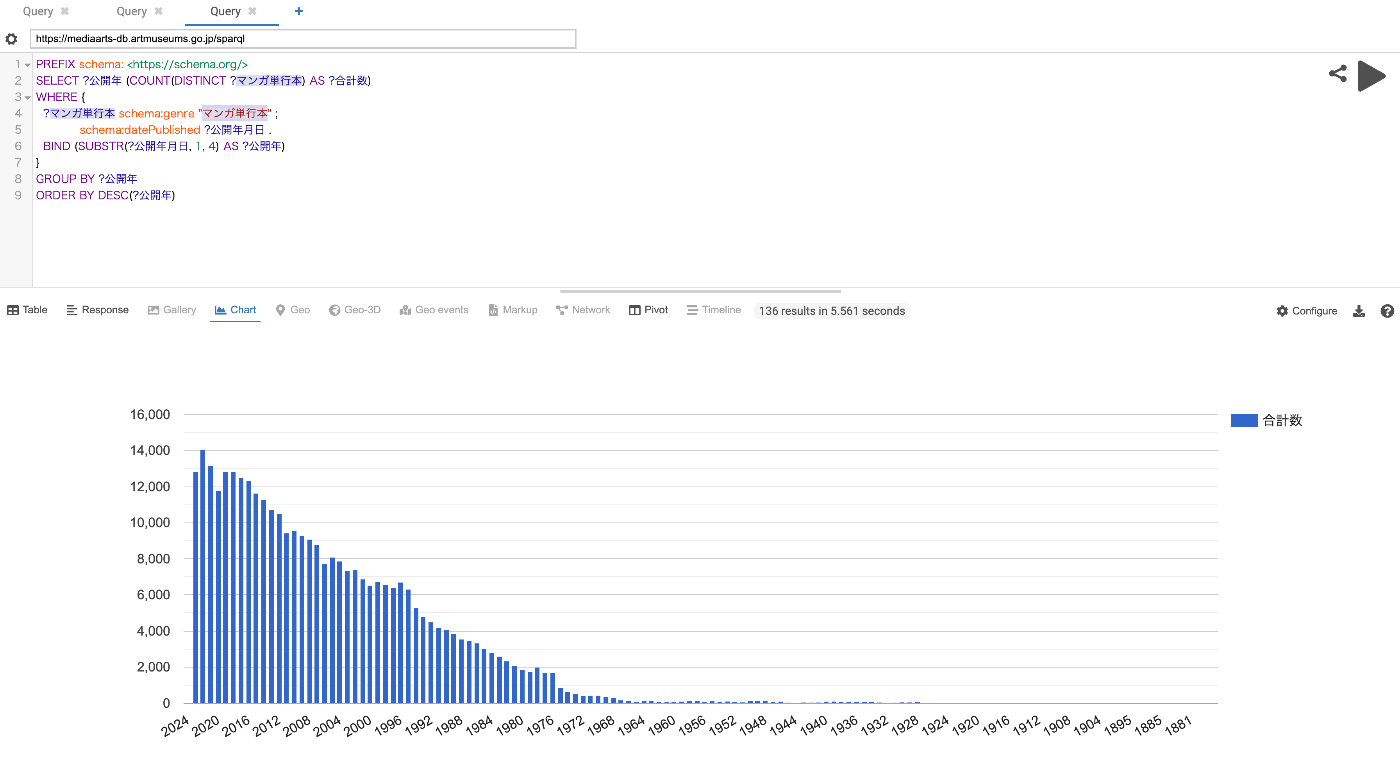
Differences Between Omeka Classic and Omeka S
I am sharing a response from ChatGPT4 about the differences between Omeka Classic and Omeka S. I hope it serves as a useful reference.
Omeka and Omeka S are open-source web publishing platforms for building digital collections and exhibitions. Both are widely used by academic institutions, libraries, museums, archives, educators, and cultural heritage organizations. However, Omeka and Omeka S differ in their design and intended use.
Omeka (Classic) Target audience: Best suited for individuals and small-scale projects. Suitable for school projects, personal research, and small archival collections. Features: Easy to install and provides an intuitive admin interface. Focused on individual websites and projects, specializing in single site management and exhibition creation. Use cases: Best for exhibiting small digital collections and educational projects. Customization is possible through plugins and themes, but it is not suited for integrated management of multiple projects or collections. Omeka S Target audience: Best suited for organizations with multiple projects and collections, such as universities, libraries, and museums. Features: Omeka S is designed to enable the creation and management of multiple sites. With a single installation, it allows sharing, reusing, and linking resources across different projects and collections. Use cases: Best for large institutions that have multiple digital collections and exhibitions and want to manage them in an integrated manner. It provides more advanced features including API support, advanced search functionality, and Linked Open Data support. Key Differences Intended use: Omeka Classic is designed for small-scale projects and individual users, while Omeka S is designed for organizations and institutions with multiple projects and sites. Functionality: Omeka S provides more advanced features such as multi-site management, Linked Open Data support, and data access via API. Extensibility and interoperability: Omeka S aims for broader data integration and interoperability by sharing items across collections. The choice depends on the scale of the project, its purpose, and the type of data being managed. Omeka Classic is suitable for small-scale projects and personal use, while Omeka S is suitable for organizations handling multiple projects and large datasets.
...
February 26, 2024 · Updated: February 26, 2024 · 2 min · Nakamura