Mirador 4で任意の領域をハイライト表示する方法
はじめに IIIFビューアのMiradorには検索機能があり、IIIF Search APIに対応したマニフェストでは検索結果をハイライト表示できます。しかし、Search APIに非対応のマニフェストでも、任意の領域をハイライト表示したいケースがあります。
本記事では、Miradorの内部APIを利用して、外部データソースからのアノテーション情報を基にハイライト表示を実現する方法を紹介します。
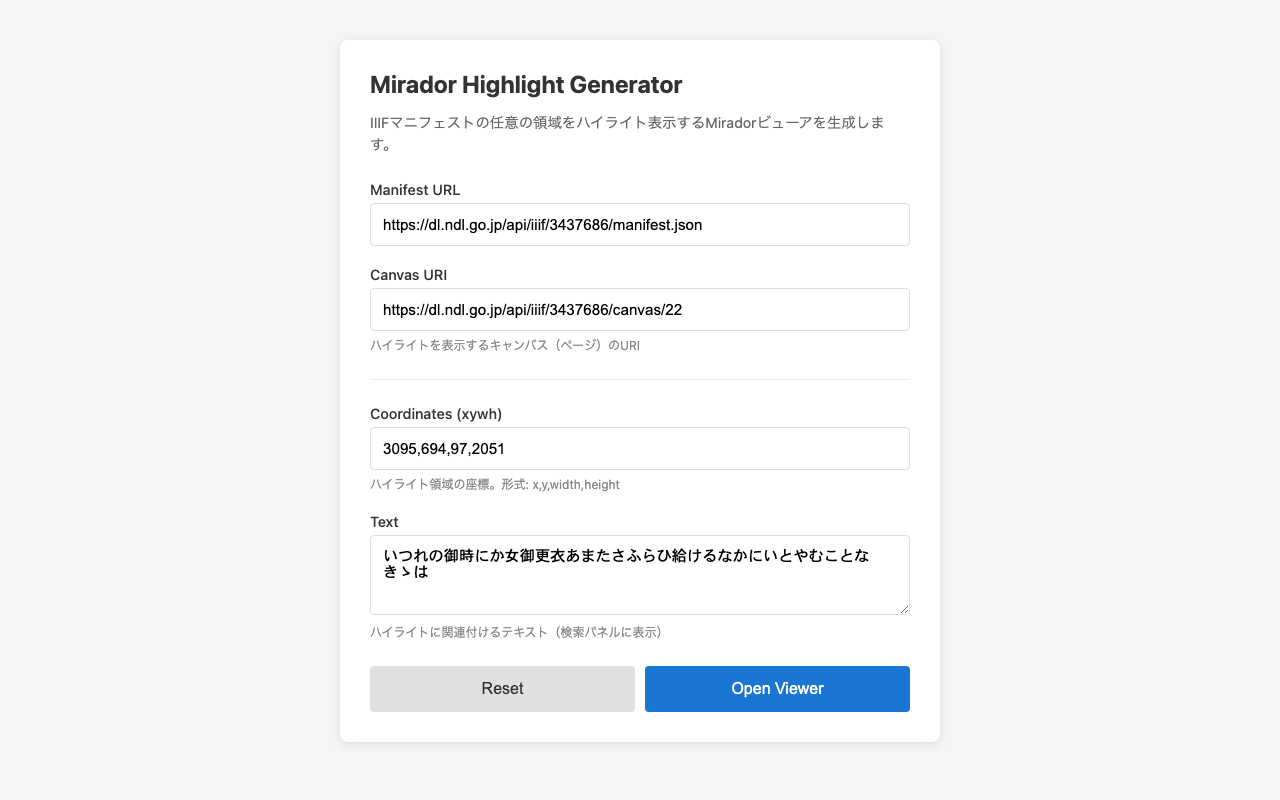
デモ Highlight Generator Form - フォームからハイライトを生成 ユースケース 独自のOCRシステムで抽出したテキスト領域のハイライト 機械学習で検出したオブジェクトの領域表示 外部データベースに保存されたアノテーションの可視化 Search API非対応のIIIFサーバーでの検索結果表示 実装方法 基本的な仕組み Miradorは内部でReduxを使用しており、receiveSearchアクションを通じて検索結果を登録できます。このアクションにIIIF Search API形式のJSONを渡すことで、任意のデータソースからのハイライトを表示できます。
必要な情報 ハイライトを表示するために必要な情報は以下の3つです:
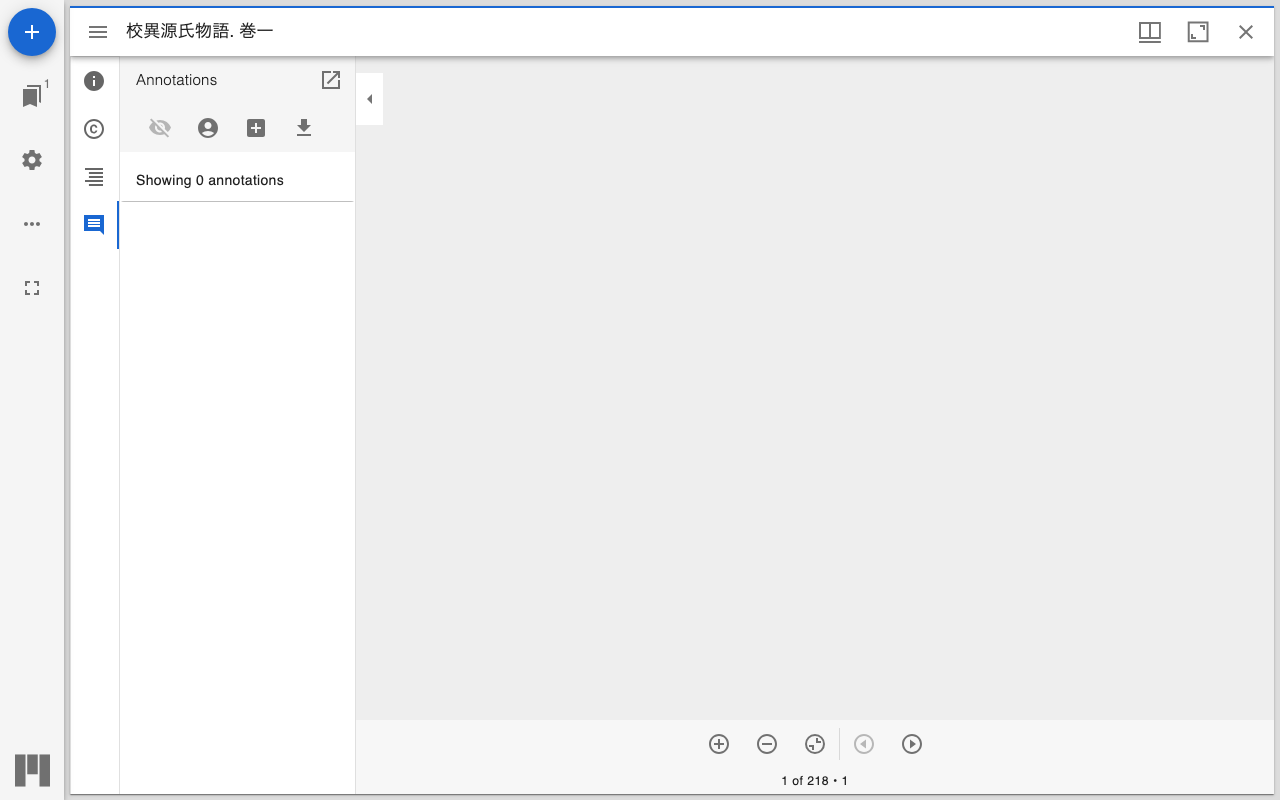
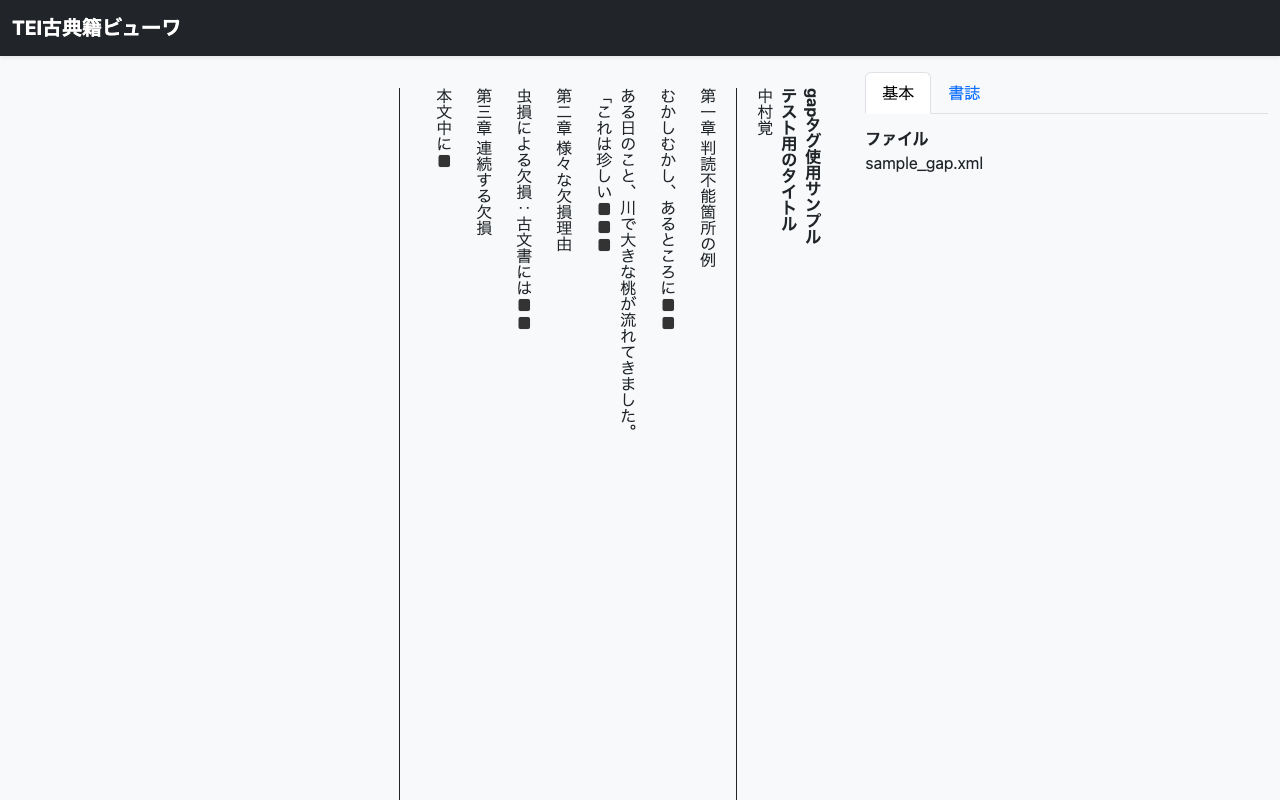
キャンバスURI - ハイライトを表示するページのURI 座標(xywh) - ハイライト領域の位置とサイズ(x, y, width, height) テキスト - ハイライトに関連付けるテキスト(検索パネルに表示される) サンプルコード 以下は、国立国会図書館デジタルコレクションの源氏物語で「いつれの御時にか…」の冒頭部分をハイライト表示するサンプルです。
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Mirador Custom Highlight Sample</title> <style> body { margin: 0; padding: 0; } #mirador-viewer { width: 100%; height: 100vh; } </style> </head> <body> <div id="mirador-viewer"></div> <script src="https://unpkg.com/mirador@4.0.0-alpha.15/dist/mirador.min.js"></script> <script> // 設定パラメータ const config = { manifestUrl: 'https://dl.ndl.go.jp/api/iiif/3437686/manifest.json', canvasId: 'https://dl.ndl.go.jp/api/iiif/3437686/canvas/22', highlights: [ { xywh: '3095,694,97,2051', text: 'いつれの御時にか女御更衣あまたさふらひ給けるなかにいとやむことなきゝは', }, ], }; // Miradorを初期化 const miradorViewer = Mirador.viewer({ id: 'mirador-viewer', selectedTheme: 'light', language: 'ja', windows: [{ id: 'window-1', manifestId: config.manifestUrl, canvasId: config.canvasId, thumbnailNavigationPosition: 'far-right', }], window: { allowFullscreen: true, allowClose: false, allowMaximize: false, sideBarOpen: true, }, workspaceControlPanel: { enabled: false, }, }); // ハイライトを追加する関数 function addHighlights(viewer, canvasId, highlights) { // IIIF Search API形式のレスポンスを構築 const searchResponse = { '@context': 'http://iiif.io/api/search/1/context.json', '@id': canvasId + '/search', '@type': 'sc:AnnotationList', within: { '@type': 'sc:Layer', total: highlights.length, }, resources: highlights.map((highlight, index) => ({ '@id': canvasId + '/highlight-' + index, '@type': 'oa:Annotation', motivation: 'sc:painting', resource: { '@type': 'cnt:ContentAsText', chars: highlight.text, }, on: canvasId + '#xywh=' + highlight.xywh, })), }; // 検索パネルを右側に追加 const addAction = Mirador.addCompanionWindow('window-1', { content: 'search', position: 'right', }); viewer.store.dispatch(addAction); // companionWindowIdを取得 const state = viewer.store.getState(); const searchCompanionWindowId = Object.keys(state.companionWindows).find( id => state.companionWindows[id].content === 'search' ); if (searchCompanionWindowId) { // 検索結果を登録 const searchAction = Mirador.receiveSearch( 'window-1', searchCompanionWindowId, canvasId + '/search', searchResponse ); viewer.store.dispatch(searchAction); } } // マニフェストの読み込み完了を監視してハイライトを追加 let highlightAdded = false; const unsubscribe = miradorViewer.store.subscribe(() => { if (highlightAdded) return; const state = miradorViewer.store.getState(); const manifests = state.manifests || {}; const manifest = manifests[config.manifestUrl]; // マニフェストが読み込み完了したらハイライトを追加 if (manifest && !manifest.isFetching && manifest.json) { highlightAdded = true; unsubscribe(); addHighlights(miradorViewer, config.canvasId, config.highlights); } }); </script> </body> </html> コードの解説 1. 設定パラメータ const config = { manifestUrl: 'https://dl.ndl.go.jp/api/iiif/3437686/manifest.json', canvasId: 'https://dl.ndl.go.jp/api/iiif/3437686/canvas/22', highlights: [ { xywh: '3095,694,97,2051', text: 'いつれの御時にか...', }, ], }; manifestUrl: IIIFマニフェストのURL canvasId: ハイライトを表示するキャンバスのURI highlights: ハイライト情報の配列。複数のハイライトを追加可能 2. IIIF Search API形式のレスポンス構築 const searchResponse = { '@context': 'http://iiif.io/api/search/1/context.json', '@type': 'sc:AnnotationList', resources: highlights.map((highlight, index) => ({ '@type': 'oa:Annotation', motivation: 'sc:painting', resource: { '@type': 'cnt:ContentAsText', chars: highlight.text, }, on: canvasId + '#xywh=' + highlight.xywh, })), }; ポイントは on プロパティで、キャンバスURI#xywh=x,y,width,height の形式でハイライト領域を指定します。
...
2025年12月7日 · 更新: 2025年12月7日 · 3 分 · Nakamura