Three Pitfalls When Adapting a SPARQL Client to Apache Jena Fuseki
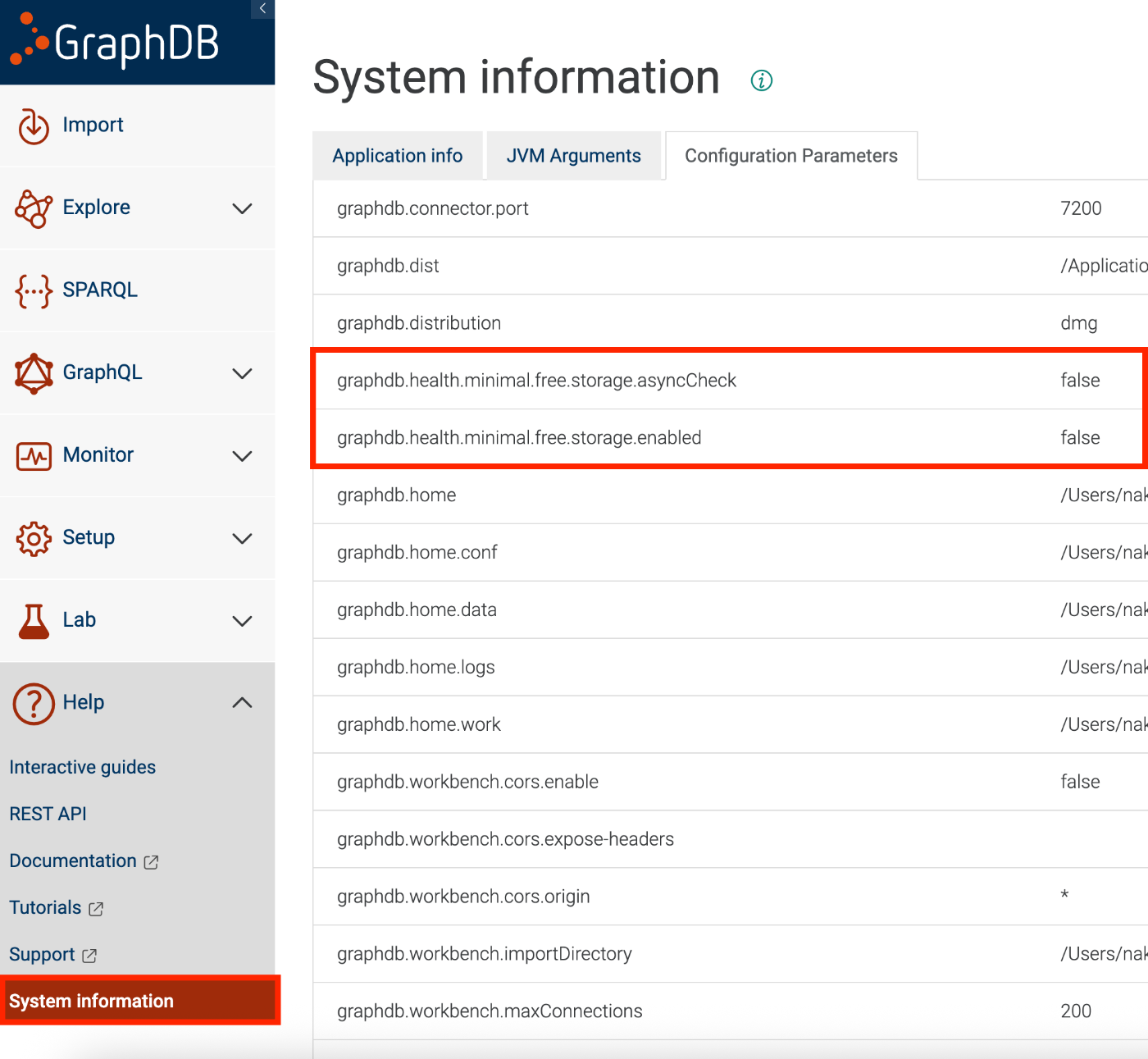
We adapted the SPARQL Explorer “Snorql”, originally built for Virtuoso and Dydra, to also work with Apache Jena Fuseki. Although SPARQL is a W3C standard, behavioral differences between endpoint implementations are surprisingly significant. This article documents the three issues we encountered during Fuseki support and their solutions. Development Environment We launched Fuseki with Docker and tested locally. # docker-compose.yml services: fuseki: image: stain/jena-fuseki container_name: fuseki ports: - "3030:3030" environment: - ADMIN_PASSWORD=admin - FUSEKI_DATASET_1=test volumes: - fuseki-data:/fuseki volumes: fuseki-data: docker compose up -d # Load test data curl -X POST 'http://localhost:3030/test/data' \ -H 'Content-Type: text/turtle' \ --data-binary @testdata.ttl 1. Different Response Format for DESCRIBE Symptom When sending a DESCRIBE query to Fuseki, results were not displayed on screen. JSON parse errors appeared in the console. ...