Fixing an Inference App Using Hugging Face Spaces and a YOLOv5 Model (Trained on NDL-DocL Dataset)
Overview In the following article, I introduced an inference app using Hugging Face Spaces and a YOLOv5 model trained on the NDL-DocL dataset.
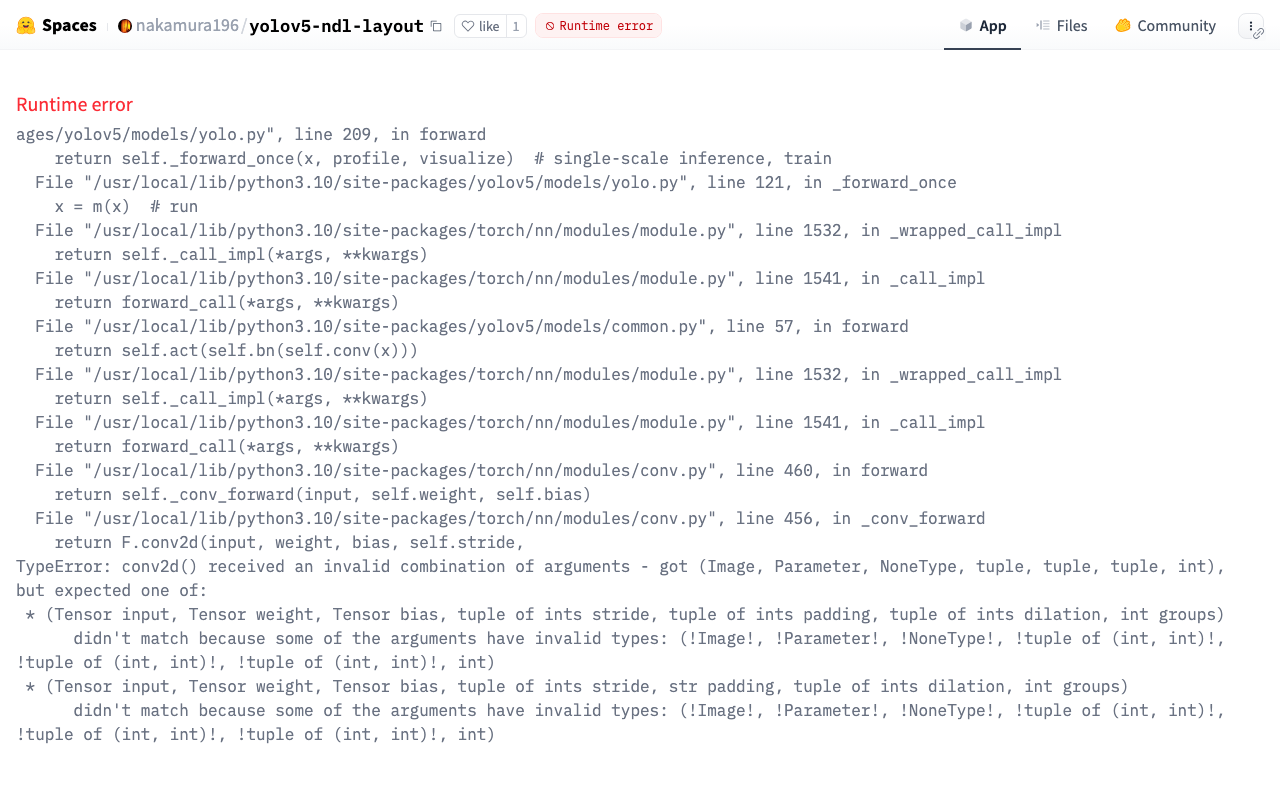
This app had stopped working, so I fixed it to make it operational again.
https://huggingface.co/spaces/nakamura196/yolov5-ndl-layout
Here are my notes on the changes made during this fix.
Changes The modified app.py is shown below.
import gradio as gr from PIL import Image import yolov5 import json model = yolov5.load("nakamura196/yolov5-ndl-layout") def yolo(im): results = model(im) # inference df = results.pandas().xyxy[0].to_json(orient="records") res = json.loads(df) im_with_boxes = results.render()[0] # results.render() returns a list of images # Convert the numpy array back to an image output_image = Image.fromarray(im_with_boxes) return [ output_image, res ] inputs = gr.Image(type='pil', label="Original Image") outputs = [ gr.Image(type="pil", label="Output Image"), gr.JSON() ] title = "YOLOv5 NDL-DocL Datasets" description = "YOLOv5 NDL-DocL Datasets Gradio demo for object detection. Upload an image or click an example image to use." article = "<p style='text-align: center'>YOLOv5 NDL-DocL Datasets is an object detection model trained on the <a href=\"https://github.com/ndl-lab/layout-dataset\">NDL-DocL Datasets</a>.</p>" examples = [ ['『源氏物語』(東京大学総合図書館所蔵).jpg'], ['『源氏物語』(京都大学所蔵).jpg'], ['『平家物語』(国文学研究資料館提供).jpg'] ] demo = gr.Interface(yolo, inputs, outputs, title=title, description=description, article=article, examples=examples) demo.launch(share=False) First, due to Gradio version upgrades, I changed gr.inputs.Image to gr.Image and similar updates.
...
May 20, 2024 · Updated: May 20, 2024 · 2 min · Nakamura