Drupal: UUIDを表示する
概要 以下のように、コンテンツのUUIDを表示する方法の備忘録です。 モジュールのインストール 以下のモジュールを使用しました。 https://www.drupal.org/project/uuid_extra 使い方 UUIDを表示したいコンテンツタイプの「Manage display」タブを選択し、以下のように、UUIDを移動させます。 まとめ 参考になりましたら幸いです。

概要 以下のように、コンテンツのUUIDを表示する方法の備忘録です。 モジュールのインストール 以下のモジュールを使用しました。 https://www.drupal.org/project/uuid_extra 使い方 UUIDを表示したいコンテンツタイプの「Manage display」タブを選択し、以下のように、UUIDを移動させます。 まとめ 参考になりましたら幸いです。
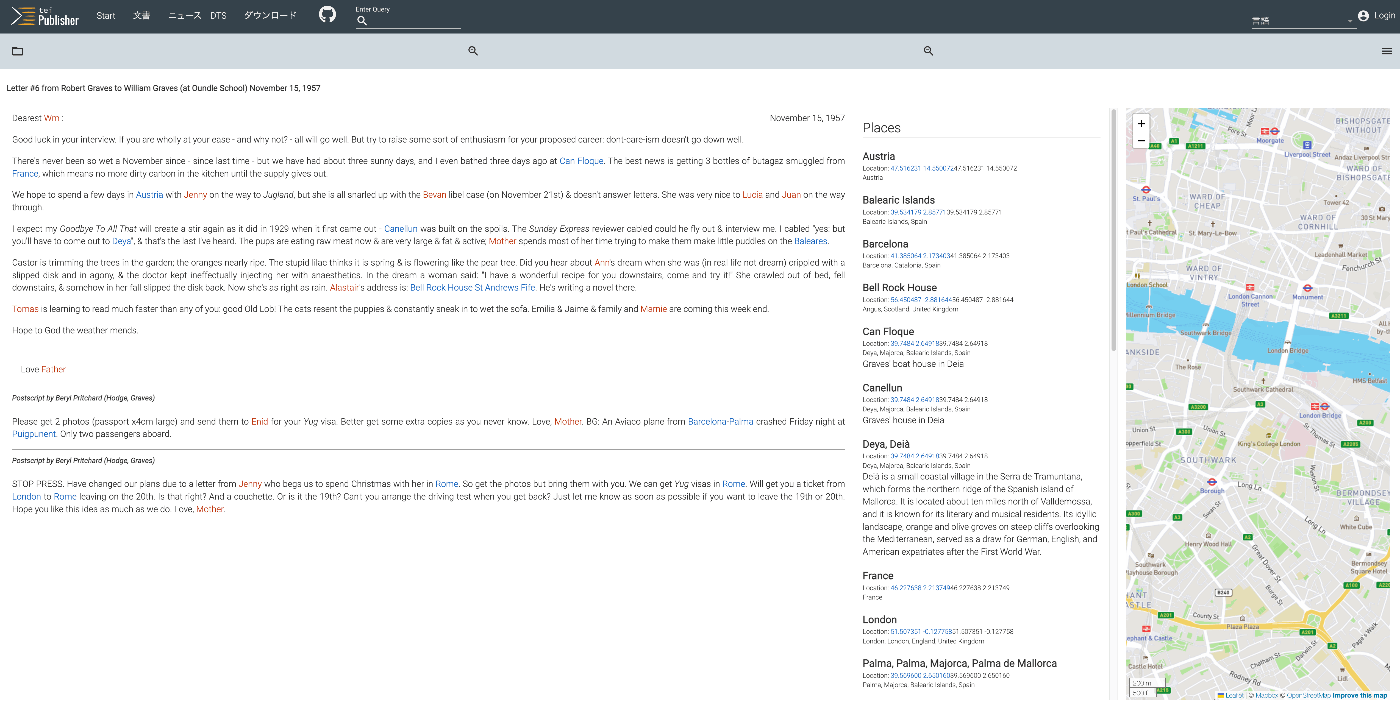
概要 TEI Publisherの以下のページでは、さまざまな可視化例が紹介されています。 https://teipublisher.com/exist/apps/tei-publisher/index.html?query=&collection=test&sort=title&field=text&start=1 以降、複数の記事にわたって、上記の可視化例を紹介します。 Letter #6 from Robert Graves to William Graves (at Oundle School) November 15, 1957 概要 https://teipublisher.com/exist/apps/tei-publisher/test/graves6.xml 以下のように、地名や人名の一覧、および地図とともにテキストが表示されます。 以下のように説明されています。 A 20th century manuscript letter from Robert Graves where emphasis has been put on visualizing rich encoding of semantic information in the letter, in particular geographic and prosopographical data. The map is displayed with a pb-leaflet component. 機械翻訳 ロバート・グレイブスによる20世紀の写本書簡。書簡中の意味情報、特に地理的・韻律的データの豊富な符号化を視覚化することに重点が置かれている。地図はpb-leafletコンポーネントで表示される。 データ XMLファイルの特徴です。 teiHeader > profileDesc > abstract abstractタグの内容が上記の検索ページに表示されるようです。 ...
Splitpanesは、以下のように、ペイン(pane)分割・リサイズを可能にするVue.jsのライブラリです。 https://github.com/antoniandre/splitpanes このライブラリの利用にあたり、ペインにiframe要素を含む際、リサイズがうまくできないことがありました。これに対して、以下で対応方法が記載されていました。 https://github.com/antoniandre/splitpanes/pull/162 上記に記載がある通り、以下を追記することで、iframe要素を含むペインがあっても、正しくリサイズ操作を行うことができました。 .splitpanes--dragging .splitpanes__pane { pointer-events: none; } 同様のことでお困りの方の参考になりましたら幸いです。

概要 以下の画像にあるように、Nuxt3を使ってXML形式のテキストデータを表示する機会がありましたので、その備忘録です。 インストール 以下の2つのライブラリを使用しました。 npm i xml-formatter npm i highlight.js 使い方 Nuxt3のコンポーネントとして、以下のようなファイルを作成しました。xml-formatterでXML形式の文字列をフォーマットし、さらにhighlight.jsを使ってシンタックスハイライトを行っています。 <script setup lang="ts"> import hljs from "highlight.js"; import "highlight.js/styles/xcode.css"; import formatter from "xml-formatter"; interface PropType { xml: string; } const props = withDefaults(defineProps<PropType>(), { xml: "", }); const formattedXML = ref<string>(""); onMounted(() => { // `highlightAuto` 関数が非同期でない場合は、 // `formattedXML` を直接アップデートできます。 // そうでない場合は、適切な非同期処理を行ってください。 formattedXML.value = hljs.highlightAuto(formatXML(props.xml)).value; }); const formatXML = (xmlstring: string) => { return formatter(xmlstring, { indentation: " ", filter: (node) => node.type !== "Comment", }); }; </script> <template> <pre class="pa-4" v-html="formattedXML"></pre> </template> <style> pre { /* 以下のスタイルは適切で、pre要素内のテキストの折り返しを制御しています。 */ white-space: pre-wrap; /* CSS 3 */ white-space: -moz-pre-wrap; /* Mozilla, 1999年から2002年までに対応 */ white-space: -pre-wrap; /* Opera 4-6 */ white-space: -o-pre-wrap; /* Opera 7 */ word-wrap: break-word; /* Internet Explorer 5.5+ */ } </style> まとめ TEI/XMLデータの可視化などにおいて、参考になりましたら幸いです。 ...

概要 以下の記事でODDの作成を試しました。 上記ではRomaというツールを使用していますが、作成したODDについて、以下に示す出力フォーマットがあることがわかります。 具体的には、「RELAX NGスキーマ」「RELAX NGコンパクト」「W3Cスキーマ」「文書型定義」「ISO Schematron制約」が挙げられます。 そこで、これらの違いについて、GPT-4に問い合わせてみたので、その結果を共有します。誤った内容も含まれるかもしれませんが、参考になりましたら幸いです。 Relax NG(RNG)とW3C XMLスキーマの違い Relax NG(RNG)とW3C XMLスキーマは、どちらもXML文書の構造と内容を定義するためのスキーマ言語ですが、いくつかの重要な違いがあります: 表記法 : RNG : 2つの構文を提供します。一つはXMLベースのもので、もう一つはよりコンパクトな非XMLの構文です。 W3C XMLスキーマ : XMLベースの構文のみを提供します。 柔軟性と明瞭性 : RNG : RNGは非常に柔軟で、人が読みやすい設計になっています。パターンベースのアプローチを取り、より直感的なモデリングが可能です。 W3C XMLスキーマ : より厳格で形式的なアプローチを取り、型システムが複雑ですが、これにより強力なデータタイピングが可能になります。 データタイピング : RNG : データタイプはDatatype Libraryを介してサポートされていますが、W3C XMLスキーマほど多様ではありません。 W3C XMLスキーマ : 豊富なビルトインデータタイプを提供し、正確なデータ型制約を設定できます。 拡張性 : RNG : 簡潔さと柔軟性により、スキーマ自体を容易に拡張できます。 W3C XMLスキーマ : 拡張性はありますが、より複雑な構造のため、理解と実装が難しくなる場合があります。 普及度 : RNG : シンプルさと強力なモデリング機能にも関わらず、W3C XMLスキーマほど広くは採用されていません。 W3C XMLスキーマ : より一般的に使用されており、多くのXML処理ツールやライブラリで標準的にサポートされています。 これらの違いにも関わらず、どちらの言語もXML文書の構造を定義し、文書の妥当性を検証するという共通の目的を持っています。選択はしばしば個々のプロジェクトのニーズや開発者の好みに依存します。 DTD(Document Type Definition)との関係は? DTD(Document Type Definition)は、XML文書の構造を定義するための一つの仕様で、W3C XMLスキーマやRelax NG(RNG)よりも歴史が古く、制約を記述する方法が限られています。DTDは非常にシンプルで、XMLの初期から使われている標準的な方法ですが、名前空間やデータ型などのより高度な概念をサポートしていません。 W3C XMLスキーマやRNGに比べて、DTDは次のような制約があります: ...

概要 以下の記事で、Romaの使い方を説明しました。 今回は、手元にあるTEI/XMLを対象として、TEI ODD (One Document Does-it-all)や解説(HTMLやPDF)の作成に関する一連の流れを説明します。 なお、ODD (One Document Does it all) と RNG (RelaxNG) の違いについて、GPT-4による回答結果を末尾に掲載しています。こちらも参考にしてください。 使用するタグの一覧を取得する まず、プロジェクトで使用するタグの一覧を取得します。 今回、手元にあるTEI/XMLを対象として、使用されているタグの一覧を取得するライブラリおよびチュートリアル用のノートブックを作成しました。 ライブラリ https://nakamura196.github.io/gdb-utils/ チュートリアル用のノートブック https://colab.research.google.com/github/nakamura196/000_tools/blob/main/TEIでタグの使用頻度を分析するチュートリアル.ipynb 例えば、上記のノートブックを実行すると、以下のような結果が得られます。以下は、対象としたTEI/XMLファイル中に含まれるタグとその頻度を取得し、その結果をタグの名前について昇順で取得したものです。 index Tag Count 0 TEI 1 18 addrLine 1 17 address 1 50 app 8 5 author 2 58 back 1 36 bibl 1 47 body 1 56 closer 1 44 correspAction 2 43 correspDesc 1 20 country 1 33 date 6 26 dimensions 1 19 district 1 54 div 1 37 editor 1 40 editorialDecl 1 39 encodingDesc 1 25 extent 2 2 fileDesc 1 29 handDesc 1 30 handNote 1 27 height 1 31 history 1 21 idno 2 16 institution 1 55 lb 13 51 lem 8 59 listPerson 1 12 listWit 1 45 location 1 14 msDesc 1 15 msIdentifier 1 23 objectDesc 1 48 opener 1 32 origin 1 … Romaでタグを限定したODDファイルを作成する 上記で取得したタグに限定したODDファイルを、Romaというツールを用いて作成します。 ...

概要 Versioning Machine(VM5.0)は、校異情報の可視化を行うアプリケーションです。 http://v-machine.org/ ここでは、Visual Studio Code(VSCode)を用いて、自身が作成したTEI/XMLファイルを本アプリケーションで表示する方法について説明します。 なお、表示対象となるTEI/XMLファイルは、以下のように、<listWit>タグで校異情報が記述されているものです。 <TEI xmlns="http://www.tei-c.org/ns/1.0"> <teiHeader> <fileDesc> <titleStmt> ... </titleStmt> <publicationStmt> ... </publicationStmt> <sourceDesc> <listWit> <witness xml:id="WA"> <title xml:lang="ja">ヴァイマル版ゲーテ全集(略称WA)</title> <title xml:lang="de">Goethes Werke. herausgegeben im Auftrage der Großherzogin Sophie von Sachsen</title> </witness> <witness xml:id="UTL"> <title xml:lang="ja">東京大学総合図書館所蔵のゲーテ自署付書簡</title> <title xml:lang="de">Der Brief von Goethe an Ludwig Wilhelm Cramer vom 29. Dezember 1822 im Besitz der Universitätsbibliothek Tokio</title> </witness> </listWit> <msDesc sameAs="#UTL"> ... 後述しますが、本記事では以下で公開されている、東京大学総合図書館所蔵のゲーテ自署付書簡のテキストデータを使用します。 https://utda.github.io/goethe/data/xml/goethe.xml ソースコードのダウンロード 以下のページにアクセスします。 http://v-machine.org/download/ そして、以下の「Click here」をクリックします。 Click here to download the latest or earlier versions of the Versioning Machine. ...
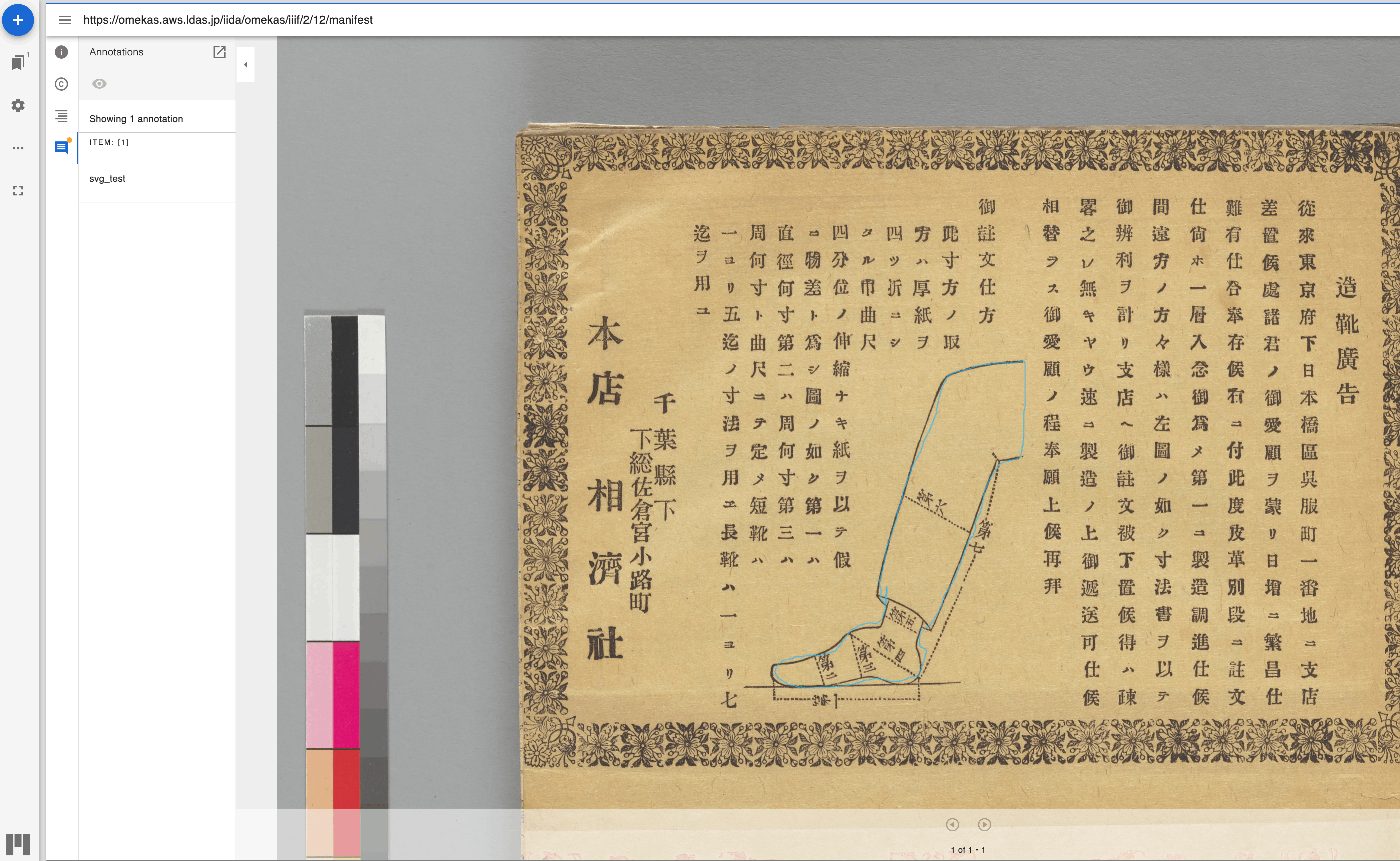
フリーハンドのアノテーションを矩形に変換するPythonライブラリを作成しました。 以下のようなフリーハンドで作成したアノテーションを入力として、 以下のような矩形のアノテーションに変換します。 『田中芳男・博物学コレクション』(東京大学総合図書館所蔵)を使用しています。 具体的な使用方法は、以下のノートブックをご確認ください。 https://github.com/nakamura196/000_tools/blob/main/フリーハンドのアノテーションを矩形に変換する.ipynb IIIFのアノテーションの活用にあたり、参考になりましたら幸いです。
目的 以下のように、フィールドの値の入力方法を選択式にする方法について説明します。 以下、テキストの場合と、エンティティ参照の場合のそれぞれについて説明します。 テキストの場合 ageというフィールドを作成します。ここで「リスト(テキスト)」を選択します。 以下のように選択肢を入力します。 結果、以下のように、「選択リスト」形式でフィールドを編集できるようになります。 さらに、コンテンツタイプの一覧ページから、「フォームの表示管理」を押します。 /admin/structure/types そしてageフィールドのウィジェットを「チェックボックス/ラジオボタン」に変更してみます。 結果、以下のようにフォームが変化します。 エンティティ参照 エンティティ参照の場合も上記と同様です。例えば、以下の記事で作成したフィールドを対象にします。 「フォームの表示管理」から、ウィジェットを「チェックボックス/ラジオボタン」に変更します。すると、以下のように、フォームが変化します。 まとめ フォームの表示管理について、参考になりましたら幸いです。 参考 Drupal で値を管理する際にテキストのリスト形式を選択するか、Vocabulary (タクソノミー) を使うか、について問い合わせてみました。こちらも参考になりましたら幸いです。 GPT-4による回答 Drupal で値を管理する際にテキストのリスト形式を選択するか、Vocabulary (タクソノミー) を使うかは、実際の使用シナリオや要件によって変わります。以下は、それぞれの選択肢の特徴と利点、制限点を示しています。 テキストのリスト形式 利点: シンプルで簡単にセットアップできる。 小さな固定のリストに適している。 選択リストやチェックボックスなどの形式で簡単に表示できる。 制限点: 項目間の関係や階層構造を持たせることができない。 リストが大きくなると管理が難しくなる可能性がある。 Vocabulary (タクソノミー) 利点: 項目間の関係や階層構造を持たせることができる。 項目にメタデータや説明、関連画像などを追加できる。 大量の項目や動的に変わる項目を管理するのに適している。 拡張機能やモジュールとの統合が豊富。 制限点: セットアップや管理がテキストのリスト形式よりも複雑になる可能性がある。 どちらを選ぶべきか? リストのサイズと変動性 : 小さく、あまり変わらないリストの場合はテキストのリスト形式が適しています。一方、大きい、または頻繁に変わるリストの場合は、Vocabulary の方が適しています。 関連データの必要性 : 項目に追加の情報や属性が必要な場合、Vocabulary の使用が推奨されます。 階層性や関連性 : カテゴリのように項目間に階層や関連性が必要な場合、Vocabulary が適しています。 シンプルさ : 簡単にセットアップし、シンプルに保ちたい場合は、テキストのリスト形式が良いでしょう。 最終的には、プロジェクトの要件や将来の拡張性を考慮して、最適な選択を行うことが重要です。

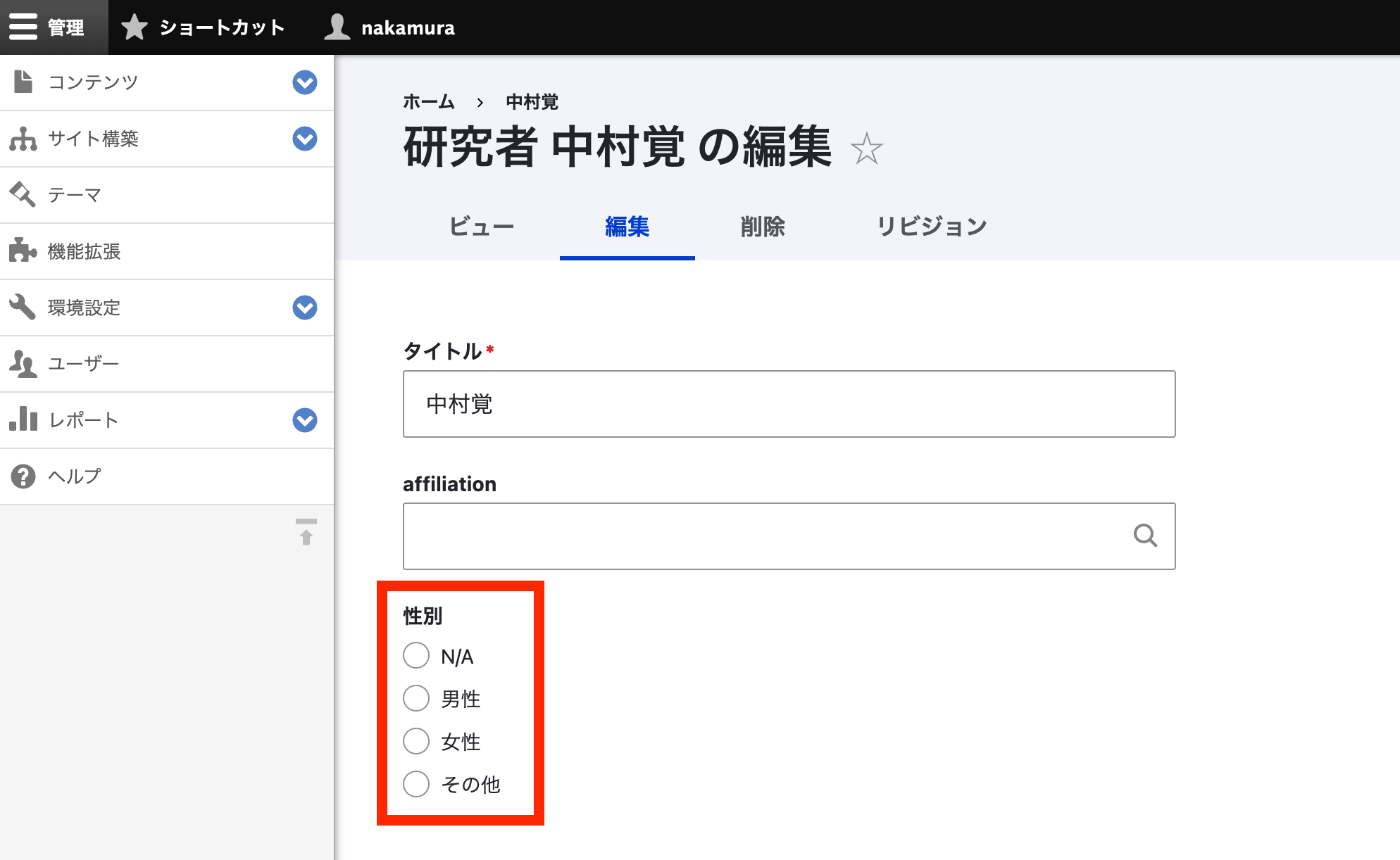
はじめに 例えば、Drupalで「組織」というコンテンツタイプを作成し、「東京大学」「京都大学」というコンテンツを作成します。 この時、Research Organization Registry (ROR)を使用して、以下のIDも登録したとします。 タイトル ID 東京大学 057zh3y96 京都大学 02kpeqv85 このコンテンツを他のコンテンツ(例えば、「研究者」コンテンツタイプ)からaffiliationフィールドを使って参照してみます。この時、以下のように大学と入力すると、登録済みの2件のコンテンツが表示されます。 一方、IDの一部である057などを入力しても、登録済みのコンテンツが表示されません。 そこで、本記事では、タイトルに加えて、他のフィールドでもコンテンツを探せるようにすることを目指します。 方法 ビューの作成 Drupalにログイン後、以下のURLにアクセスし、ビューを追加します。 /admin/structure/views/add ここでは、ビューの基本情報として、「組織」「organization」を与え、ビューの設定として、コンテンツのタイプを「組織」に限定しています。 次の画面に遷移後、まず以下のように「+追加」ボタンを押し、「エンティティ参照」を選択します。 以下のように、メッセージが表示されます。 ディスプレイ “エンティティ参照” が正しく動作するには、選択した検索フィールドが必要です。エンティティ参照リストのフォーマット設定を確認してください。 このメッセージに対応するには、フォーマット > フォーマット > 設定を押して、以下のように、検索フィールドにチェックを入れる必要がありました。 この結果、以下のように、タイトルが表示されます。 IDフィールドの追加 次に、IDフィールドを追加します。 フィールド > 追加 から、追加したいフィールド(ここではID)を追加します。 次に、フォーマット > フォーマット > 設定から、IDにもチェックを入れます。 結果、以下のように、タイトルとIDのペアで表示されるようになりました。 フィールド > 並び替え で順番を入れ替えてみます。 結果、以下のように、IDが先頭にくるようになりました。 IDの場合、昇順で並べるケースが考えられるため、ここでも並び順を変更してみます。具体的には、並び替え基準でIDフィールドを追加して、昇順にします。 また、デフォルトで登録済みであったコンテンツ: 投稿日時を削除します。 結果、以下のように、IDの昇順でエンティティ参照が並ぶようになりました。(ここでは、画面上は変化がありません。) そして「保存」ボタンを押して、設定を保存します。 フィールド管理への反映 作成したビューをフィールド管理に反映してみます。まず、以下のコンテンツタイプの一覧ページにアクセスします。 ...
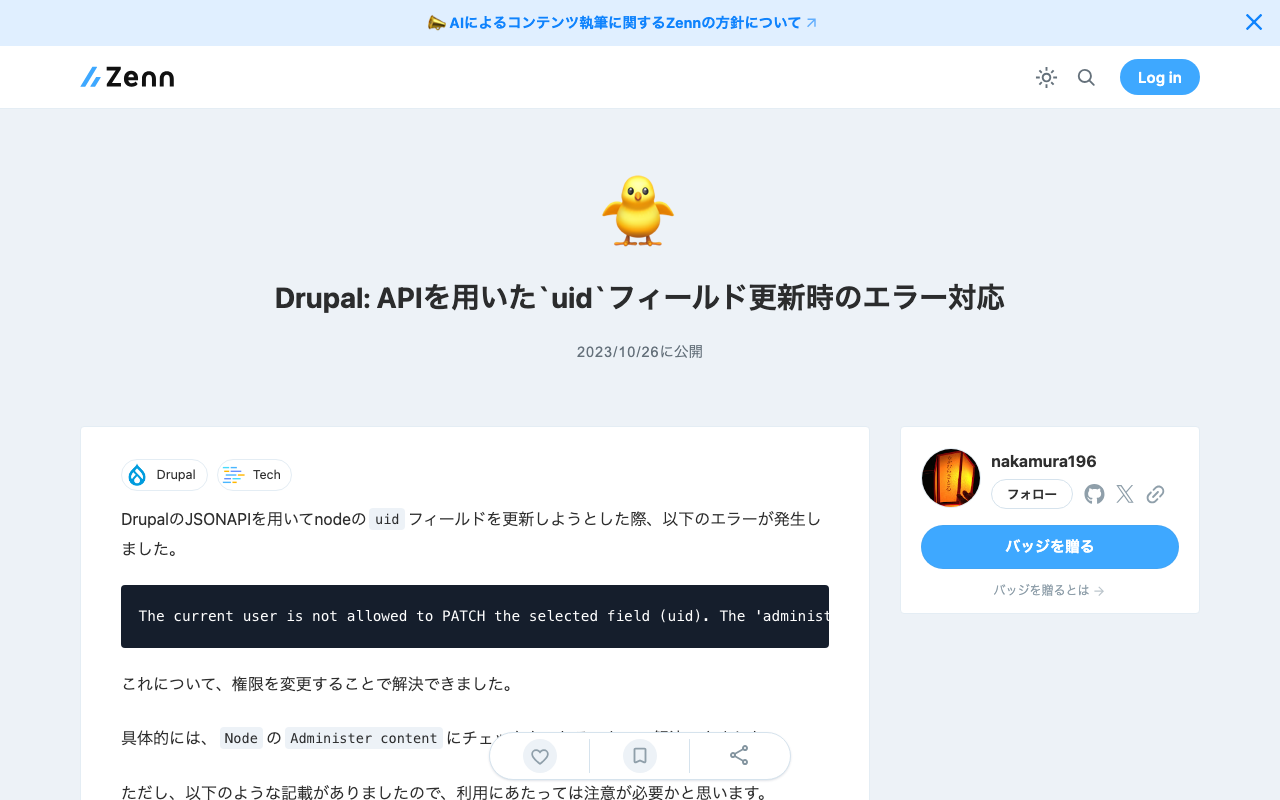
DrupalのJSONAPIを用いてnodeのuidフィールドを更新しようとした際、以下のエラーが発生しました。 The current user is not allowed to PATCH the selected field (uid). The 'administer nodes' permission is required. これについて、権限を変更することで解決できました。 具体的には、NodeのAdminister contentにチェックをいれることで、解決できました。 ただし、以下のような記載がありましたので、利用にあたっては注意が必要かと思います。 Warning: Give to trusted roles only; this permission has security implications. Promote, change ownership, edit revisions, and perform other tasks across all content types. 参考になりましたら幸いです。
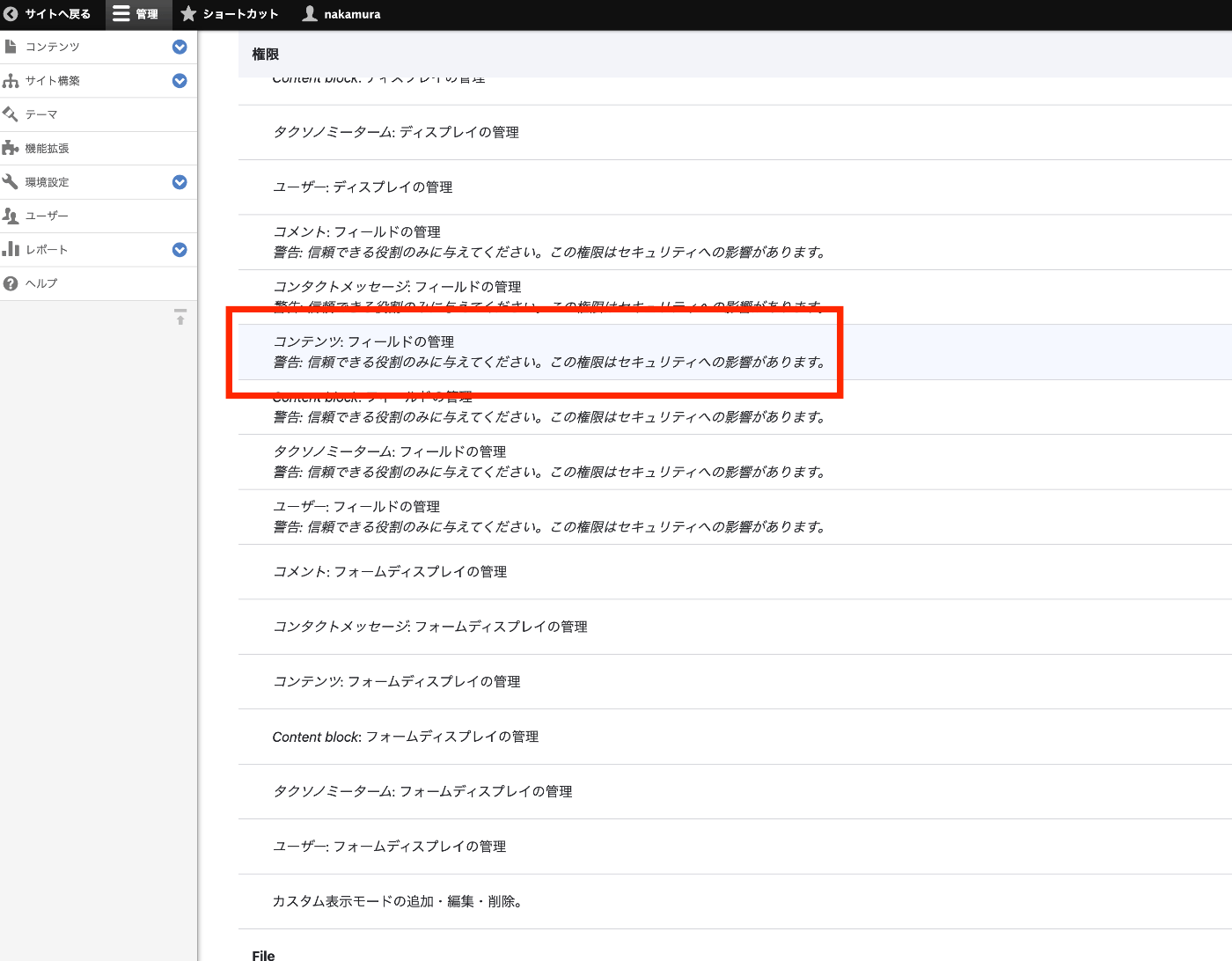
DrupalのJSONAPIの利用において、以下のようなクエリで、fieldのIDから、field_nameを取得しようとしたところ、結果が0件になりました。 https://xxx/jsonapi/field_config/field_config?fields[field_config–field_config]=label%2Cfield_name&filter[name-filter][condition][path]=field_name&filter[name-filter][condition][operator]=IN&filter[name-filter][condition][value][1]=field_xxx1&filter[name-filter][condition][value][2]=field_xxx2&filter[name-filter][condition][value][3]=field_xxx3&filter[bundle]=yyy 返却された結果のmetaの項目に、権限の問題が記載されていました。 { "jsonapi": { "version": "1.0", "meta": { "links": { "self": { "href": "http://jsonapi.org/format/1.0/" } } } }, "data": [], "meta": { "omitted": { "detail": "Some resources have been omitted because of insufficient authorization.", ... } }, ... } そこで、以下の図にある通り、Field UIのコンテンツ: フィールドの管理の権限を変更したところ、上記の権限の問題を解決することができました。 ただし、以下のような記載があるため、ご利用の際は十分に注意してください。 警告: 信頼できる役割のみに与えてください。この権限はセキュリティへの影響があります。
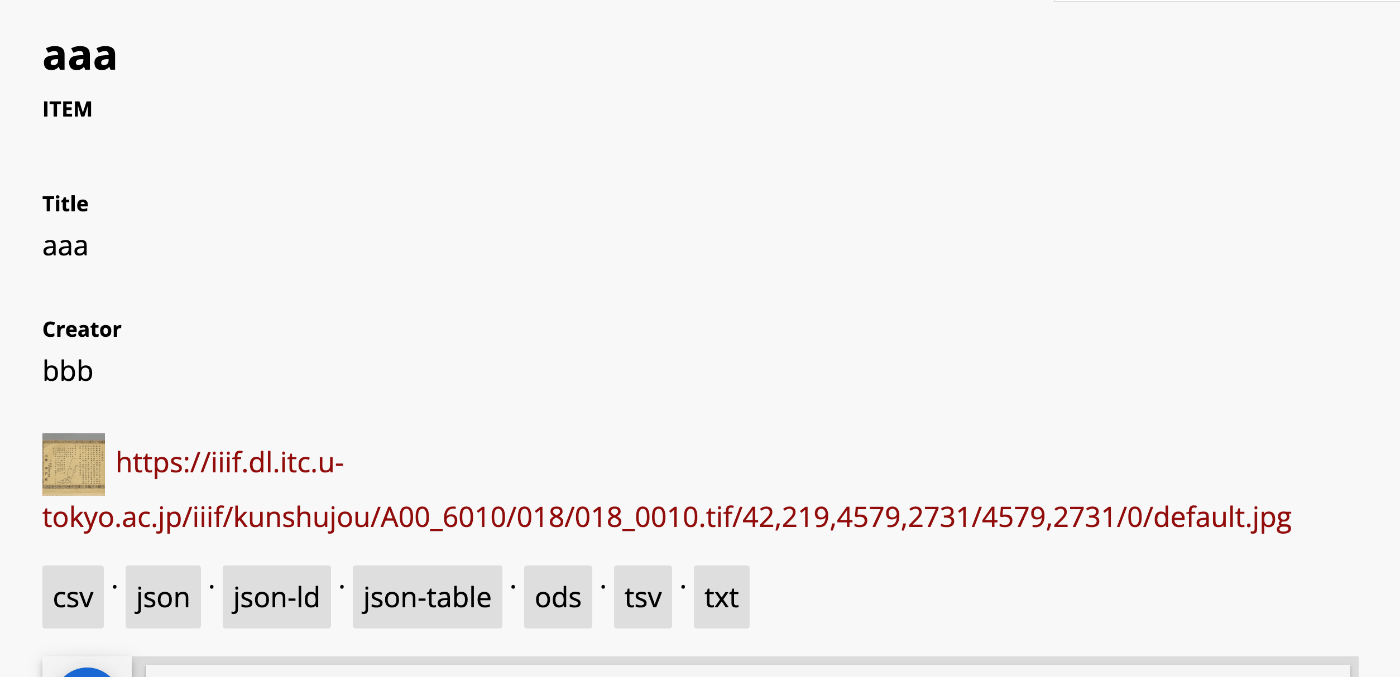
概要 以下の記事で、エクスポート機能を追加する方法を紹介しました。 そのエクスポート方法の一つとして、JSON-LDがあります。 今回は、このJSON-LDをRDF/XMLやTurtleに変換してみます。 使用するツール 今回は、以下のEASY RDFを使用します。 https://www.easyrdf.org/converter 先のOmeka Sのエクスポートによって得られる以下のJSON-LDの内容をコピーします。 { "@context": "https://omekas.aws.ldas.jp/xxx/omekas/api-context", "@id": "https://omekas.aws.ldas.jp/xxx/omekas/api/items/12", "@type": "o:Item", "o:id": 12, "o:is_public": true, "o:owner": { "@id": "https://omekas.aws.ldas.jp/xxx/omekas/api/users/1", "o:id": 1 }, "o:resource_class": null, "o:resource_template": null, "o:thumbnail": null, "o:title": "aaa", "thumbnail_display_urls": { "large": "https://omekas.aws.ldas.jp/xxx/omekas/files/large/4f57960c4471c954c6d3aac0a23bd441a6f4eb8b.jpg", "medium": "https://omekas.aws.ldas.jp/xxx/omekas/files/medium/4f57960c4471c954c6d3aac0a23bd441a6f4eb8b.jpg", "square": "https://omekas.aws.ldas.jp/xxx/omekas/files/square/4f57960c4471c954c6d3aac0a23bd441a6f4eb8b.jpg" }, "o:created": { "@value": "2023-07-26T22:52:31+00:00", "@type": "http://www.w3.org/2001/XMLSchema#dateTime" }, "o:modified": { "@value": "2023-10-17T06:56:16+00:00", "@type": "http://www.w3.org/2001/XMLSchema#dateTime" }, "o:media": [ { "@id": "https://omekas.aws.ldas.jp/xxx/omekas/api/media/13", "o:id": 13 } ], "o:item_set": [], "o:site": [ { "@id": "https://omekas.aws.ldas.jp/xxx/omekas/api/sites/1", "o:id": 1 } ], "dcterms:title": [ { "type": "literal", "property_id": 1, "property_label": "Title", "is_public": true, "@value": "aaa" } ], "dcterms:creator": [ { "type": "literal", "property_id": 2, "property_label": "Creator", "is_public": true, "@value": "bbb" } ] } そして、EASY RDFのInput Dataのフォームに貼り付けます。 ...

概要 BulkExportモジュールについて、以下の記事で、データを一括エクスポートする方法を紹介しました。 本モジュールではアイテムの詳細画面にエクスポートボタンを表示する機能も提供されています。この機能の使い方について紹介します。 使い方 インストールの方法は一般的なモジュールの方法と同様です。上記の記事でも簡単に説明しています。 モジュールを有効化すると、以下のように、アイテムの詳細画面に各種フォーマットでのエクスポートリンクが表示されます。 表示する項目は、サイトごとの設定画面で変更できます。設定画面には以下のようにアクセスします。 設定画面で下のほうにスクロールすると、Bulk Exportに関する設定画面が表示され、Formatters to display in resource pagesなどの項目で設定を変更することができます。 エクスポートリンクの見た目を変更する ここではエクスポートリンクの見た目を変更する方法について説明します。本来は新たなテーマを作成して、本モジュール用のファイルを作成すべきですが、今回はdefaultのテーマを使用します。 defaultのテーマは、以下のような場所にあります。 {Omeka Sのインストールディレクトリ}/themes/default まず、このdefaultテーマの中に、BulkExportモジュールのファイルのコピーします。例えば以下です。 cd {Omeka Sのインストールディレクトリ} mkdir themes/default/view/common cp modules/BulkExport/view/common/bulk-export.phtml themes/default/view/common バージョンによって内容は異なるかと思いますが、bulk-export.phtmlは以下のような内容になっています。 // Fake or invisible ids or no exporters. if (!count($urls)) return; $plugins = $this->getHelperPluginManager(); $url = $plugins->get('url'); $escape = $plugins->get('escapeHtml'); $assetUrl = $plugins->get('assetUrl'); $translate = $plugins->get('translate'); $escapeAttr = $plugins->get('escapeHtmlAttr'); $route = $this->status()->isAdminRequest() ? 'admin/resource-output' : 'site/resource-output'; $this->headLink()->appendStylesheet($assetUrl('css/bulk-export.css', 'BulkExport')); ?> <div class="bulk-export <?= $divclass ?>"> <?php if ($heading): ?> <h4><?= $escape($heading) ?></h4> <?php endif; ?> <ul class="exporters"> <?php foreach ($exporters as $format => $label): $labelFormat = in_array($format, ['ods', 'xlsx', 'xls']) ? sprintf($translate('Download as spreadsheet %s'), $label) : (in_array($format, ['bib.txt', 'bib.odt']) ? $translate('Download as text') : sprintf($translate('Download as %s'), $label)); ?> <li><a download="download" class="exporter download-<?= str_replace('.', '-', $format) ?>" href="<?= $escapeAttr($urls[$format ]) ?>" title="<?= $escapeAttr($labelFormat) ?>"><?= $label ?></a></li> <?php endforeach; ?> </ul> </div> ここで、aタグの内容をボタンに変更してみます。 ...
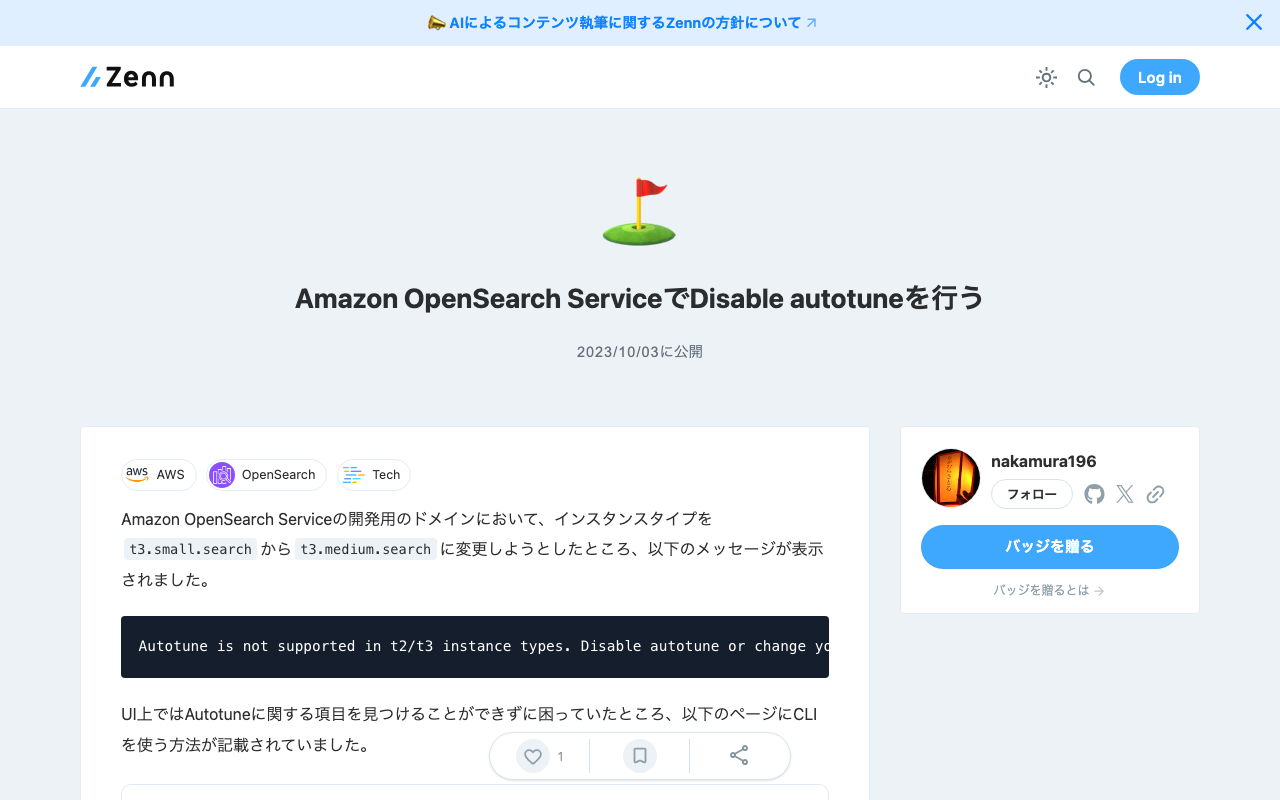
Amazon OpenSearch Serviceの開発用のドメインにおいて、インスタンスタイプをt3.small.searchからt3.medium.searchに変更しようとしたところ、以下のメッセージが表示されました。 Autotune is not supported in t2/t3 instance types. Disable autotune or change your instance type. UI上ではAutotuneに関する項目を見つけることができずに困っていたところ、以下のページにCLIを使う方法が記載されていました。 https://docs.aws.amazon.com/opensearch-service/latest/developerguide/auto-tune.html#auto-tune-enable そこで、以下を実行しました。 aws opensearch update-domain-config \ --domain-name my-domain \ --auto-tune-options DesiredState=DISABLED その上で、再度インスタンスタイプを変更したところ、無事に変更することができました。 Autotuneの機能を無効化する、または使用しないことのデメリットなどを十分に把握できていませんが、同様のことでお困りの方の参考になりましたら幸いです。
以下のサイトを参考に、Landoを使ってDrupalの開発環境を用意しました。 https://www.acquia.com/jp/blog/how-to-use-lando-for-building-drupal-local-environment そこにdrushをインストールするにあたり、以下が参考になりました。 https://docs.lando.dev/drupal/getting-started.html#quick-start 以下を実行することで、drushが使えるようになりました。 # Install a site local drush lando composer require drush/drush 他の方の参考になりましたら幸いです。
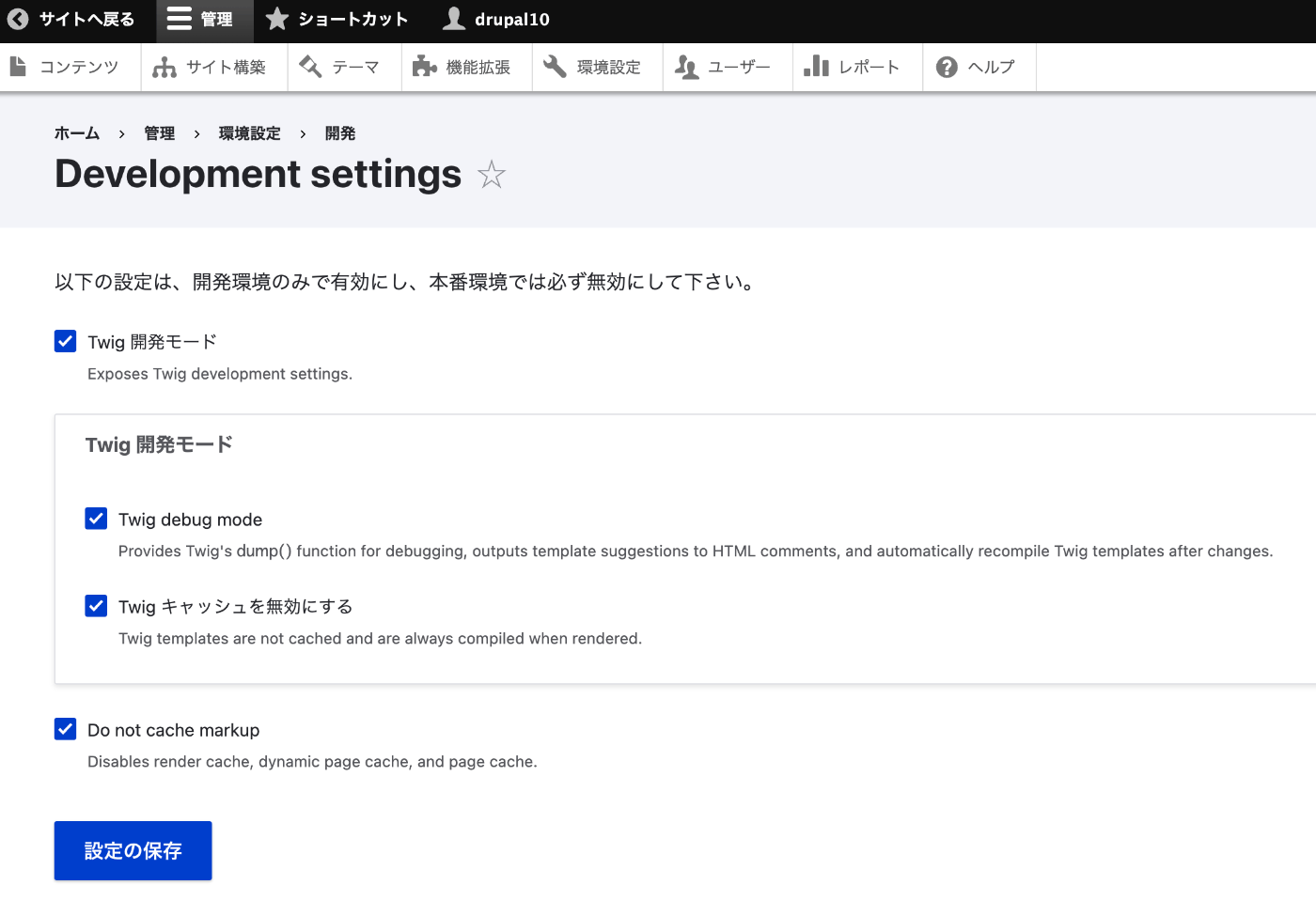
以下に記載がありました。 https://www.drupal.org/docs/develop/development-tools/disable-caching#s-disabling-twig-caching-the-easy-way 以下にアクセスします。 /admin/config/development/settings 以下の画面でチェックを入れることで、キャッシュを無効化できました。 他の方の参考になりましたら幸いです。
はじめに 以下の記事で、EC2にArchivematicaを立てる方法を記載しました。 今回は、独自ドメインの設定とHTTPS対応を行います。 独自ドメインの設定 今回、matica.aws.ldas.jpとstorage.aws.ldas.jpいうドメインを<IPアドレス>に割り当てます。Route 53を使用します。 SSL証明書の取得 sudo su yum install epel-release yum install certbot ertbot certonly --webroot -w /usr/share/nginx/html -d matica.aws.ldas.jp -d storage.aws.ldas.jp Webサーバの設定: Nginxのインストール vi /etc/nginx/conf.d/archivematica-and-storage.conf 設定 server { listen 80; server_name matica.aws.ldas.jp; rewrite ^(.*)$ https://$host$1 permanent; } server { listen 80; server_name storage.aws.ldas.jp; rewrite ^(.*)$ https://$host$1 permanent; } server { listen 443 ssl; server_name matica.aws.ldas.jp; ssl_certificate /etc/letsencrypt/live/matica.aws.ldas.jp/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/matica.aws.ldas.jp/privkey.pem; location / { proxy_pass http://localhost:81; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } server { listen 443 ssl; server_name storage.aws.ldas.jp; ssl_certificate /etc/letsencrypt/live/storage.aws.ldas.jp/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/storage.aws.ldas.jp/privkey.pem; location / { proxy_pass http://localhost:8001; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } 結果、以下のURLにアクセスできるようになりました。 ...
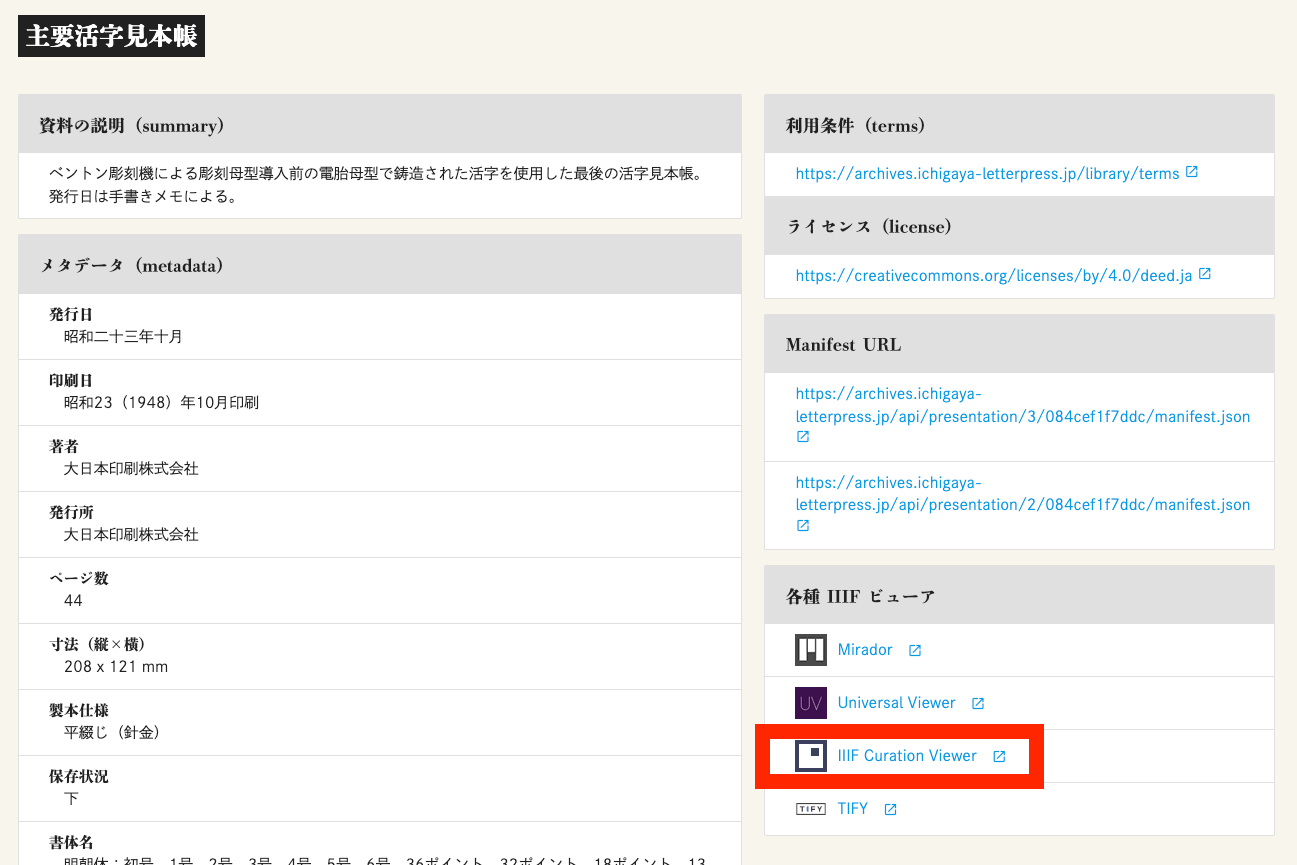
概要 IIIF Content State APIを試す機会がありましたので、その備忘録です。 https://iiif.io/api/content-state/1.0/ IIIF Content State APIはカレントアウェアネス-Rで以下のように説明されています。 “IIIF Content State API”は、回転角度やページ画像上の表示箇所等、オブジェクトの表示を詳細に指定したリンクを生成できると述べられています。 https://current.ndl.go.jp/car/45832 試す 「秀英体・活版印刷デジタルライブラリー」がIIIF Content State APIを提供してくださっています。 https://archives.ichigaya-letterpress.jp/library/ 以下に記載があります。 https://archives.ichigaya-letterpress.jp/library/help 以下、利用例について説明します。 アイテムの詳細画面 例えば、以下のページにアクセスします。 https://archives.ichigaya-letterpress.jp/library/items/084cef1f7ddc そして、IIIF Curation Viewerへのリンクをクリックします。 矩形の選択 IIIF Curation Viewerを使って、矩形を選択します。 IIIF Curation Viewerの使い方については、以下を参考にしてください。 http://ch-suzuki.com/icpt/index.html 少し手順を省きますが、以下の情報を取得できます。 https://archives.ichigaya-letterpress.jp/api/presentation/2/084cef1f7ddc/canvas/2#xywh=2148,813,312,304 上記は以下の形式になっています。 <資料のキャンバスURI>#xywh=<画像のX座標>,<画像のY座標>,<画像の幅>,<画像の高さ> base64エンコード 例えば、以下のサイトにアクセスします。 https://www.base64encode.org/ そして、先に取得した情報と当該アイテムのマニフェストURIを使って、以下のJSONをエンコードします。 { "id": "https://archives.ichigaya-letterpress.jp/api/presentation/2/084cef1f7ddc/canvas/2#xywh=2148,813,312,304", "type": "Canvas", "partOf": [{ "id": "https://archives.ichigaya-letterpress.jp/api/presentation/2/084cef1f7ddc/manifest.json", "type": "Manifest" }] } 結果、以下の文字列が得られます。 ewogICAgImlkIjogImh0dHBzOi8vYXJjaGl2ZXMuaWNoaWdheWEtbGV0dGVycHJlc3MuanAvYXBpL3ByZXNlbnRhdGlvbi8yLzA4NGNlZjFmN2RkYy9jYW52YXMvMiN4eXdoPTIxNDgsODEzLDMxMiwzMDQiLAogICAgInR5cGUiOiAiQ2FudmFzIiwKICAgICJwYXJ0T2YiOiBbewogICAgICAgICJpZCI6ICJodHRwczovL2FyY2hpdmVzLmljaGlnYXlhLWxldHRlcnByZXNzLmpwL2FwaS9wcmVzZW50YXRpb24vMi8wODRjZWYxZjdkZGMvbWFuaWZlc3QuanNvbiIsCiAgICAgICAgInR5cGUiOiAiTWFuaWZlc3QiCiAgICB9XQp9 エンドポイントURLにアクセス 上記の文字列を使って、以下のURLにアクセスしてみます。 https://archives.ichigaya-letterpress.jp/library/items/084cef1f7ddc?target=ewogICAgImlkIjogImh0dHBzOi8vYXJjaGl2ZXMuaWNoaWdheWEtbGV0dGVycHJlc3MuanAvYXBpL3ByZXNlbnRhdGlvbi8yLzA4NGNlZjFmN2RkYy9jYW52YXMvMiN4eXdoPTIxNDgsODEzLDMxMiwzMDQiLAogICAgInR5cGUiOiAiQ2FudmFzIiwKICAgICJwYXJ0T2YiOiBbewogICAgICAgICJpZCI6ICJodHRwczovL2FyY2hpdmVzLmljaGlnYXlhLWxldHRlcnByZXNzLmpwL2FwaS9wcmVzZW50YXRpb24vMi8wODRjZWYxZjdkZGMvbWFuaWZlc3QuanNvbiIsCiAgICAgICAgInR5cGUiOiAiTWFuaWZlc3QiCiAgICB9XQp9 結果、以下のページにアクセスできます。 まとめ IIIF Content State APIの目的の通り、オブジェクトの表示を詳細に指定したリンクを作成することができました。 リンクの作成については、より効率的な方法があるかと思いますが、参考になりましたら幸いです。 ...
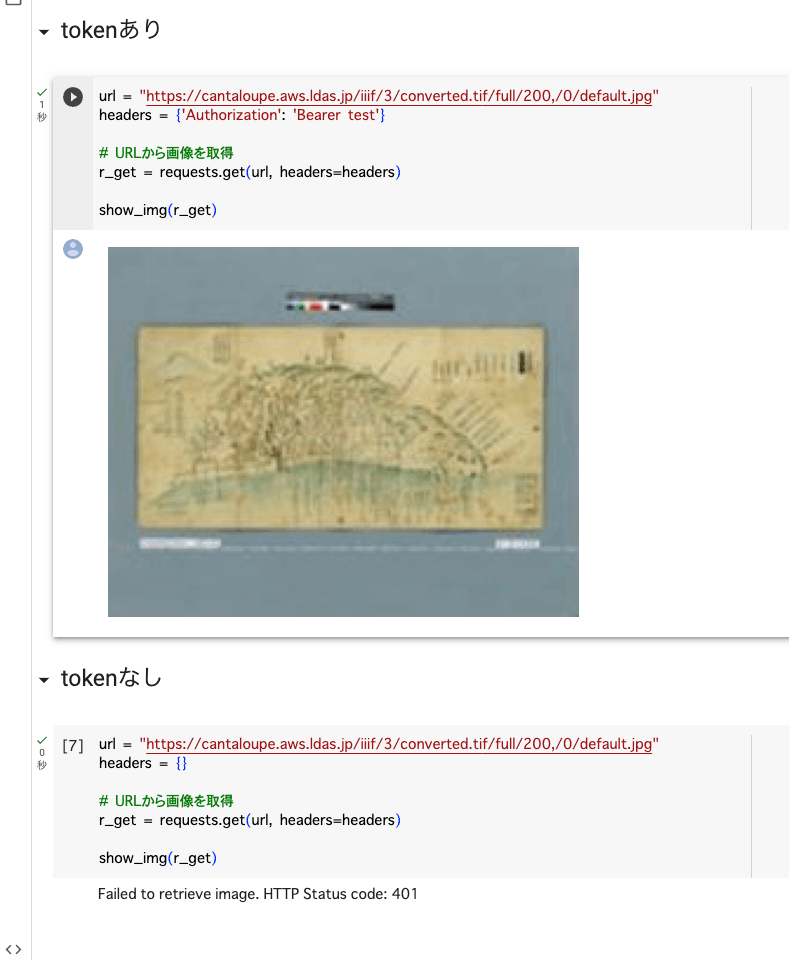
概要 CantaloupeのAccess Controlを試しましたので、備忘録です。 https://cantaloupe-project.github.io/manual/5.0/access-control.html Bearer認証 以下を参考にしました。 https://cantaloupe-project.github.io/manual/5.0/access-control.html#Tiered Access All or Nothing Access 認証情報が間違っている場合には、エラーを返却するものです。 以下のように、tokenがtestの場合は返却するようにしました。 def authorize(options = {}) header = context['request_headers'] .select{ |name, value| name.downcase == 'authorization' } .values.first if header&.start_with?('Bearer ') token = header[7..header.length - 1] if token == "test" return true end end return { 'status_code' => 401, 'challenge' => 'Bearer charset="UTF-8"' } end 上記の挙動を確認するGoogle Colabを作成しました。 https://colab.research.google.com/github/nakamura196/000_tools/blob/main/Cantaloupeのaccess_controlのテスト.ipynb 実行した結果、以下のように、tokenが正しい場合は画像を取得でき、間違っている、または提供されていない場合には画像を取得できません。 Login with degraded access for unauthed users iiif-auth-serverでは、未認証ユーザ向けに権限を制限したログイン、という例が提供されており、それをCantaloupeで再現してみます。 https://github.com/digirati-co-uk/iiif-auth-server 具体的には、認証情報が間違っている場合には、グレースケールの画像を返却します。誤っている点もあるかもしれませんが、以下のようなスクリプトを用意しました。 def authorize(options = {}) header = context['request_headers'].find { |name, value| name.downcase == 'authorization' }&.last request_uri = context['request_uri'] filename, extension = extract_filename_and_extension(request_uri) return true if filename == "gray" if header&.start_with?('Bearer ') token = header[7..-1] return true if token == "test" end { 'status_code' => 302, 'location' => "#{request_uri.sub(filename + extension, "gray#{extension}")}" } end def extract_filename_and_extension(uri_str) uri = URI.parse(uri_str) filename_with_extension = uri.path.split("/").last filename = File.basename(filename_with_extension, ".*") # Use ".*" to remove any extension extension = File.extname(filename_with_extension) [filename, extension] end Google Colabの実行結果は以下です。未認証ユーザにはグレースケールの画像が返却され、認証ユーザにはカラー画像が返却されます。 ...