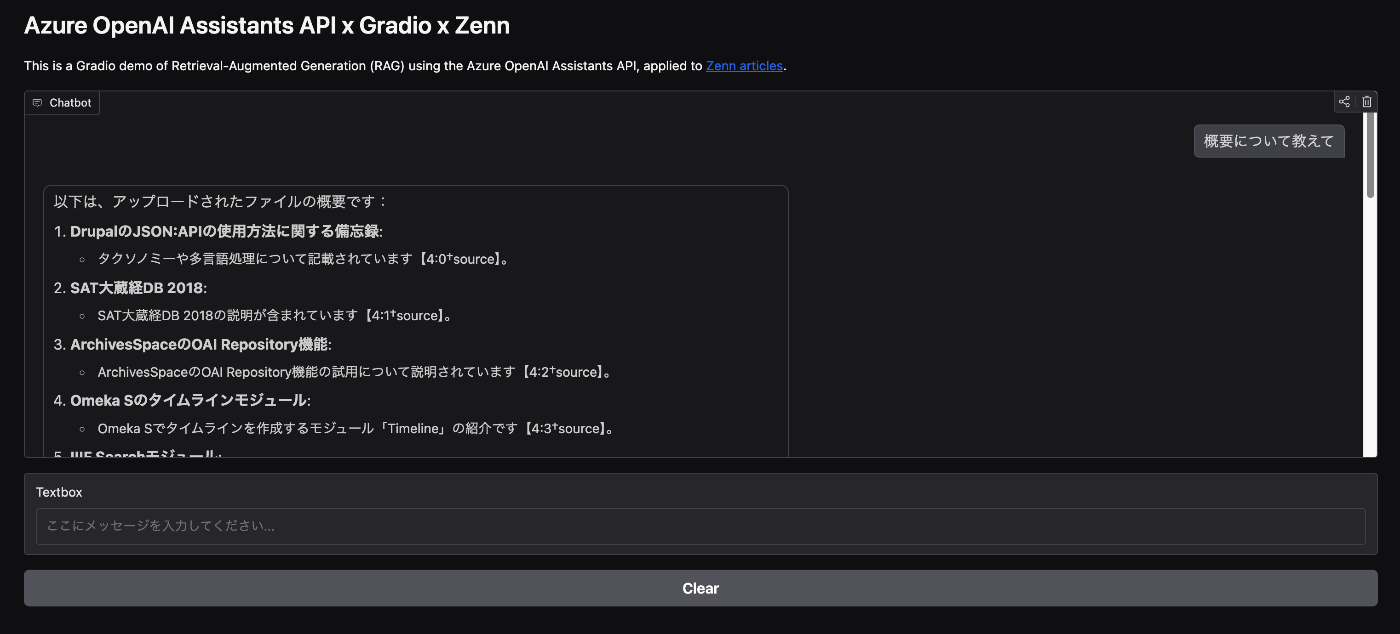
Gradio
Azure OpenAI Assistants APIとGradioを使ったアプリを試作しました。以下のSpacesからお試しいただけます。
https://huggingface.co/spaces/nakamura196/zenn
実装方法は以下をご確認ください。
https://huggingface.co/spaces/nakamura196/zenn/tree/main
GradioのChatbotとAzure OpenAI Assistants APIを組み合わせるにあたり、一部変則的な実装を行なっている点がありますが、参考になりましたら幸いです。
Next.js
同様に、openai-assistants-quickstartを使ったアプリも試作しました。以下でお試しいただけます。
https://openai-assistants-quickstart-zenn.vercel.app/examples/basic-chat

リポジトリは以下です。
https://github.com/nakamura196/openai-assistants-quickstart_zenn
openai-assistants-quickstartで、Azure OpenAI Serviceを使用するにあたり、openai.tsファイルを以下のように変更しました。
import { AzureOpenAI } from "openai";
export const openai = new AzureOpenAI({
endpoint: process.env.OPENAI_ENDPOINT,
apiKey: process.env.OPENAI_API_KEY,
deployment: "gpt-4o",
apiVersion: "2024-05-01-preview",
});
課題
GradioとNext.jsのどちらにおいても、以下のエラーが発生して、Citationのファイルの内容を取得することができませんでした。
この点については、引き続き調査したいと思います。
まとめ
Azure OpenAI Assistants APIの利用にあたり、参考になりましたら幸いです。