Mirador Repository with Vertical Text Support for the Text Overlay Plugin
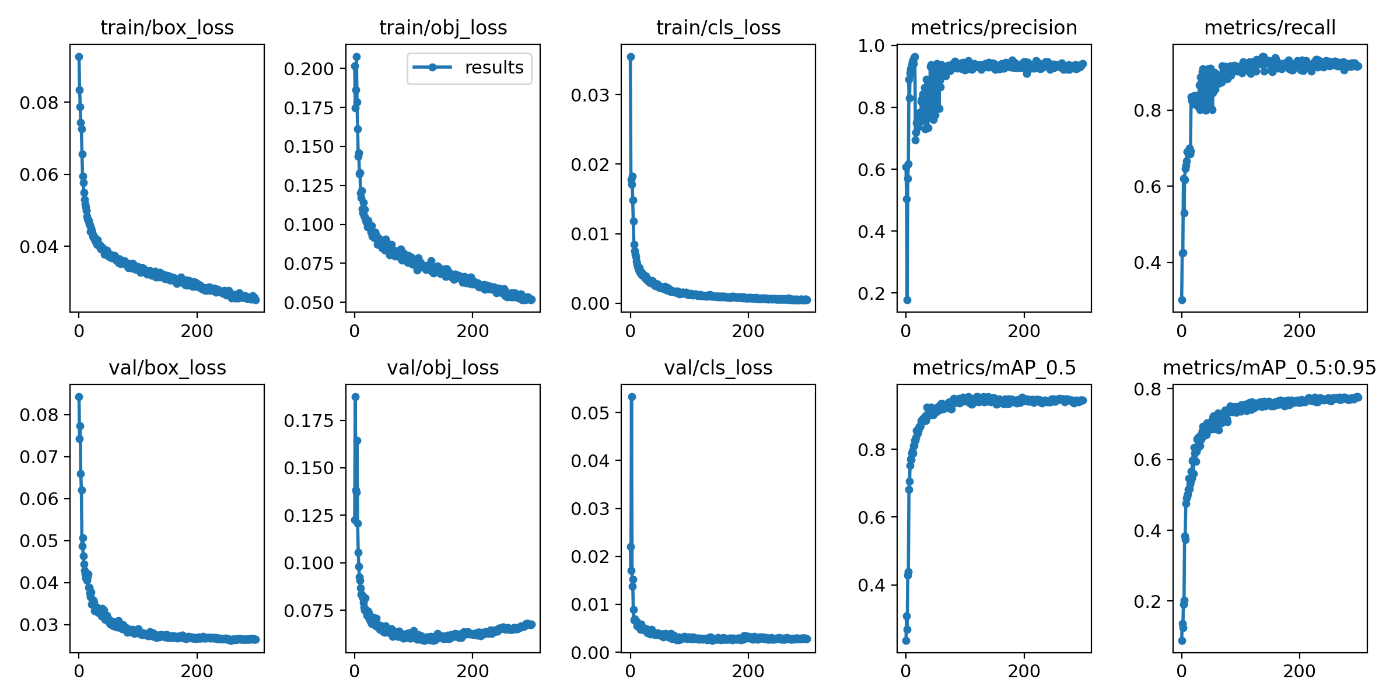
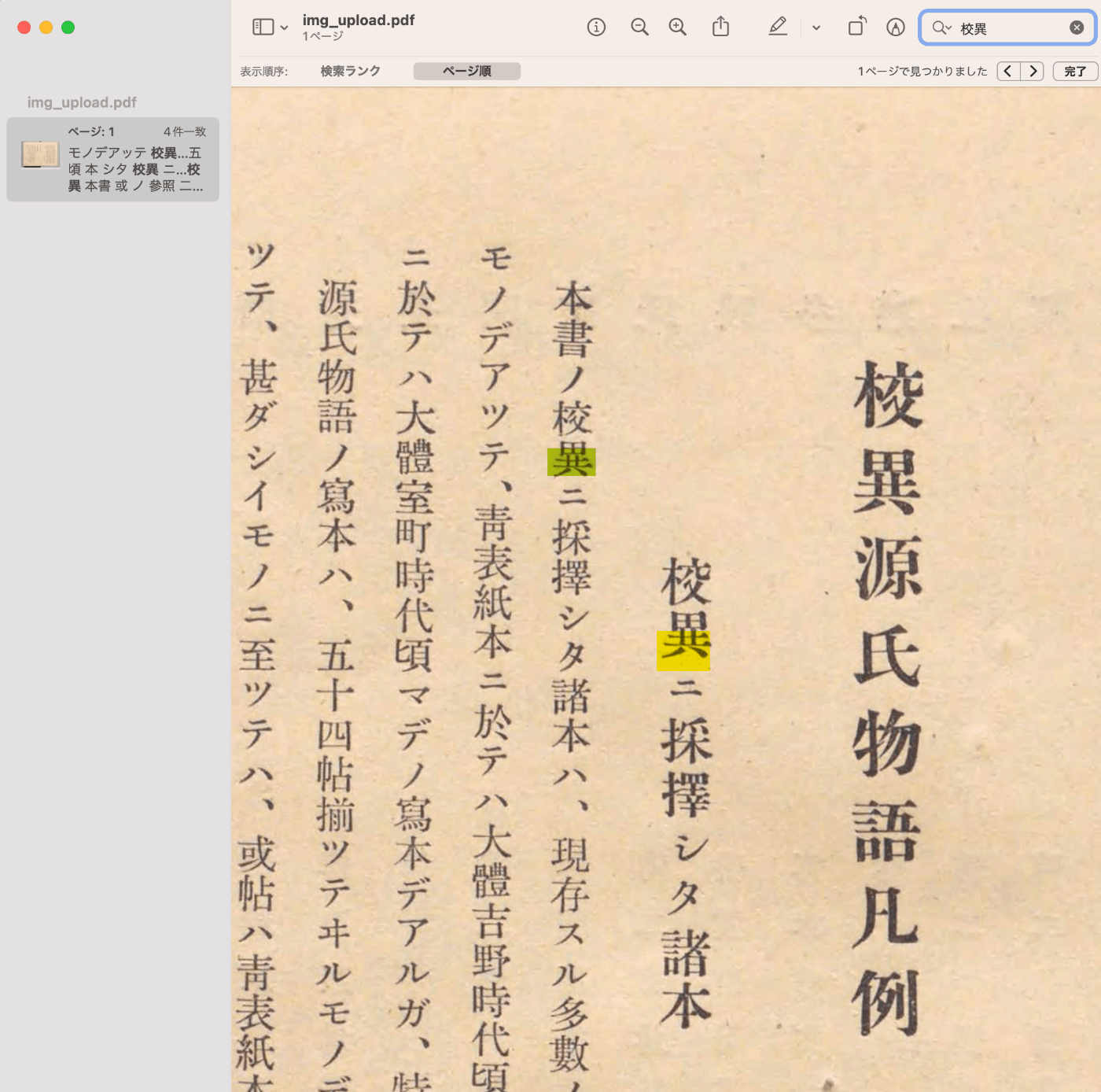
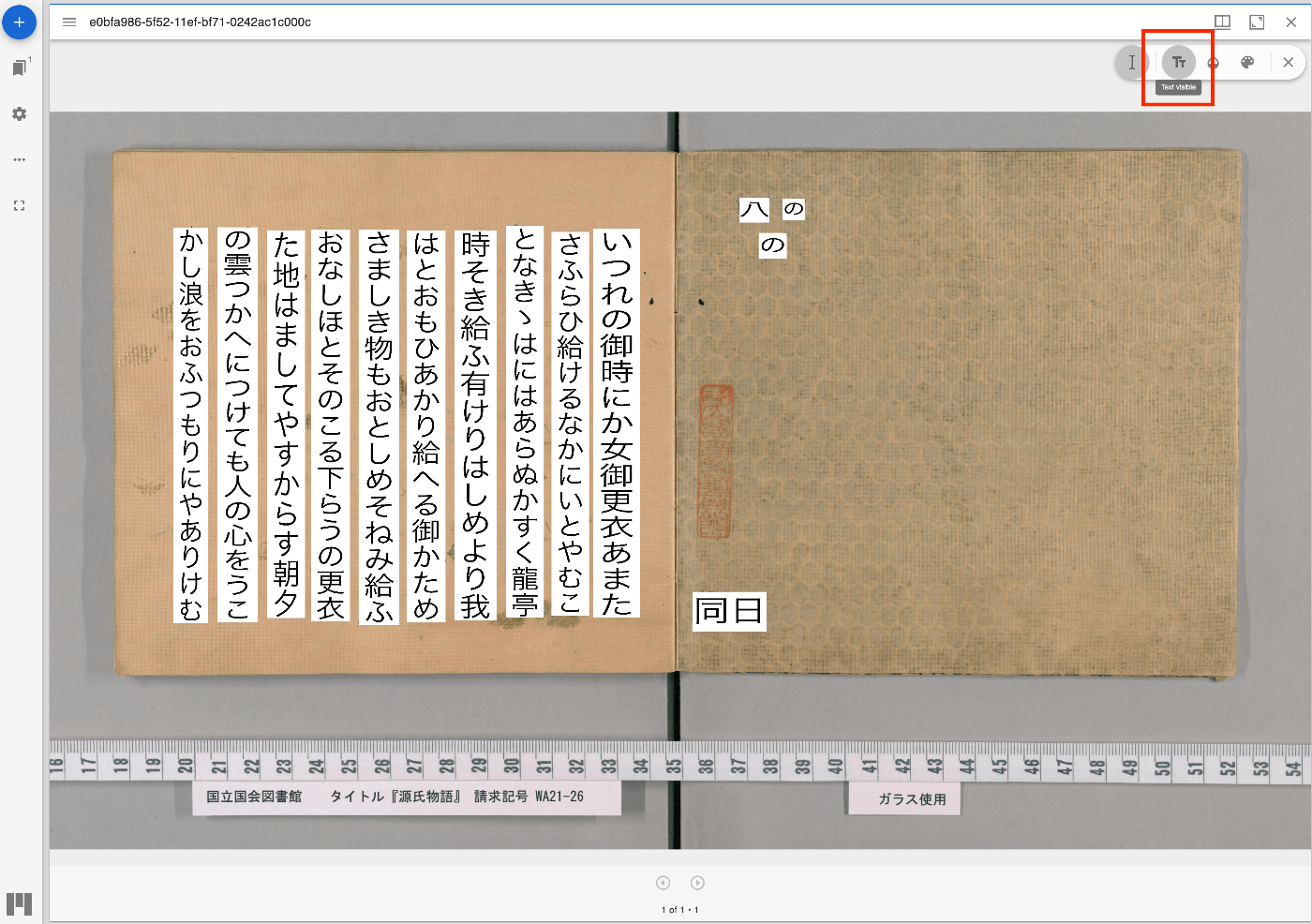
Overview I have updated the Mirador repository with the Text Overlay plugin that supports vertical text. https://github.com/nakamura196/mirador-integration-textoverlay References The original Text Overlay plugin repository is below. https://github.com/dbmdz/mirador-textoverlay Demo You can check the behavior on the following page. https://nakamura196.github.io/mirador-integration-textoverlay/ Press the “Text visible” button in the upper right to display the text. If it remains in a loading state, try reloading the page. References The Text Overlay plugin was added to Mirador 3 using the method introduced in the following article. ...