
I Created a Program to Extract Differences Between Two Texts
Overview I created a program to extract differences between two texts. You can use it from the following Google Colab notebook. https://colab.research.google.com/github/nakamura196/ndl_ocr/blob/main/校異情報の生成.ipynb A well-known service for this purpose is “difff”, but this time I implemented it using Python. https://difff.jp/ For calculating the differences between texts, I used difflib.SequenceMatcher. https://docs.python.org/ja/3/library/difflib.html Usage You can choose between two output formats: HTML files and TEI files. HTML Here is an example of the HTML file output. ...
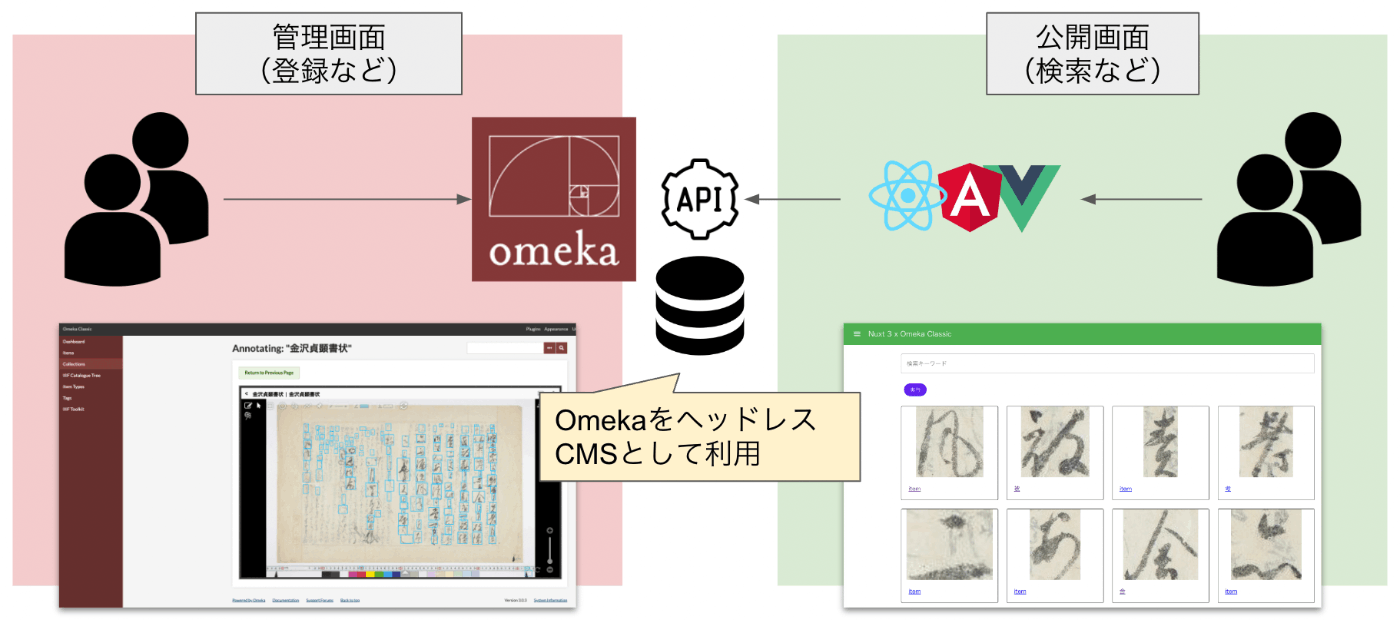

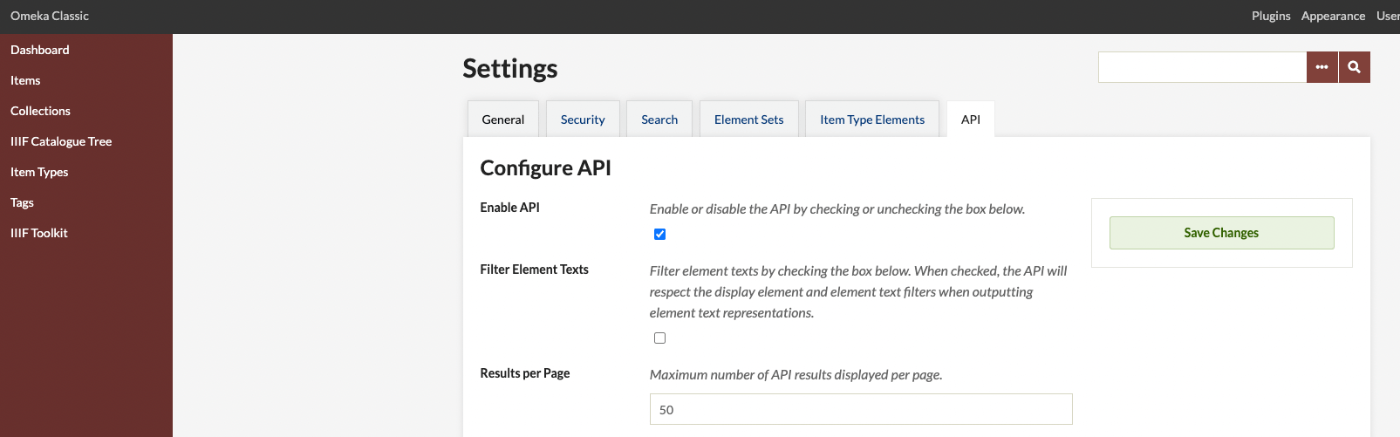


![[Omeka S Module] How to Disable Image API in the IIIF Server Module](https://storage.googleapis.com/zenn-user-upload/a4d871d0334c-20220527.png)
![[Omeka S Theme] Partial Mapping Module Support for Bootstrap 5 Theme](https://storage.googleapis.com/zenn-user-upload/f0afdf63282c-20220526.png)
![[Omeka S] How to Use the "IIIF Viewers" Module for Multiple IIIF-Compatible Viewers](https://storage.googleapis.com/zenn-user-upload/9ed8018846f2-20220526.png)
