Recogitoを用いたテキストアノテーションを試す
概要 Recogitoを用いたテキストアノテーションを試す機会がありましたので、備忘録です。
Recogitoは以下です。
https://recogito.pelagios.org/
以下のように説明されています。
Semantic Annotation without the pointy brackets. Recogito is an annotation tool for texts and images - not just for Digital Humanities scholars.
(機械翻訳)タグを使わないセマンティックアノテーション。デジタル人文学の研究者だけでなく、誰でも使えるテキストと画像のアノテーションツール
サンプルデータ 国立国会図書館が公開する以下を例とします。
https://dl.ndl.go.jp/pid/2585164/1/1
使い方 Recogitoにアクセスし、画面右上の「ログイン」ボタンからログインします。
ログイン後、画面左部の「New」ボタンを押し、「From IIIF manifest」を選択します。
今回、サンプルデータとして使用する以下のマニフェストファイルを入力します。
https://dl.ndl.go.jp/api/iiif/2585164/manifest.json
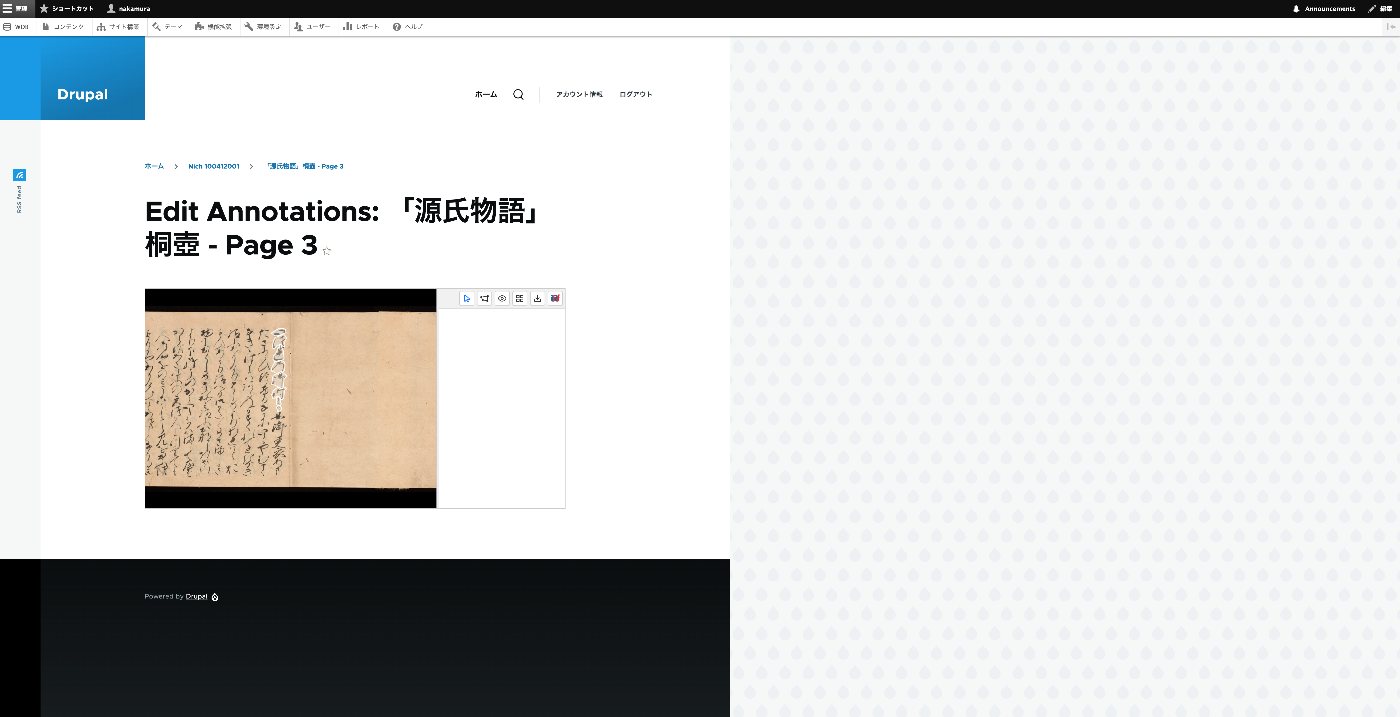
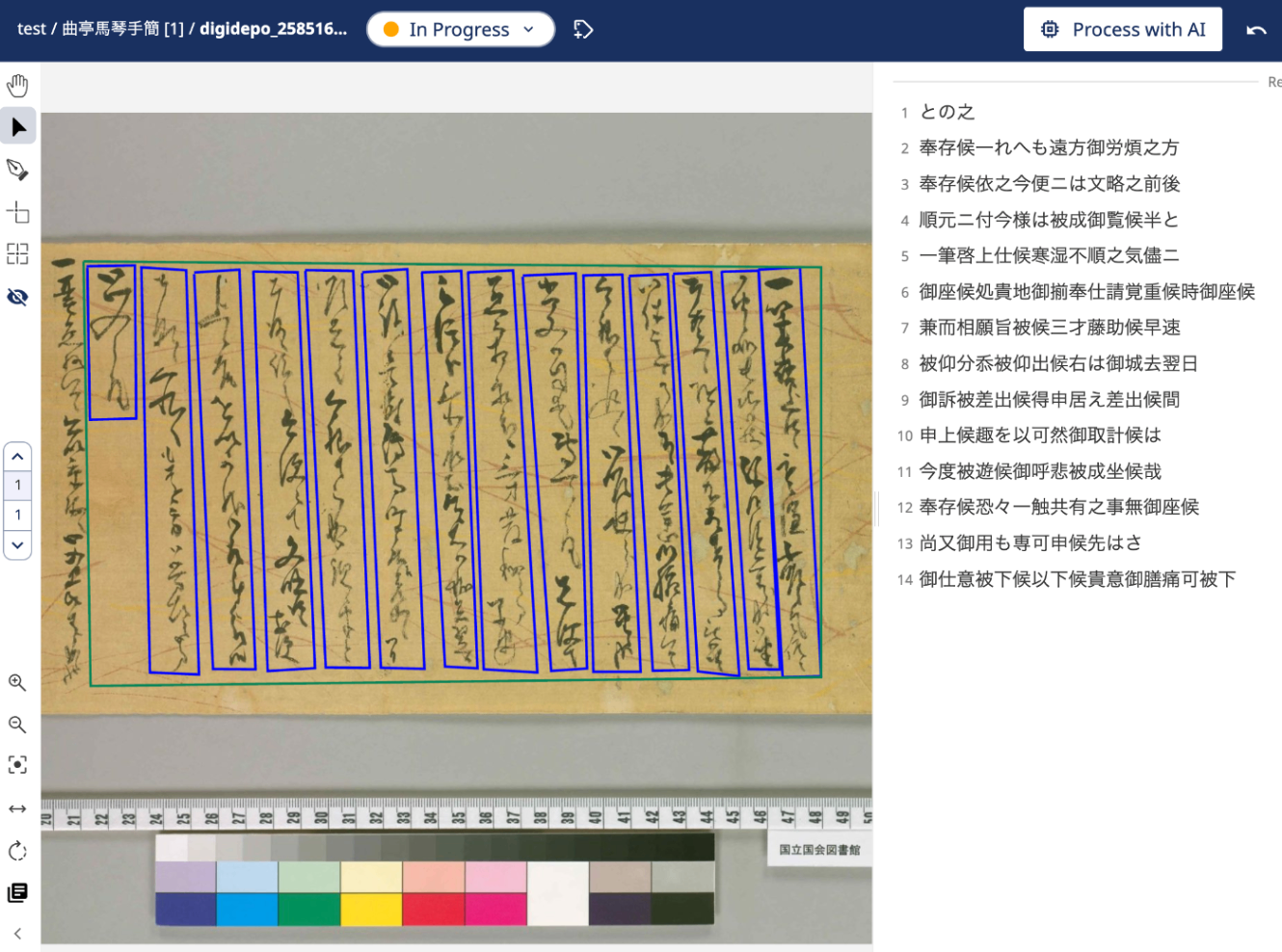
以下のように、編集画面に遷移します。
その後、矩形を作成し、「Transcribe…」の箇所にテキストを入力します。
ダウンロード 画面上部のダウンロードアイコンから、各種フォーマットでエクスポートすることができます。
JSON-LDフォーマットでダウンロードした結果は以下です。Open Annotationに形式でエクスポートされました。
[ { "@context": "http://www.w3.org/ns/anno.jsonld", "id": "https://recogito.pelagios.org/annotation/82be9a93-332b-4731-a9a4-5df8359eb197", "type": "Annotation", "generator": { "id": "https://recogito.pelagios.org/", "type": "Software", "name": "Recogito", "homepage": "https://recogito.pelagios.org/" }, "generated": "2025-07-23T06:23:59+00:00", "body": [ { "type": "TextualBody", "value": "御座候処貴地御揃奉仕請覚重候時御座候", "creator": "https://recogito.pelagios.org/satoru196", "modified": "2025-07-23T06:15:01+00:00", "purpose": "transcribing" } ], "target": { "source": "https://dl.ndl.go.jp/api/iiif/2585164/R0000005", "type": "Image", "label": "5", "selector": [ { "type": "FragmentSelector", "conformsTo": "http://www.w3.org/TR/media-frags/", "value": "xywh=pixel:4103,883,341,2385" } ] } }, { "@context": "http://www.w3.org/ns/anno.jsonld", "id": "https://recogito.pelagios.org/annotation/caaa671f-79da-4a19-bc93-42a5502b4efa", "type": "Annotation", "generator": { "id": "https://recogito.pelagios.org/", "type": "Software", "name": "Recogito", "homepage": "https://recogito.pelagios.org/" }, "generated": "2025-07-23T06:23:59+00:00", "body": [ { "type": "TextualBody", "value": "一筆啓上仕候寒湿不順之気儘ニ", "creator": "https://recogito.pelagios.org/satoru196", "modified": "2025-07-23T06:12:45+00:00", "purpose": "transcribing" } ], "target": { "source": "https://dl.ndl.go.jp/api/iiif/2585164/R0000005", "type": "Image", "label": "5", "selector": [ { "type": "FragmentSelector", "conformsTo": "http://www.w3.org/TR/media-frags/", "value": "xywh=pixel:4319,901,360,2377" } ] } } ] まとめ Recogitoを用いたテキストアノテーションにあたり、参考になりましたら幸いです。
...
2025年7月24日 · 更新: 2025年7月24日 · 1 分 · Nakamura