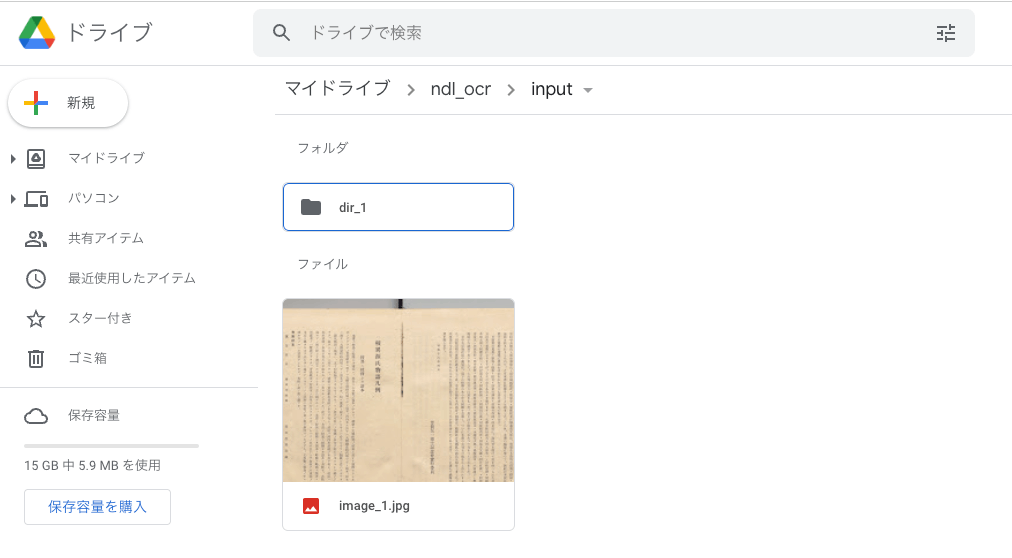
Google Colabを用いたndl-lab図表自動抽出プログラムの実行
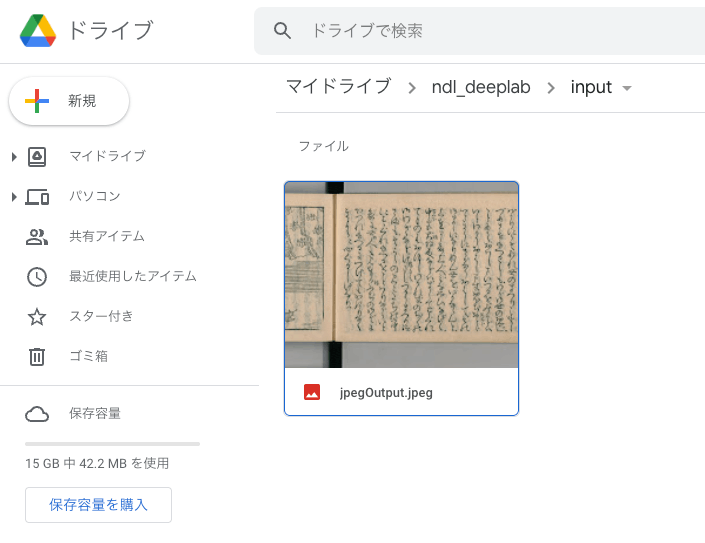
概要 ndl-labでは、以下の図表自動抽出プログラムが公開されています。 https://github.com/ndl-lab/tensorflow-deeplab-v3-plus 今回は上記のプログラムについて、Google Driveを用いた画像の入力と結果の保存までの手続きを含むGoogle Colabの使用方法をまとめましたので紹介します。 ノートブック 今回作成したGoogle Colabのノートブックには以下からアクセスいただけます。 https://colab.research.google.com/github/nakamura196/ndl_ocr/blob/main/ndl_deeplab.ipynb Googleドライブ上に入力画像のフォルダを用意することで、図表の自動抽出処理を実行することができます。 基本的な操作方法は、上記のノートブック内の説明をご確認ください。以下、実行例を紹介します。 本ノートブックでは、(1)入力フォルダを準備する方法と、(2)IIIFマニフェストファイルのURLを入力する方法の2つがあります。それぞれについて説明します。 実行方法:(1)入力フォルダの準備 入力フォルダの準備 まず、Google Drive上に画像ファイルを格納したフォルダを作成します。今回は、以下のように、マイドライブに「ndl_deeplab > input」というフォルダを作成して、その直下に画像ファイルを格納しました。 ノートブックの実行:1.初期セットアップ 先に示した以下のノートブックにアクセスしてください。 https://colab.research.google.com/github/nakamura196/ndl_ocr/blob/main/ndl_deeplab.ipynb そして、用意されている2つの再生ボタンを押してください。少し時間がかかりますが、必要なライブラリ等をインストールします。また、本作業については、ノートブック立ち上げ後の初回のみ実行します。 ノートブックの実行:2.設定 次に、処理の適用対象を設定します。以下のように、input_dirに先に用意したフォルダへのパスを指定します。またmanifestの値を空にしてください。これにより、input_dirに格納した画像ファイルを対象に処理を実行します。 再生ボタンを押して、設定は完了です。 ノートブックの実行:3.実行 「3.実行」の再生ボタンを押してください。 完了後は、以下のように、指定した出力フォルダに処理の開始時間に基づくフォルダが作成され、その中に認識結果が保存されます。 図表の抽出に失敗してしまう場合もありますが、今回は以下のように、正しく図表を抽出することができました。 実行方法:(2)IIIFマニフェストファイルのURLを入力する ノートブックの実行:1.初期セットアップ これは先ほどのプロセスと同じです。2回目以降はスキップしてください。 ノートブックの実行:2.設定 以下のように、manifestに処理対象とするIIIFマニフェストファイルのURLを入力してください。 またprocess_sizeに処理対象のcanvas数を指定します。-1を入力すると、マニフェストファイルに含まれるすべてのcanvas(画像)に対して処理を実行します。 再生ボタンを押して、設定は完了です。 ノートブックの実行:3.実行 「3.実行」の再生ボタンを押してください。 今回の場合、以下のように、まず画像のダウンロードが行われます。 ### マニフェストが指定されている場合は、画像のダウンロード ### 80%|████████ | 4/5 [00:13<00:03, 3.41s/it] その後、抽出処理が始まります。処理対象の画像が多い場合、完了まで時間がかかります。 抽出処理の完了後、「実行方法:(1)入力フォルダの準備」で示した通り、指定したGoogleドライブ上の出力フォルダに認識結果が保存されるほか、以下のように、認識結果をIIIFマニフェストファイルの形で出力し、それをMiradorビューアで閲覧するためのURLが表示されます。 ### マニフェストが指定されている場合は、認識結果をマニフェストファイルに出力 ### /content/drive/MyDrive/ndl_deeplab/output/20220429095851/manifest.json にマニフェストファイルを保存しました。 また以下のリンクから、認識結果を確認できます。 https://localhost:8000/ 上記のリンクをクリックすると、以下のように、Miradorを用いて認識結果を確認することができます。 まとめ 今回は、NDLラボが公開する図表自動抽出プログラムについて、Google Colabを用いた実行方法の一例を示しました。他の方の参考になりましたら幸いです。 このようなアプリケーションを公開してくださったNDLの関係者の方々に深く感謝いたします。