NDL古典籍OCR-Liteを用いたアノテーション付きIIIFマニフェストファイルとTEI/XMLファイルの作成
お知らせ 本記事で紹介する流れをわかりやすくした記事を作成しました。以下も参考にしてください。
概要 NDL古典籍OCR-Liteを用いたアノテーション付きIIIFマニフェストファイルとTEI/XMLファイルの作成を行うツールを試作したので紹介します。
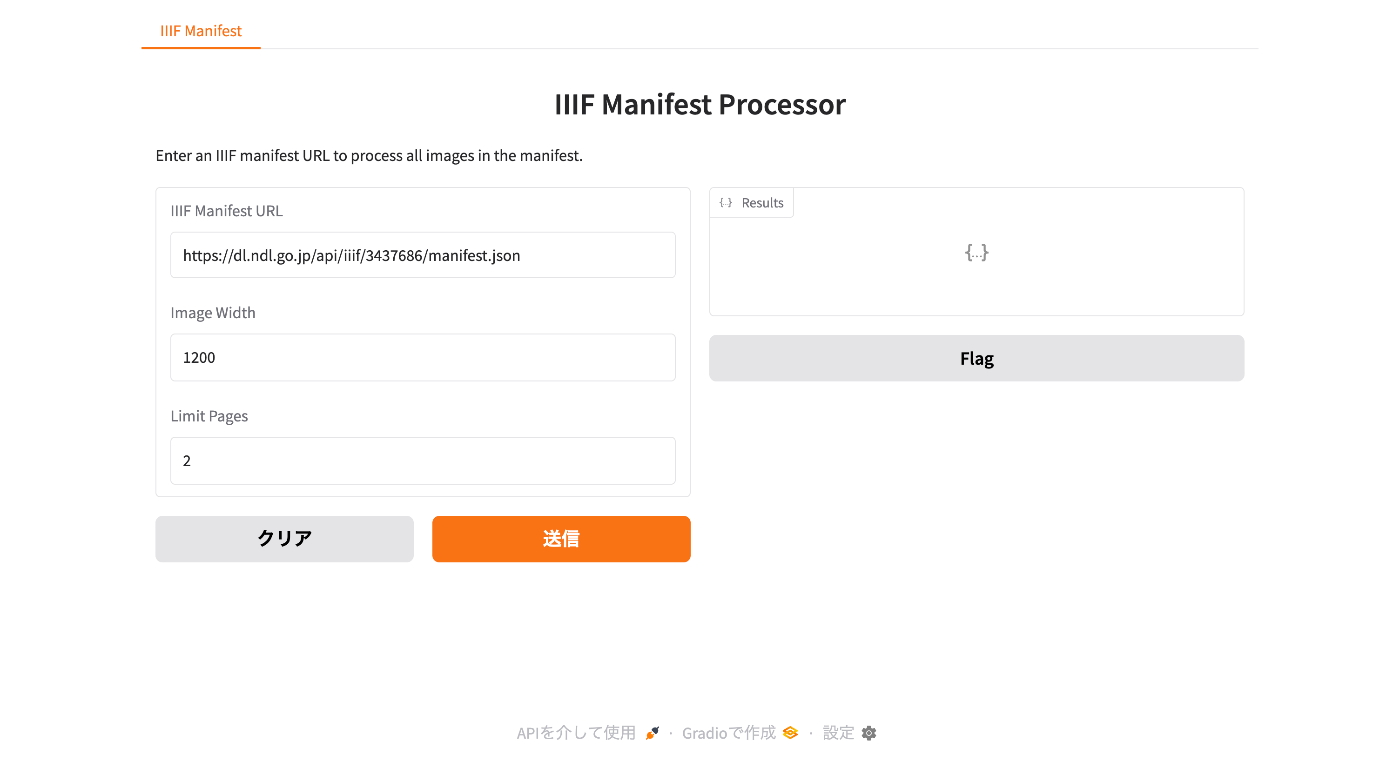
アノテーション付きIIIFマニフェストファイルの作成 まず、NDL古典籍OCR-Liteを用いて、IIIFマニフェストファイルを入力として、アノテーション付きIIIFマニフェストファイルを出力するGradioアプリを作成しました。Hugging FaceのSpaceを用いて公開しています。
https://nakamura196-ndlkotenocr-lite-iiif.hf.space/
出力結果として、以下のようなアノテーション付きIIIFマニフェストファイルが得られます。
{ "@context": "http://iiif.io/api/presentation/3/context.json", "id": "https://dl.ndl.go.jp/api/iiif/3437686/manifest.json", "type": "Manifest", "label": { "none": [ "校異源氏物語. 巻一" ] }, "items": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1", "type": "Canvas", "width": 6890, "height": 4706, "label": { "none": [ "1" ] }, "items": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/page", "type": "AnnotationPage", "items": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/page/imageanno", "type": "Annotation", "motivation": "sc:painting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1", "body": { "id": "https://dl.ndl.go.jp/api/iiif/3437686/R0000001/full/full/0/default.jpg", "type": "Image", "format": "image/jpeg", "width": 6890, "height": 4706, "service": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/R0000001", "type": "ImageService2", "profile": "level2" } ] } } ] } ], "annotations": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos", "type": "AnnotationPage", "items": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos/0", "type": "Annotation", "motivation": "commenting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1#xywh=5270,275,114,935", "body": { "type": "TextualBody", "value": "一・〇・・・・・・一一一一・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・" } }, { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos/1", "type": "Annotation", "motivation": "commenting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1#xywh=5293,2009,218,424", "body": { "type": "TextualBody", "value": "○〇" } }, { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos/2", "type": "Annotation", "motivation": "commenting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1#xywh=5092,3272,63,80", "body": { "type": "TextualBody", "value": "一一" } }, { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos/3", "type": "Annotation", "motivation": "commenting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1#xywh=4375,304,103,1475", "body": { "type": "TextualBody", "value": "ス〇〇〇六〇〇〇一〇〇〇〇〇〇〇一一一〇〇〇一一一一〇〇〇〇〇〇〇〇〇〇一一・〇〇・・・・・・・の〇〇・・・・一・・・" } }, { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos/4", "type": "Annotation", "motivation": "commenting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1#xywh=4375,2853,45,522", "body": { "type": "TextualBody", "value": "□琉球□□□□□□□□□□□□□□□□□" } }, { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos/5", "type": "Annotation", "motivation": "commenting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1#xywh=4283,2756,63,252", "body": { "type": "TextualBody", "value": "〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇〇一〇〇一〇〇〇" } }, { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annos/6", "type": "Annotation", "motivation": "commenting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1#xywh=694,499,310,2991", "body": { "type": "TextualBody", "value": "同校異源氏物巻一" } } ] } ] }, { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/2", "type": "Canvas", "width": 6890, "height": 4706, "label": { "none": [ "2" ] }, "items": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/2/page", "type": "AnnotationPage", "items": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/2/page/imageanno", "type": "Annotation", "motivation": "sc:painting", "target": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/2", "body": { "id": "https://dl.ndl.go.jp/api/iiif/3437686/R0000002/full/full/0/default.jpg", "type": "Image", "format": "image/jpeg", "width": 6890, "height": 4706, "service": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/R0000002", "type": "ImageService2", "profile": "level2" } ] } } ] } ], "annotations": [ { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/2/annos", "type": "AnnotationPage", "items": [] } ] } ] } TEI/XMLファイルの作成 上記で得られたアノテーション付きIIIFマニフェストファイルを入力として、TEI/XMLファイルを作成するライブラリを作成しました。
...
2025年5月27日 · 更新: 2025年5月27日 · 4 分 · Nakamura