TEI/XMLファイルを縦書きPDFに変換する方法の1例
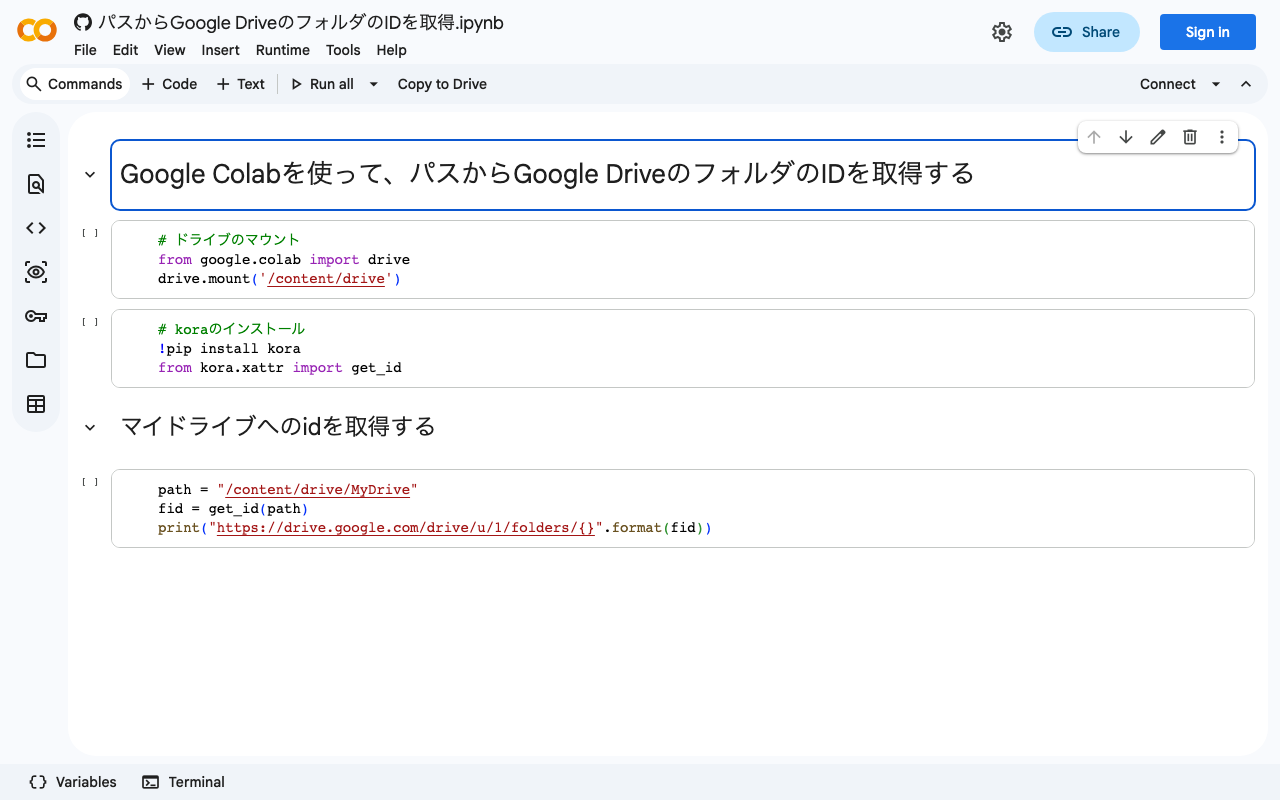
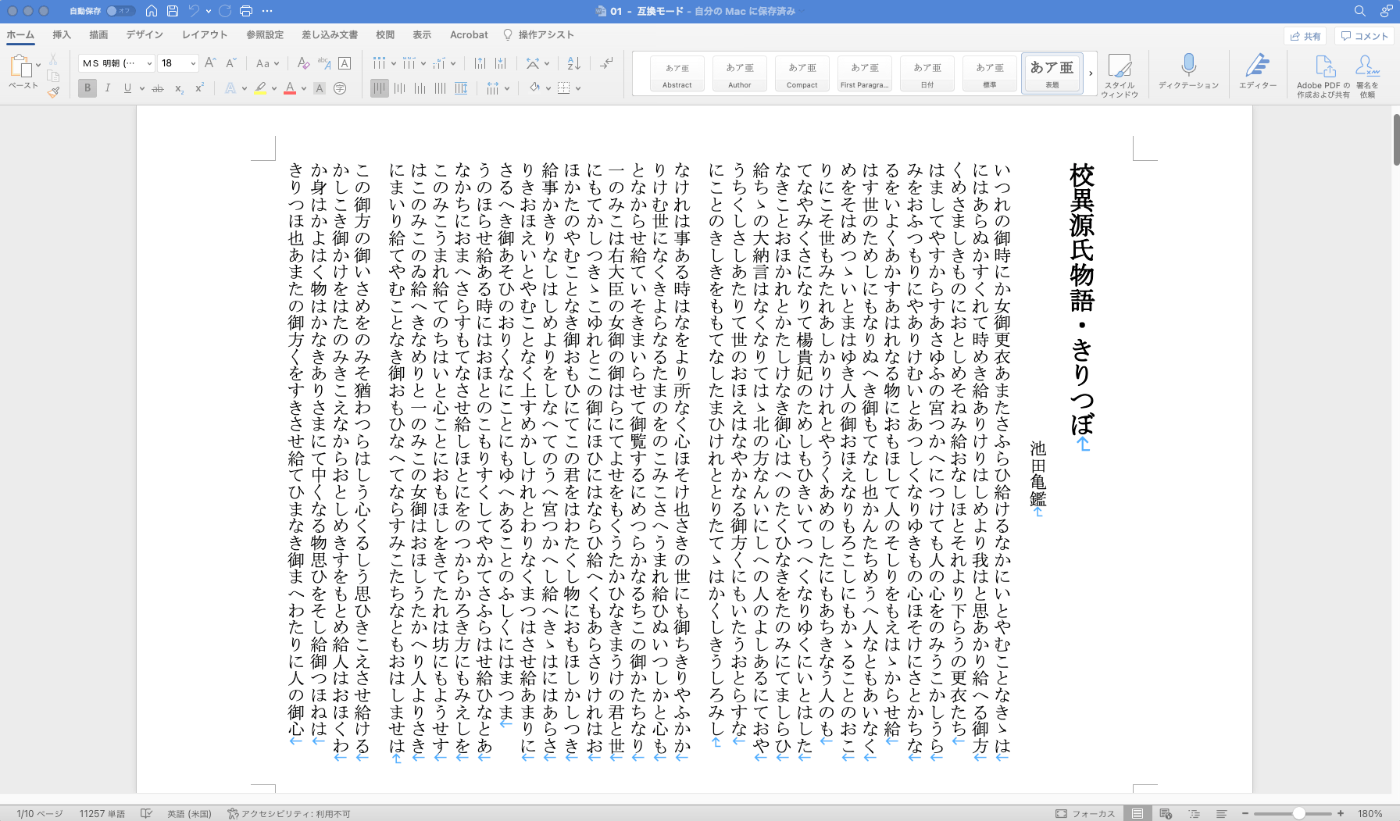
概要 TEI/XMLファイルを縦書きPDFに変換する方法について、その1例を備忘録として残します。 以下のノートブックで、「校異源氏物語」を対象としたプログラムをお試しいただけます。 https://colab.research.google.com/github/nakamura196/ndl_ocr/blob/main/TEI_XMLファイルを縦書きPDFに変換する.ipynb 変換の流れ 今回は、Quartoを使用しています。 https://quarto.org/ インストールの方法は以下を参考にしてください。 https://quarto.org/docs/get-started/ TEI/XML -> qmd まずTEI/XMLファイルの内容をqmdファイルに変換します。以下は、変換スクリプトのサンプルです。 from bs4 import BeautifulSoup soup = BeautifulSoup(open(file,'r'), "xml") elements = soup.findChildren(text=True, recursive=True) import os id = os.path.splitext(os.path.basename(file))[0] title = soup.find("title").text author = soup.find("author").text elements = soup.find("body").find("p").findChildren() text = "" for e in elements: if e.name == "pb": text += "\n" if e.name == "seg": text += e.text + " \n" opath = f"data/{id}.qmd" os.makedirs(os.path.dirname(opath), exist_ok=True) text = f"""--- title: "{title}" author: "{author}" format: docx: reference-doc: /content/kouigenjimonogatari/tools/genji-doc-style.docx --- {text.strip()} """ with open(opath, "w") as f: f.write(text) 以下がqmdファイルの例です。 --- title: "校異源氏物語・きりつぼ" author: "池田亀鑑" format: docx: reference-doc: /content/kouigenjimonogatari/tools/genji-doc-style.docx --- いつれの御時にか女御更衣あまたさふらひ給けるなかにいとやむことなきゝは にはあらぬかすくれて時めき給ありけりはしめより我はと思あかり給へる御方 〱めさましきものにおとしめそねみ給おなしほとそれより下らうの更衣たち はましてやすからすあさゆふの宮つかへにつけても人の心をのみうこかしうら みをおふつもりにやありけむいとあつしくなりゆきもの心ほそけにさとかちな るをいよ〱あかすあはれなる物におもほして人のそしりをもえはゝからせ給 はす世のためしにもなりぬへき御もてなし也かんたちめうへ人なともあいなく めをそはめつゝいとまはゆき人の御おほえなりもろこしにもかゝることのおこ りにこそ世もみたれあしかりけれとやう〱あめのしたにもあちきなう人のも てなやみくさになりて楊貴妃のためしもひきいてつへくなりゆくにいとはした なきことおほかれとかたしけなき御心はへのたくひなきをたのみにてましらひ 給ちゝの大納言はなくなりてはゝ北の方なんいにしへの人のよしあるにておや うちくしさしあたりて世のおほえはなやかなる御方〱にもいたうおとらすな にことのきしきをももてなしたまひけれととりたてゝはか〱しきうしろみし なけれは事ある時はなをより所なく心ほそけ也さきの世にも御ちきりやふかか qmd -> Word(docx) 次に、qmdファイルをwordファイルに変換します。この時、事前に用意した縦書きのwordテンプレートを参照することで、マークダウン形式のテキストを縦書きのwordファイルに変換します。 ...

![[備忘録] maptilerのlightおよびdarkテーマ](/images/articles/985847a6029c2d.png)
![[Omeka S]Bulk Importの不具合対応(ソースコードからのインストール方法を含む)](https://storage.googleapis.com/zenn-user-upload/ed7f11a15317-20220821.png)
![[RDF] URIにアクセスしたらSnorqlの画面にリダイレクトさせる設定](/images/articles/3243962c5e57d0.png)