OCR Pipeline Structure
An OCR pipeline using ONNX Runtime on iOS generally follows these steps:
- Text region detection on the full image (Detection)
- Character recognition for each detected region (Recognition)
- Reading order estimation and text assembly
Detection runs once on the entire image. Recognition, however, runs once per detected region. When the number of regions is large, recognition dominates the total processing time.
The Problem with Sequential Processing
Running recognition in a simple for loop means processing time scales linearly with the number of regions.
for det in detections {
let rect = CGRect(x: max(0, det.box[0]), y: max(0, det.box[1]),
width: max(1, det.box[2] - det.box[0]),
height: max(1, det.box[3] - det.box[1]))
if let cropped = image.cropping(to: rect) {
_ = try recognizer.recognize(image: cropped)
}
}
For an image with 98 detected regions, at roughly 80ms per region, the total comes to about 8 seconds.
Parallelizing with withThrowingTaskGroup
Swift Concurrency’s withThrowingTaskGroup allows running recognition for each region concurrently.
let results = try await withThrowingTaskGroup(of: (Int, String).self) { group in
for i in 0..<detections.count {
let box = detections[i].box
let cropRect = CGRect(
x: max(0, box[0]),
y: max(0, box[1]),
width: max(1, box[2] - box[0]),
height: max(1, box[3] - box[1])
)
guard let cropped = image.cropping(to: cropRect) else { continue }
group.addTask {
let text = try recognizer.recognize(image: cropped)
return (i, text)
}
}
var texts: [(Int, String)] = []
for try await result in group {
texts.append(result)
}
return texts
}
for (i, text) in results {
recognized[i].text = text
}
Each task returns its result with the original index, so ordering is preserved regardless of completion order.
Benchmark Results
The following measurements compare sequential and parallel recognition on the iOS Simulator.
Classical Text (Genji Monogatari, 6642x4990px, 21 regions)
Source: University of Tokyo Digital Archive — Genji Monogatari
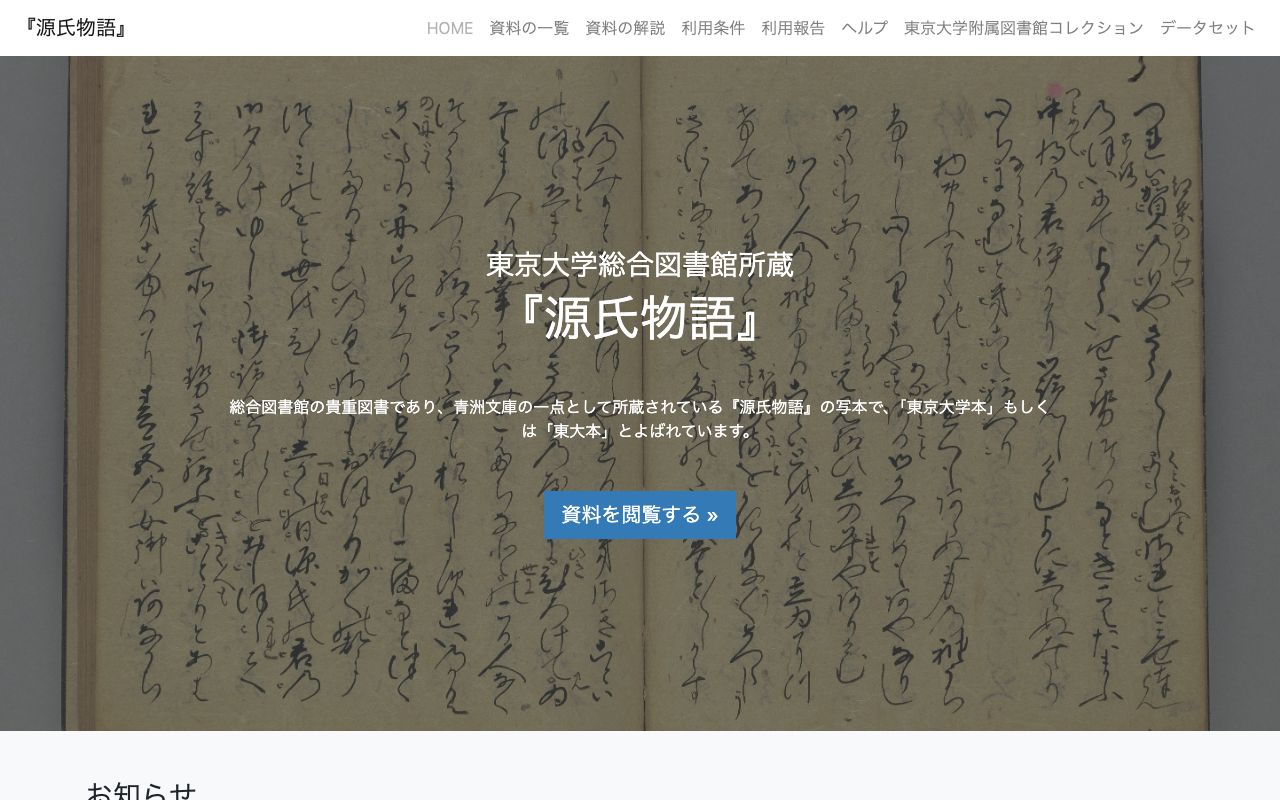
| Method | Time |
|---|---|
| Sequential | 4.55s |
| Parallel | 3.24s |
| Speedup | 1.4x |
Modern Printed Text (NDL Digital Collection, 6890x4706px, 98 regions)
Source: National Diet Library Digital Collections
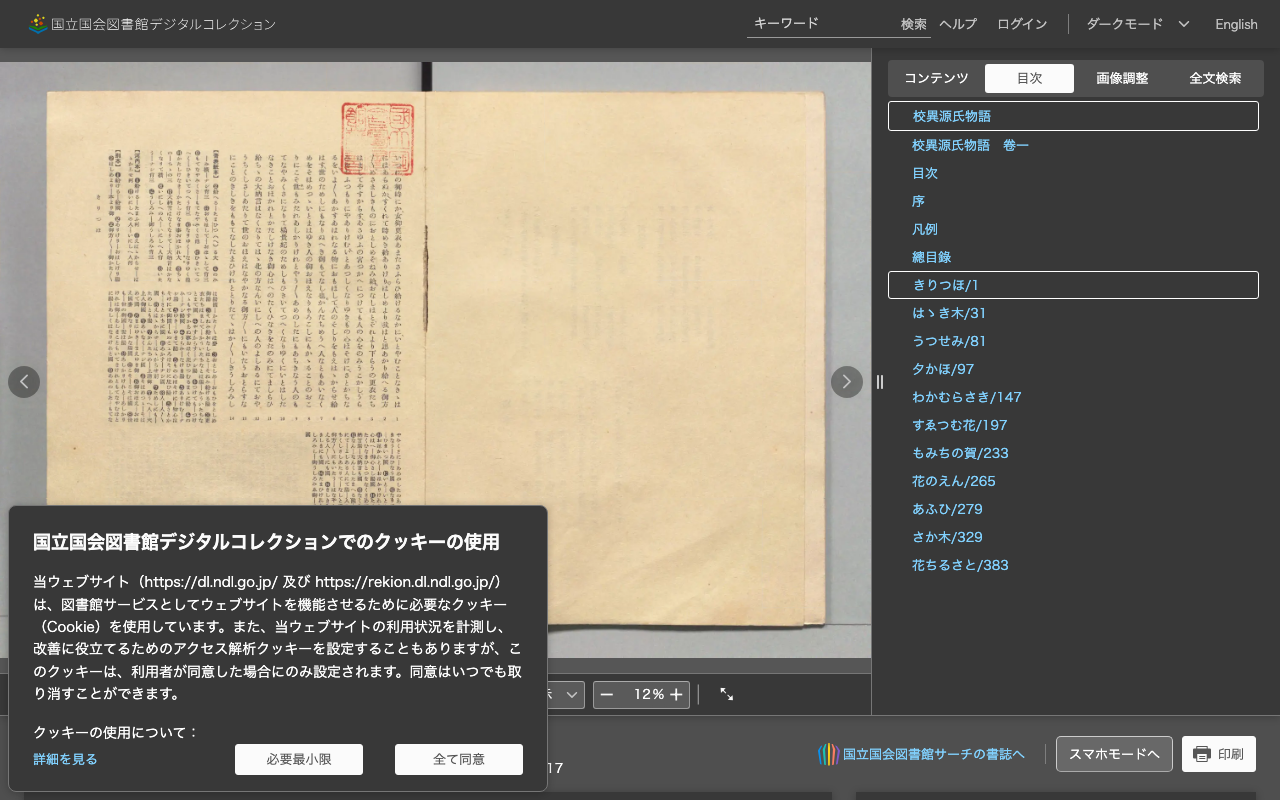
| Method | Time |
|---|---|
| Sequential | 7.59s |
| Parallel | 1.13s |
| Speedup | 6.7x |
Why the Speedup Varies
The difference in speedup between 21 regions and 98 regions comes down to concurrency overhead.
Swift Concurrency’s Cooperative Thread Pool automatically limits the number of concurrent threads to the CPU core count. ONNX Runtime sessions use internal locking, so when multiple tasks attempt inference simultaneously, lock contention occurs.
With fewer regions (21), the overhead from lock contention is proportionally larger, limiting the speedup to 1.4x. With more regions (98), the pipeline can saturate the available cores effectively, yielding a 6.7x speedup.
Because withThrowingTaskGroup relies on the Swift runtime to manage concurrency, there is no risk of thread explosion.
Note
All measurements above were taken on the iOS Simulator. Performance on a physical device may differ.