researchmapのapiを使う
概要 researchmapのapiを使って、業績リストを作成する機会がありましたので、備忘録です。
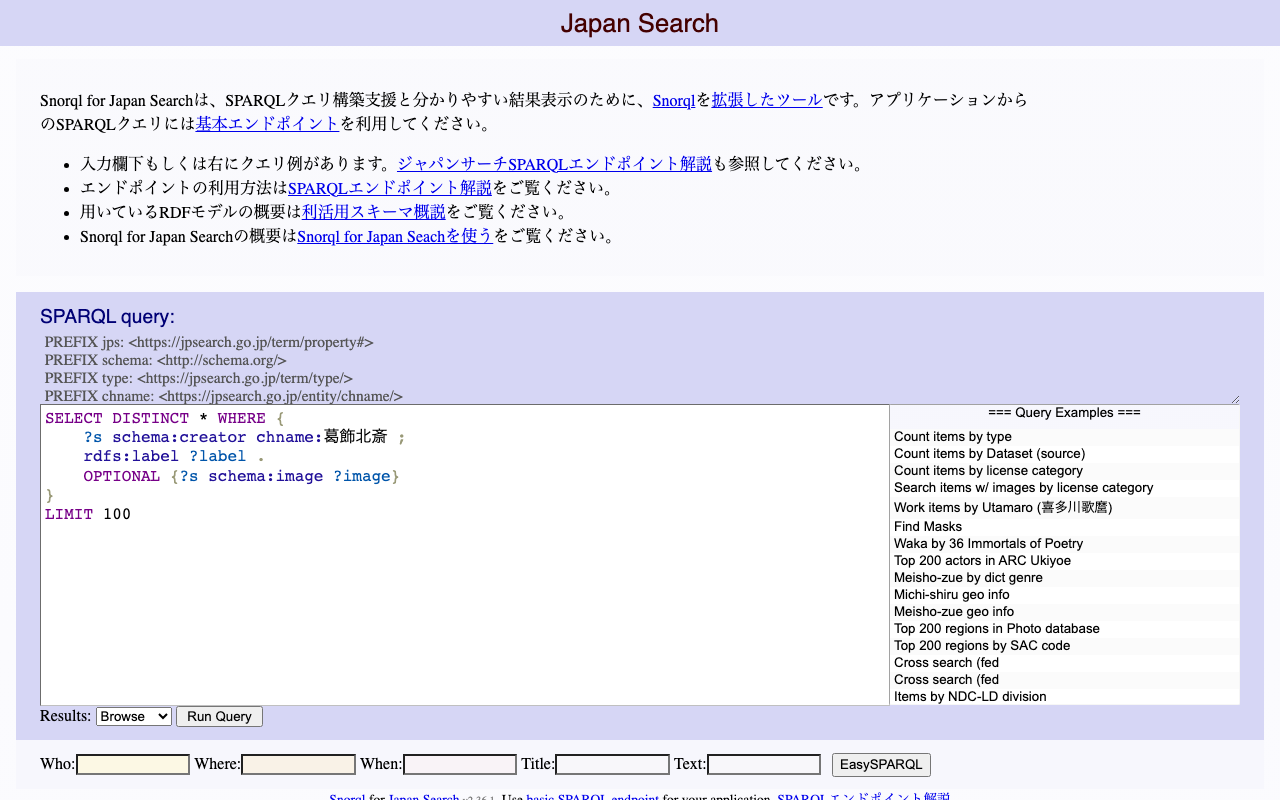
researchmapのapiに対するクエリ例 researchmapのapiに対するクエリ例をいくつか紹介します。
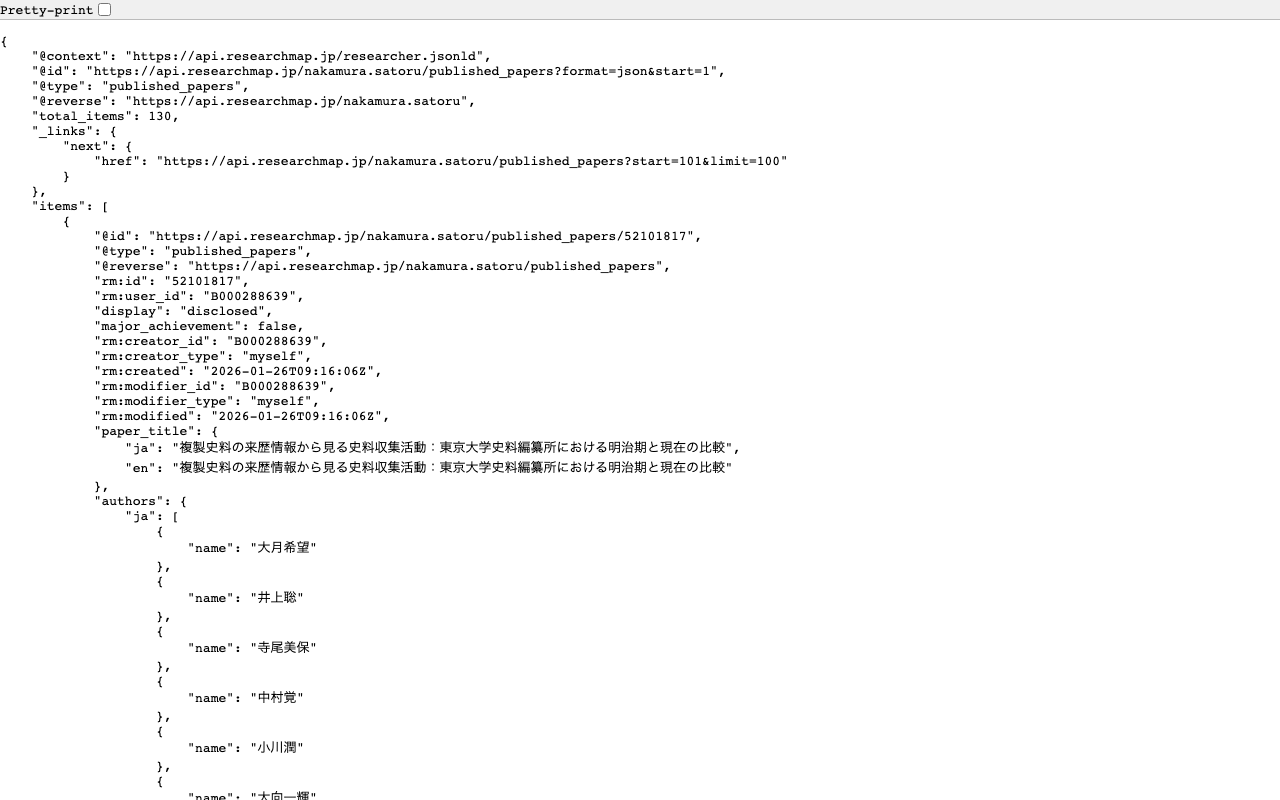
論文の一覧を取得する
https://api.researchmap.jp/nakamura.satoru/published_papers
上限を指定する(limitの使用)
https://api.researchmap.jp/nakamura.satoru/published_papers?limit=5
x件以降の結果を取得する(startの使用)
https://api.researchmap.jp/nakamura.satoru/published_papers?limit=5&start=6
出版年月日を指定する(from_dateとto_date)
https://api.researchmap.jp/nakamura.satoru/published_papers?from_date=2023-04-01&to_date=2024-03-31
Pythonでの使用例 指定したユーザと出版年月日に基づき、published_papersとpresentationsをExcelに書き出します。
#| export import requests import pandas as pd import os class Client: def __init__(self, slug, date_start, date_end): self.slug = slug self.date_start = date_start self.date_end = date_end self.output_dir = f"data/{self.slug}/{self.date_start}_{self.date_end}" os.makedirs(self.output_dir, exist_ok=True) @staticmethod def main(slug, date_start, date_end): client = Client(slug, date_start, date_end) client.process_data() def process_data(self): self.df_paper = self.fetch_data('published_papers', self.paper_processing_logic) self.df_presentation = self.fetch_data('presentations', self.presentation_processing_logic) self.write_to_excel() def fetch_data(self, data_type, processing_function): url = f"https://api.researchmap.jp/{self.slug}/{data_type}" params = { "limit": 100, "start": 0, "from_date": self.date_start, "to_date": self.date_end, } response = requests.get(url, params=params) if response.status_code == 200: data = response.json().get("items", []) return processing_function(data) else: raise Exception(f"Error fetching {data_type}: {response.status_code}") def paper_processing_logic(self, papers): rows = [] for item in papers: rows.append(self.process_paper_item(item)) return pd.DataFrame(rows) def process_paper_item(self, item): author_list = [auth["name"] for auth in item.get('authors', {}).get("ja", [])] c1 = '''1.掲載論文のDOI (デジタルオブジェクト識別子)''' c2 = '''2.著者名''' c3 = '''3.論文標題''' c4 = '''4.雑誌名''' c5 = '''5.巻 (半角数字)''' c6 = '''6.発行年 (半角数字)''' c7 = '''7.最初と最後の頁 (半角数字)''' c8 = '''8.査読の有無 (1:有 0:無)''' c9 = '''9.国際共著 (1:有 0:無)''' c10 = '''10.オープンアクセス (1:有 0:無)''' return { c1: item.get('identifiers', {}).get('doi', [None])[0], c2: ", ".join(author_list), c3: item.get('paper_title', {}).get('ja', ''), c4: item.get('publication_name', {}).get('ja', ''), c5: item.get('volume', None), c6: item['publication_date'][:4], c7: f"{item.get('starting_page', '')}-{item.get('ending_page', '')}", c8: 1 if item.get('referee', False) else 0, c9: 1 if item.get('is_international_collaboration', False) else 0, c10: 1 if item.get('rm:is_open_access', False) else 0 } def presentation_processing_logic(self, presentations): rows = [] for item in presentations: rows.append(self.process_presentation_item(item)) return pd.DataFrame(rows) def process_presentation_item(self, item): author_list = [auth["name"] for auth in item.get('presenters', {}).get("ja", [])] c1 = '''1.発表者名''' c2 = "2.発表標題" c3 = "3.学会等名" c4 = '''4.発表年(開始) (半角数字)''' c5 = '''5.発表年(終了) (半角数字)''' c6 = '''6.招待講演 (1:有 0:無)''' c7 = '''7.国際学会 (1:有 0:無)''' return { c1: ", ".join(author_list), c2: item.get('presentation_title', {}).get('ja', ''), c3: item.get('event', {}).get('ja', ''), c4: item['publication_date'][:4], c5: item['publication_date'][:4], c6: 1 if item.get('invited', False) else 0, c7: 1 if item.get('is_international_presentation', False) else 0 } def write_to_excel(self): with pd.ExcelWriter(f'{self.output_dir}/merged.xlsx', engine='openpyxl') as writer: self.df_paper.to_excel(writer, sheet_name='Papers', index=False) self.df_presentation.to_excel(writer, sheet_name='Presentations', index=False) self.df_paper.to_csv(f"{self.output_dir}/papers.csv", index=False) self.df_presentation.to_csv(f"{self.output_dir}/presentations.csv", index=False) 使用例は以下です。dataフォルダにcsvやexcelが出力されます。
...
2024年4月15日 · 更新: 2024年4月15日 · 2 分 · Nakamura