Customizing the LEAF Writer Editor Toolbar
Overview LEAF Writer provides buttons at the top of the screen to support tag insertion. This article introduces how to customize them.
As a result, I added functionality to insert <app><lem>aaa</lem><rdg>bbb</rdg></app>.
https://youtu.be/XMnRP7s2atw
Editing Edit the following file:
packages/cwrc-leafwriter/src/components/editorToolbar/index.tsx
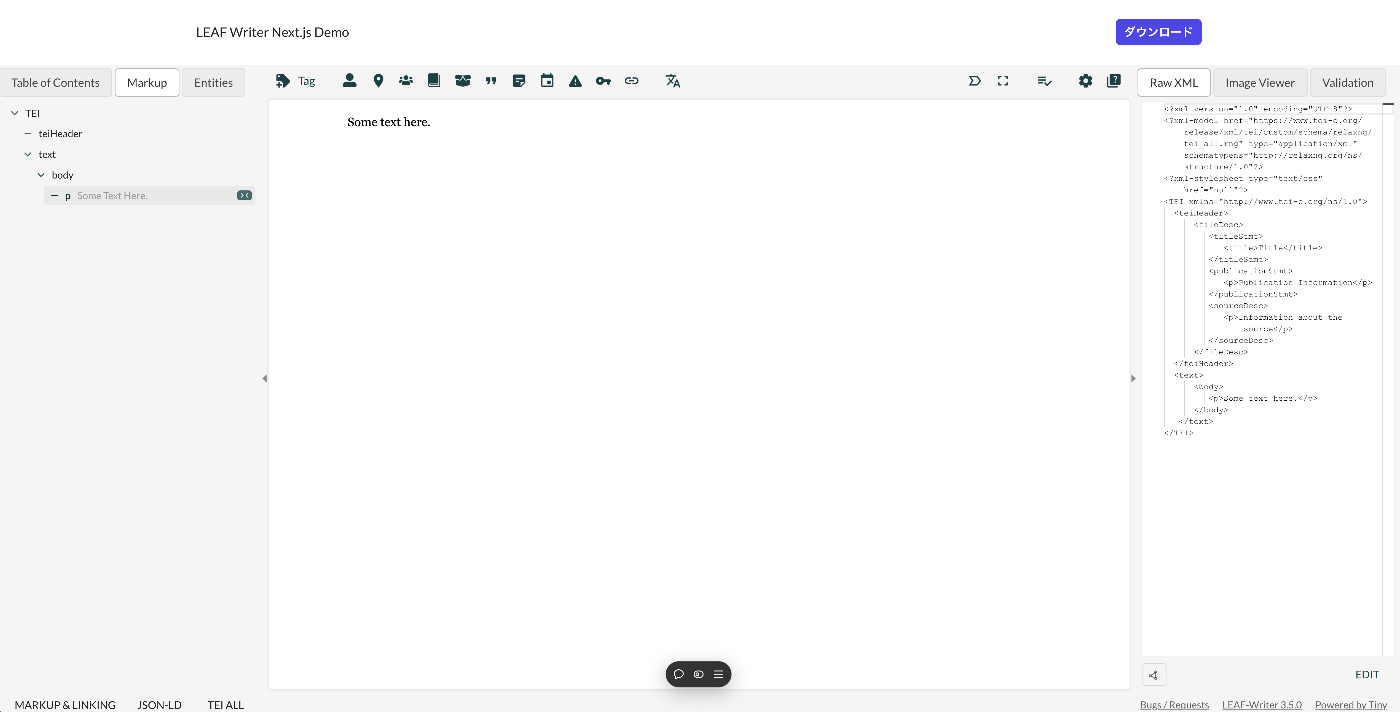
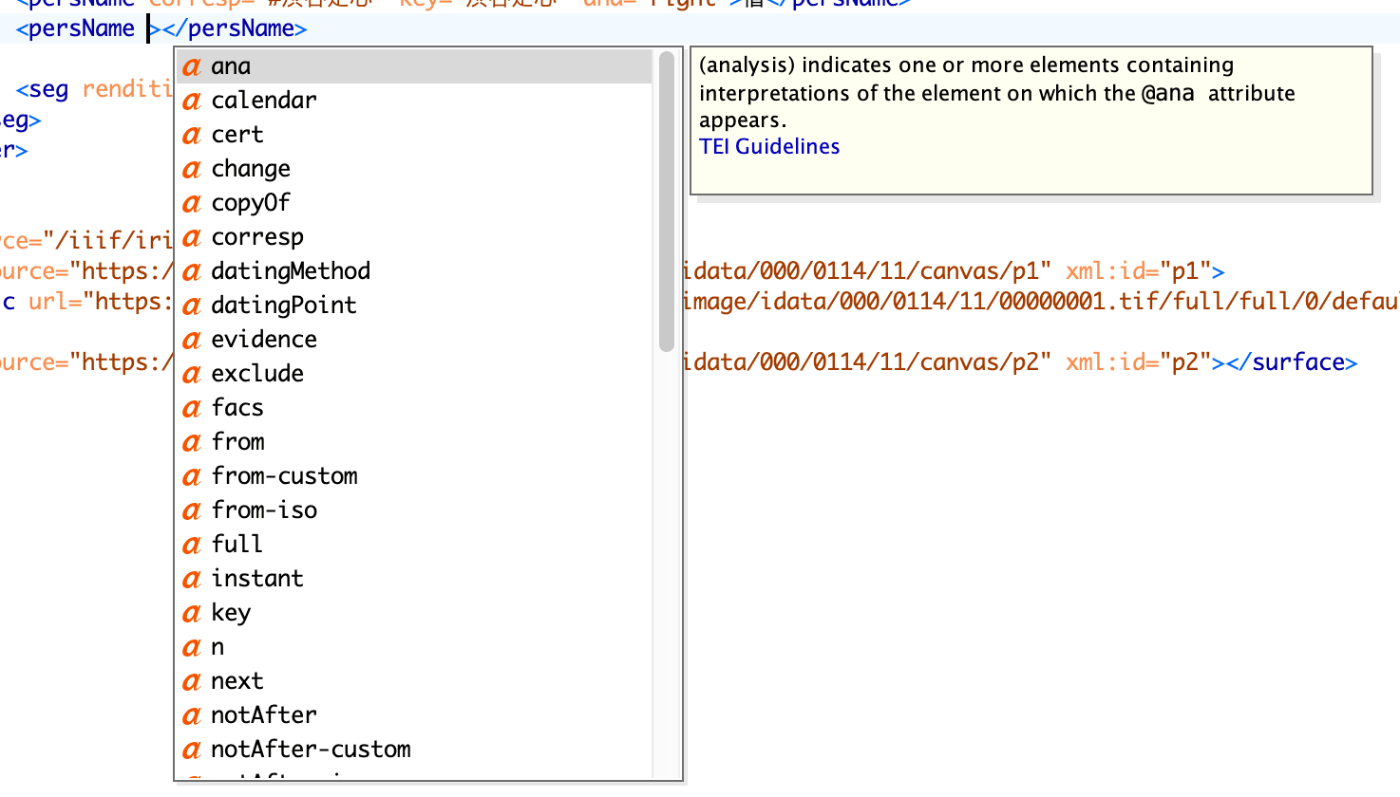
Features for supporting tags such as person names and place names are configured as follows. For example, the description for organization has been commented out:
... const items: (MenuItem | Item)[] = [ { group: 'action', hide: isReadonly, icon: 'insertTag', onClick: () => { if (!container.current) return; const rect = container.current.getBoundingClientRect(); const posX = rect.left; const posY = rect.top + 34; showContextMenu({ // anchorEl: container.current, eventSource: 'ribbon', position: { posX, posY }, useSelection: true, }); }, title: 'Tag', tooltip: 'Add Tag', type: 'button', }, { group: 'action', type: 'divider', hide: isReadonly }, { color: entity.person.color.main, group: 'action', disabled: !isSupported('person'), hide: isReadonly, icon: entity.person.icon, onClick: () => window.writer.tagger.addEntityDialog('person'), title: 'Tag Person', type: 'iconButton', }, { color: entity.place.color.main, group: 'action', disabled: !isSupported('place'), hide: isReadonly, icon: entity.place.icon, onClick: () => window.writer.tagger.addEntityDialog('place'), title: 'Tag Place', type: 'iconButton', }, /* { color: entity.organization.color.main, group: 'action', disabled: !isSupported('organization'), hide: isReadonly, icon: entity.organization.icon, onClick: () => window.writer.tagger.addEntityDialog('organization'), title: 'Tag Organization', type: 'iconButton', }, ... As a result, the choices are limited as follows:
...
October 31, 2024 · Updated: October 31, 2024 · 4 min · Nakamura