概要
DToC: Dynamic Table of Contextsを試す機会がありましたので、備忘録です。
https://www.leaf-vre.org/docs/features/dtoc
機械翻訳の結果は以下です。
セマンティックマークアップの威力と書籍のナビゲーション機能を融合させ、電子読書に革新をもたらします。従来の印刷書籍で長年親しまれてきた目次とキーワード索引という概観機能が、全文検索やタグベースのインデックス機能と動的に統合されることで、新たな読書体験を実現します。
最終的に、以下のような可視化を行うことができました。
https://dtoc.leaf-vre.org/view?document=https://dtoc-demo.vercel.app/P-III-b-1189/dtoc.json
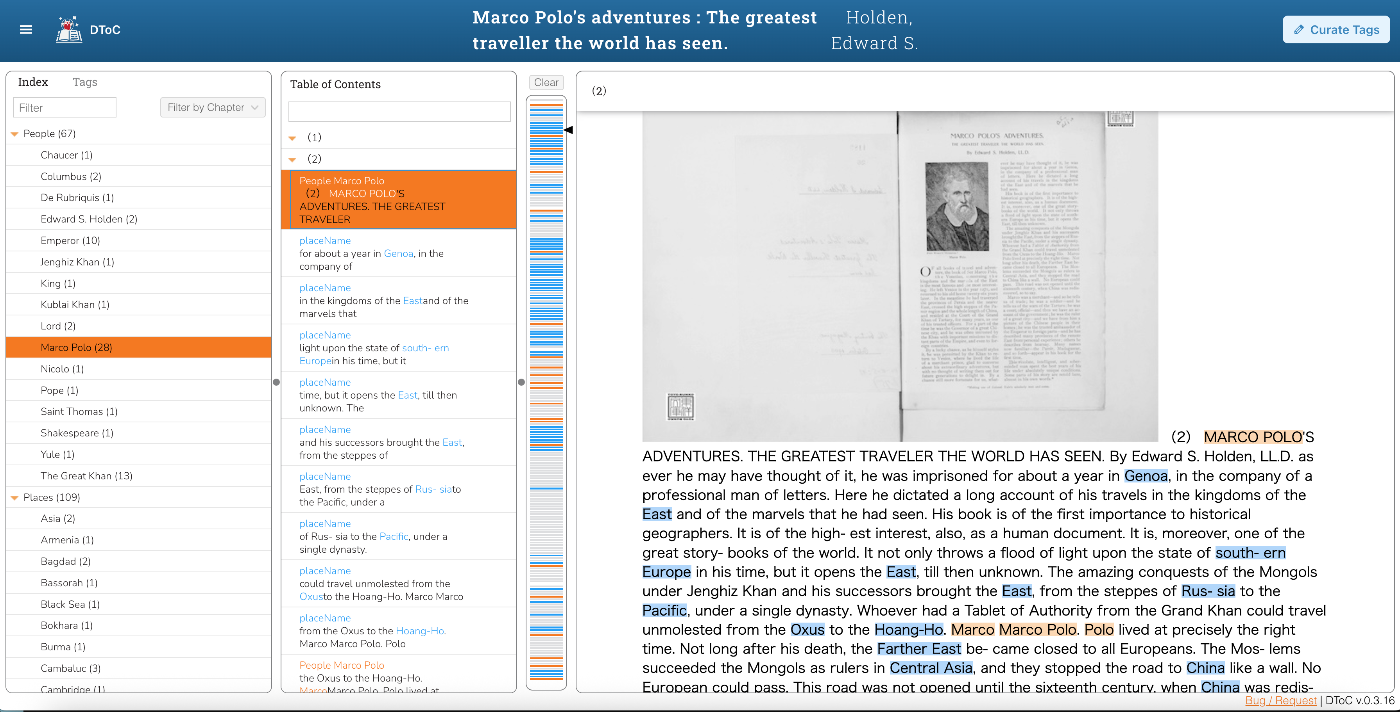
対象データ
東洋文庫が所蔵するモリソンパンフレット「Marco Polo’s adventures : The greatest traveller the world has seen.」をサンプルデータとして利用しました。
https://www.toyo-bunko.org/open/show_detail_open.php?targetid=363479
https://www.toyo-bunko.org/morisonp2015/morisonpocr2016_showimg.php?tgfn=P-III-b-1189&tgfn2=01Geo01
背景
以下のワークショップに参加し、DToCの使用方法を教えてもらいました。
https://github.com/LEAF-VRE/dh2025_workshop
以下のチュートリアルも参考になりました。
https://www.leaf-vre.org/docs/training/tutorials/dtoc-tutorial
mainとなるxmlを作成する
まず、mainとなるxmlを作成します。以下のURLで確認できます。
https://dtoc-demo.vercel.app/P-III-b-1189/main.xml
OCR
Azure AI Document Intelligenceを用いてOCRを行いました。
https://azure.microsoft.com/en-us/products/ai-services/ai-document-intelligence
校正 & タグづけ
OCR結果の校正と、人名や地名のタグ付与にあたり、「Google: Gemini 2.5 Pro」を使用しました。
https://deepmind.google/models/gemini/pro/
このように機械的な処理のため、誤りなどが含まれている可能性が高いですが、DToCで使用するためのTEI/XMLファイルを用意することができました。
index用のxmlを作成する
以下を参考にしました。
https://www.leaf-vre.org/docs/training/tutorials/dtoc-tutorial#step-2-create-an-index
このindex作成にも「Google: Gemini 2.5 Pro」を使用し、先に作成したmain.xmlから機械的に作成しました。結果は以下です。
https://dtoc-demo.vercel.app/P-III-b-1189/index.xml
JSONファイルを作成する
DToCでロードするためのJSONファイルを作成します。この部分はGUIから行うことができました。最終的な結果は以下です。
https://dtoc-demo.vercel.app/P-III-b-1189/dtoc.json
まず、以下にアクセスし、GitHubアカウントでログインします。
次に以下にアクセスします。
https://dtoc.leaf-vre.org/view
そして、チュートリアル資料などを参考に、必要な項目を入力します。

Documentsには、前のプロセスで作成したXMLファイルのURLを入力します。
Corpus Partsでは、XMLファイルのどの部分を使用するか、を指定します。Curpus Partではmain.xmlのdivタグを、Curpus Indexではindex.xmlのdivタグをXPathで指定しました。
Formattingについては、表示する画像をXPathでしています。main.xmlのfigureの記述例は以下です。
<div type="page" n="1">
<figure>
<graphic url="https://dtoc-demo.vercel.app/P-III-b-1189/images/P-III-b-1189_001.jpg"></graphic>
</figure>
<head><title>(1)</title></head>
<p xml:id="p_1"><persName xml:id="pers_1">Edward S. Holden</persName>, LLD. <lb /><persName xml:id="pers_2">Marco Polo</persName>'s Adventures <lb />The Greatest Traveller the World <lb />has seen <lb />The Century Magazine <lb /><date xml:id="date_1">October, 1900</date> <lb />PL-E-5:11 <lb />75</p>
</div>
最後のCurationについては、以下のGUIから設定します。次のページの画面右上の「Curate Tags」から、ハイライトしたい要素をXPathで指定します。

これらの設定により、IndexやTagsが利用可能になり、当該テキストがハイライト表示されます。

まとめ
TEI/XMLファイルの可視化を行うにあたり、強力なツールだと思いました。
一方、2025年7月16日時点において、日本語を含むTEI/XMLはうまく表示されませんでした。
https://gitlab.com/calincs/cwrc/dtoc/dtoc-commons/-/issues/13
この問題が解決され次第、日本語のテキストにも適用してみたいと思います。