Odeuropa Visualization: A Platform for Visualizing Scent Data Using SKOS Vocabularies and SPARQL
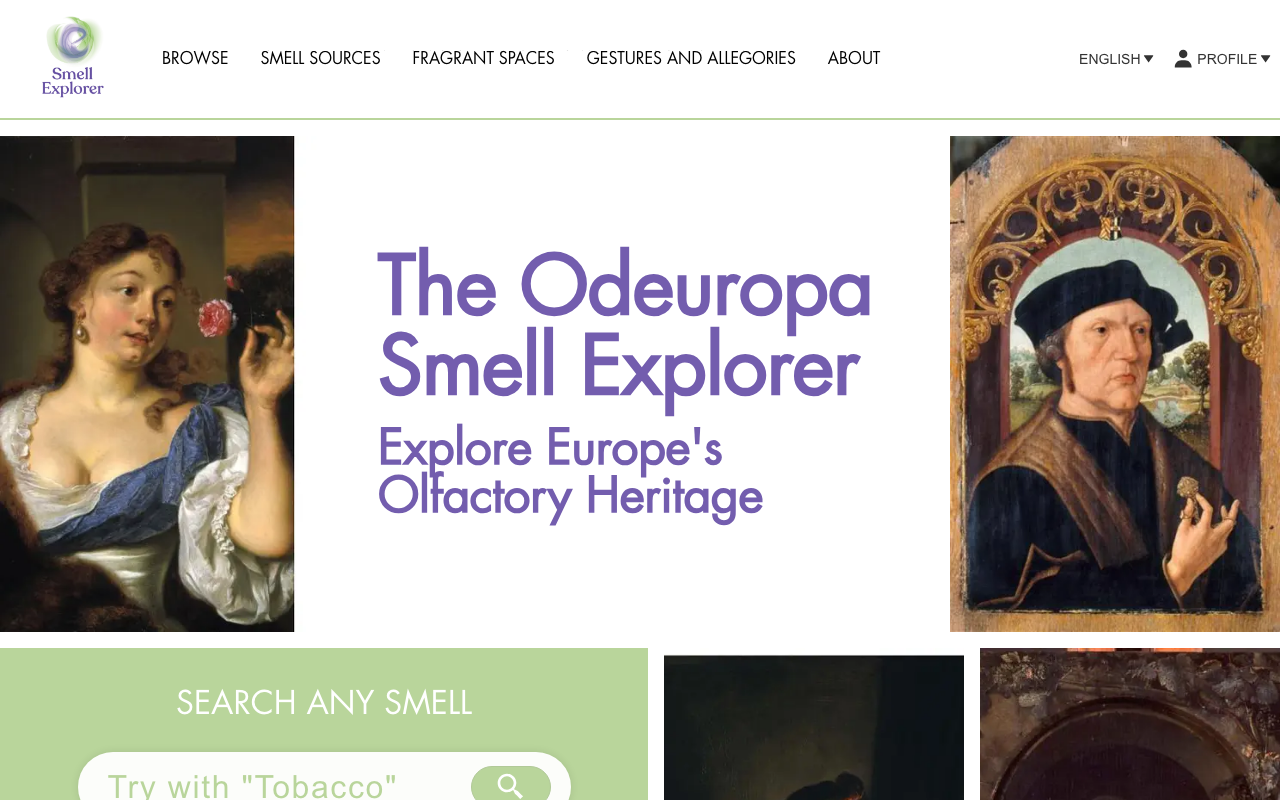
Introduction Odeuropa is a project that studies the history of scents in Europe, collecting and analyzing representations of scents depicted in paintings, literature, and other historical sources. This article introduces the implementation of a web application for visualizing scent data based on the SKOS (Simple Knowledge Organization System) vocabulary, utilizing Odeuropa’s SPARQL endpoint. https://odeuropa-seven.vercel.app/ja/ Project Overview Technology Stack Frontend: Next.js 15 (App Router) UI: Material-UI v5 Internationalization: next-intl Data Retrieval: SPARQL queries (Odeuropa SPARQL endpoint) Language: TypeScript Hosting: Static Site Generation (SSG) Main Features 1. Scent Search (/odeuropa-sources) This is the core feature of the application, allowing users to search and browse smell perception events collected by the Odeuropa project. ...