Output Content of IIIF Manifests (Version 2) from the Omeka S IIIF Server
Overview IIIF Server is a module for delivering IIIF manifests from Omeka S.
https://github.com/Daniel-KM/Omeka-S-module-IiifServer
In this article, we examine the output content of these IIIF manifests (specifically, IIIF Presentation API version 2).
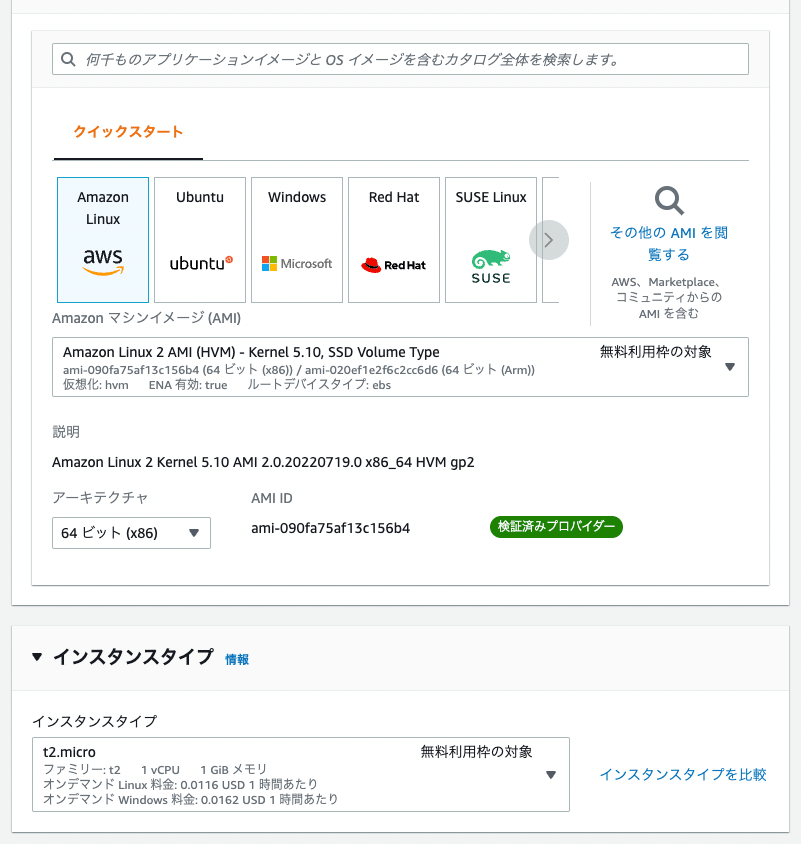
Example The following is an example of a IIIF manifest for an item with ID test-111 on an Omeka S instance published at https://shared.ldas.jp/omeka-s.
{ "@context": "http://iiif.io/api/presentation/2/context.json", "@id": "https://shared.ldas.jp/omeka-s/iiif/test-111/manifest", "@type": "sc:Manifest", "label": "Sample Item", "thumbnail": { "@id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/kunshujou/A00_6010/001/001_0001.tif/full/!200,200/0/default.jpg", "@type": "dctypes:Image", "format": "image/jpeg", "width": 200, "height": 200 }, "license": "https://shared.ldas.jp/omeka-s/s/test/page/reuse", "attribution": "サンプル機関", "related": { "@id": "https://shared.ldas.jp/omeka-s", "format": "text/html" }, "seeAlso": { "@id": "https://shared.ldas.jp/omeka-s/api/items/1270", "format": "application/ld+json" }, "metadata": [ { "label": "Title", "value": "Sample Item" }, { "label": "Identifier", "value": "test-111" } ], "sequences": [ { "@id": "https://shared.ldas.jp/omeka-s/iiif/test-111/sequence/normal", "@type": "sc:Sequence", "label": "Current Page Order", "viewingDirection": "left-to-right", "canvases": [ { "@id": "https://shared.ldas.jp/omeka-s/iiif/test-111/canvas/p1", "@type": "sc:Canvas", "label": "1", "thumbnail": { "@id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/kunshujou/A00_6010/001/001_0001.tif/full/!200,200/0/default.jpg", "@type": "dctypes:Image", "format": "image/jpeg", "width": 200, "height": 200 }, "width": 6401, "height": 4810, "images": [ { "@id": "https://shared.ldas.jp/omeka-s/iiif/test-111/annotation/p0001-image", "@type": "oa:Annotation", "motivation": "sc:painting", "resource": { "@id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/kunshujou/A00_6010/001/001_0001.tif/full/full/0/default.jpg", "@type": "dctypes:Image", "format": "image/jpeg", "width": 6401, "height": 4810, "service": { "@context": "http://iiif.io/api/image/2/context.json", "@id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/kunshujou/A00_6010/001/001_0001.tif", "profile": "http://iiif.io/api/image/2/level1.json" } }, "on": "https://shared.ldas.jp/omeka-s/iiif/test-111/canvas/p1" } ] }, { "@id": "https://shared.ldas.jp/omeka-s/iiif/test-111/canvas/p2", "@type": "sc:Canvas", "label": "2枚目", "thumbnail": { "@id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/kunshujou/A00_6010/001/001_0002.tif/full/!200,200/0/default.jpg", "@type": "dctypes:Image", "format": "image/jpeg", "width": 200, "height": 200 }, "width": 6401, "height": 4810, "images": [ { "@id": "https://shared.ldas.jp/omeka-s/iiif/test-111/annotation/p0002-image", "@type": "oa:Annotation", "motivation": "sc:painting", "resource": { "@id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/kunshujou/A00_6010/001/001_0002.tif/full/full/0/default.jpg", "@type": "dctypes:Image", "format": "image/jpeg", "width": 6401, "height": 4810, "service": { "@context": "http://iiif.io/api/image/2/context.json", "@id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/kunshujou/A00_6010/001/001_0002.tif", "profile": "http://iiif.io/api/image/2/level1.json" } }, "on": "https://shared.ldas.jp/omeka-s/iiif/test-111/canvas/p2" } ], "metadata": [ { "label": "Title", "value": "2枚目" } ] } ] } ] } Below, I will explain each type.
...
September 1, 2022 · Updated: September 1, 2022 · 3 min · Nakamura
![[Omeka S] Created a Foundation S Theme That Works Around the Japanese Search Bug](/images/articles/42f725b56dac64.png)
![[Omeka S] Handling Bulk Import Bugs (Including Installation from Source Code)](https://storage.googleapis.com/zenn-user-upload/ed7f11a15317-20220821.png)
![[Memo] How to Use Virtuoso](https://storage.googleapis.com/zenn-user-upload/a3b1702b65fc-20220819.png)
![[RDF] Configuring URI Access to Redirect to the Snorql Interface](/images/articles/3243962c5e57d0.png)